
2020
10-08
10-08
Python使用shutil模块实现文件拷贝
主要作用与拷贝文件用的。1.shutil.copyfileobj(文件1,文件2):将文件1的数据覆盖copy给文件2。importshutilf1=open("1.txt",encoding="utf-8")f2=open("2.txt","w",encoding="utf-8")shutil.copyfileobj(f1,f2)2.shutil.copyfile(文件1,文件2):不用打开文件,直接用文件名进行覆盖copy。importshutilshutil.copyfile("1.txt","3.txt")3.shutil.copymode(文件1,文件2):之拷贝权限,内容组,用户,均不变defcopymode(sr...
继续阅读 >
 安装request库以火车的站站查询为例的post和get方法的接口测试使用pytest测试接口1、requests的请求机制1、安装request库2、以火车的站站查询为例的post和get请求方法2.1get请求:两种传参方式1、_url=“网址+参数”=“网址?key1=value1&key2=value2”response1=request.get(url=_url)2、字典拼接_params={“key1”:“value1”,“key2”:“value2”,}response2=requests.get(url=“网址”,params=_params)i...
安装request库以火车的站站查询为例的post和get方法的接口测试使用pytest测试接口1、requests的请求机制1、安装request库2、以火车的站站查询为例的post和get请求方法2.1get请求:两种传参方式1、_url=“网址+参数”=“网址?key1=value1&key2=value2”response1=request.get(url=_url)2、字典拼接_params={“key1”:“value1”,“key2”:“value2”,}response2=requests.get(url=“网址”,params=_params)i...
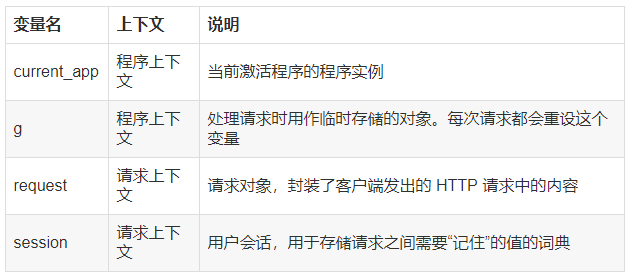 Flask框架难学吗?它和Django哪个更容易一些,这可能是学Pythonweb开发的同学经常问的问题,下面来说一下flask框架。Flask是python的web框架,最大的特征是轻便,让开发者自由灵活的兼容要开发的feature。为什么要从Flask开始学习web框架?1.python语言的灵活性给予了Flask同样的特征;2.无论是用户画像还是产品推荐,python相比其他语言都有极大的优势;3.Flask轻便,容易上手,试错成本低。所以,从搭建一个轻便的博客出发,既...
Flask框架难学吗?它和Django哪个更容易一些,这可能是学Pythonweb开发的同学经常问的问题,下面来说一下flask框架。Flask是python的web框架,最大的特征是轻便,让开发者自由灵活的兼容要开发的feature。为什么要从Flask开始学习web框架?1.python语言的灵活性给予了Flask同样的特征;2.无论是用户画像还是产品推荐,python相比其他语言都有极大的优势;3.Flask轻便,容易上手,试错成本低。所以,从搭建一个轻便的博客出发,既...
 使用ES做搜索引擎拉取数据的时候,如果数据量太大,通过传统的from+size的方式并不能获取所有的数据(默认最大记录数10000),因为随着页数的增加,会消耗大量的内存,导致ES集群不稳定。因此延伸出了scroll,search_after等翻页方式。一、from+size浅分页"浅"分页可以理解为简单意义上的分页。它的原理很简单,就是查询前20条数据,然后截断前10条,只返回10-20的数据。这样其实白白浪费了前10条的查询。GETtest/_search{"...
使用ES做搜索引擎拉取数据的时候,如果数据量太大,通过传统的from+size的方式并不能获取所有的数据(默认最大记录数10000),因为随着页数的增加,会消耗大量的内存,导致ES集群不稳定。因此延伸出了scroll,search_after等翻页方式。一、from+size浅分页"浅"分页可以理解为简单意义上的分页。它的原理很简单,就是查询前20条数据,然后截断前10条,只返回10-20的数据。这样其实白白浪费了前10条的查询。GETtest/_search{"...
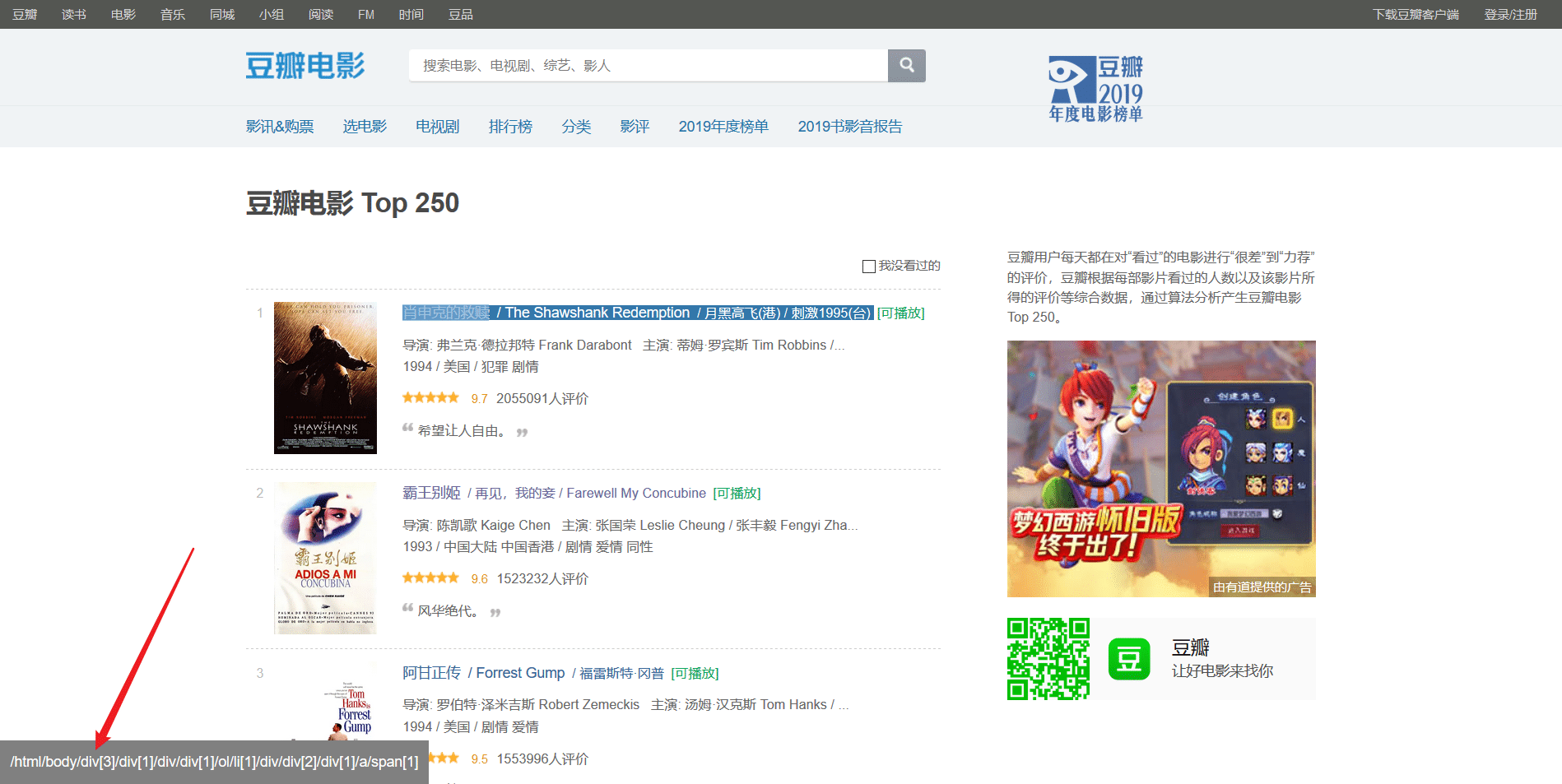 豆瓣电影排行榜前250分为10页,第一页的url为https://movie.douban.com/top250,但实际上应该是https://movie.douban.com/top250?start=0后面的参数0表示从第几个开始,如0表示从第一(肖申克的救赎)到第二十五(触不可及),https://movie.douban.com/top250?start=25表示从第二十六(蝙蝠侠:黑暗骑士)到第五十名(死亡诗社)。等等,所以可以用一个步长为25的range的for循环参数复制代码代码如下:foriinrange(0,...
豆瓣电影排行榜前250分为10页,第一页的url为https://movie.douban.com/top250,但实际上应该是https://movie.douban.com/top250?start=0后面的参数0表示从第几个开始,如0表示从第一(肖申克的救赎)到第二十五(触不可及),https://movie.douban.com/top250?start=25表示从第二十六(蝙蝠侠:黑暗骑士)到第五十名(死亡诗社)。等等,所以可以用一个步长为25的range的for循环参数复制代码代码如下:foriinrange(0,...
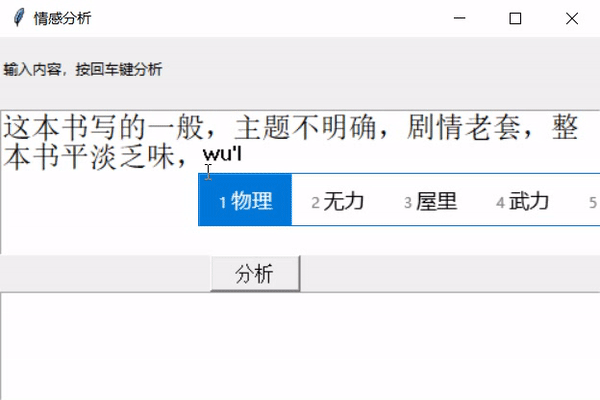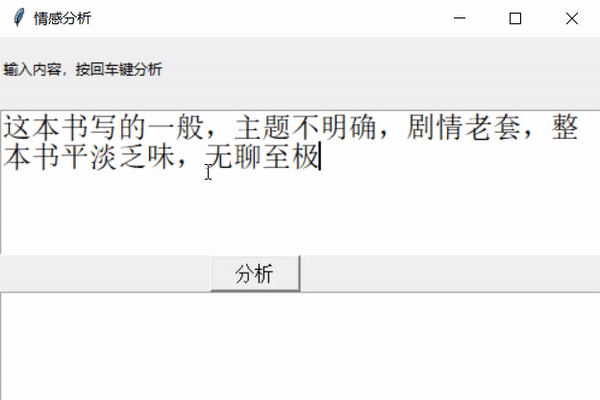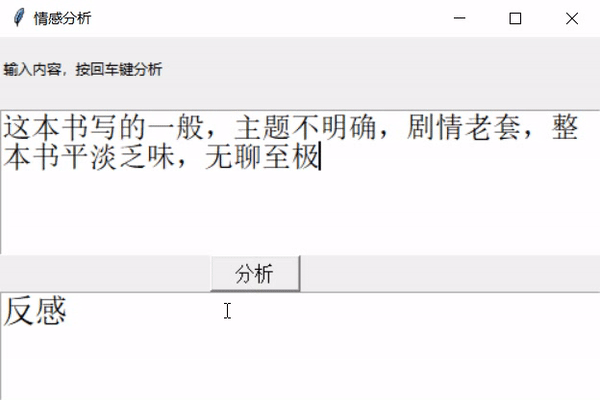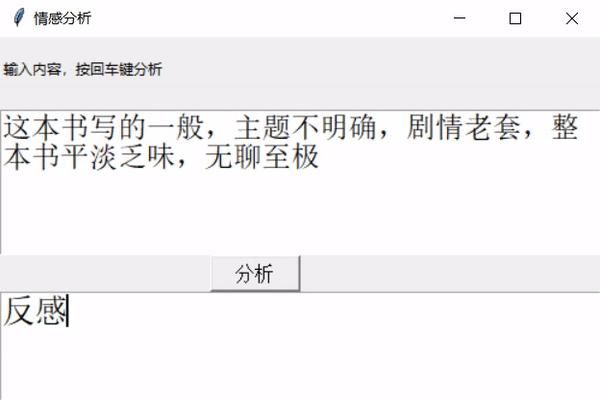 python实现情感分析(Word2Vec)**前几天跟着老师做了几个项目,老师写的时候劈里啪啦一顿敲,写了个啥咱也布吉岛,线下自己就瞎琢磨,终于实现了一个最简单的项目。输入文本,然后分析情感,判断出是好感还是反感。看最终结果:↓↓↓↓↓↓12大概就是这样,接下来实现一下。实现步骤加载数据,预处理数据就是正反两类,保存在neg.xls和pos.xls文件中,数据内容类似购物网站的评论,分别有一万多个好评和一万多个差评,通过对它...
python实现情感分析(Word2Vec)**前几天跟着老师做了几个项目,老师写的时候劈里啪啦一顿敲,写了个啥咱也布吉岛,线下自己就瞎琢磨,终于实现了一个最简单的项目。输入文本,然后分析情感,判断出是好感还是反感。看最终结果:↓↓↓↓↓↓12大概就是这样,接下来实现一下。实现步骤加载数据,预处理数据就是正反两类,保存在neg.xls和pos.xls文件中,数据内容类似购物网站的评论,分别有一万多个好评和一万多个差评,通过对它...