
2020
10-08
10-08
Python pytesseract验证码识别库用法解析
环境centos7python3pytesseract只是tesseract-ocr的一种实现接口。所以要先安装tesseract-ocr(大名鼎鼎的开源的OCR识别引擎)。依赖安装yuminstall-yautomakeautoconflibtoolgccgcc-c++yuminstall-ylibpng-devellibjpeg-devellibtiff-develgiflib-devel安装依赖的leptonica库wgethttp://www.leptonica.com/source/leptonica-1.72.tar.gztar-xzvfleptonica-1.72.tar.gzcdleptonica-1.72./configuremake&&make...
继续阅读 >
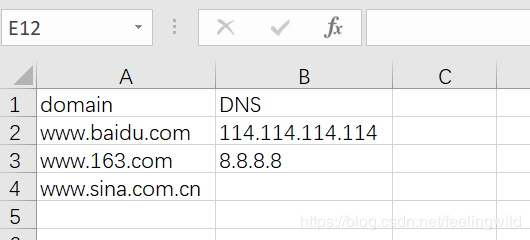 利用EXCLE生成CSV文档,批量处理nslookup解析。并保存为CSV文档,方便进行查看:输入文档格式:data\domain.csv最终输出文档情况:data\nlookup.csv代码:#coding=gbkimportsubprocessimportcsvdefget_nslookup(domain,dns):res=subprocess.Popen("nslookup{0}{1}".format(domain,dns),stdin=subprocess.PIPE,stdout=subprocess.PIPE).communicate()[0]response=res.decode("gbk")res_list=r...
利用EXCLE生成CSV文档,批量处理nslookup解析。并保存为CSV文档,方便进行查看:输入文档格式:data\domain.csv最终输出文档情况:data\nlookup.csv代码:#coding=gbkimportsubprocessimportcsvdefget_nslookup(domain,dns):res=subprocess.Popen("nslookup{0}{1}".format(domain,dns),stdin=subprocess.PIPE,stdout=subprocess.PIPE).communicate()[0]response=res.decode("gbk")res_list=r...
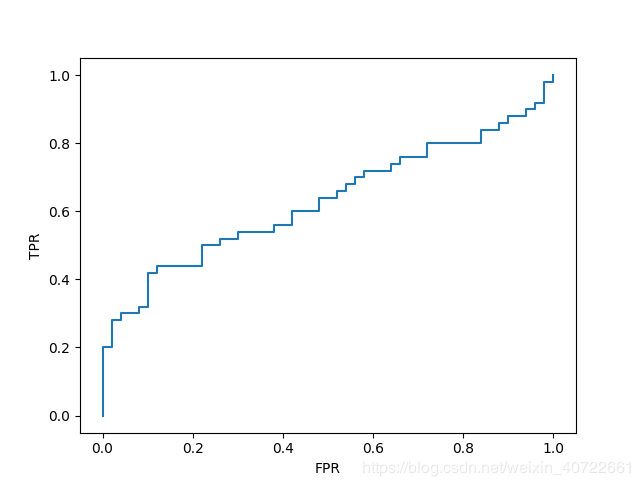 ROC结果源数据:鸢尾花数据集(仅采用其中的两种类别的花进行训练和检测)Summaryfeatures:['sepallength(cm)','sepalwidth(cm)','petallength(cm)','petalwidth(cm)']实例:[5.1,3.5,1.4,0.2]target:'setosa''versicolor'(0,1)采用回归方法进行拟合得到参数和biasmodel.fit(data_train,data_train_label)对测试数据进行预测得到概率值res=model.predict(data[:100])与训练集labels匹配后进行排序(从大到...
ROC结果源数据:鸢尾花数据集(仅采用其中的两种类别的花进行训练和检测)Summaryfeatures:['sepallength(cm)','sepalwidth(cm)','petallength(cm)','petalwidth(cm)']实例:[5.1,3.5,1.4,0.2]target:'setosa''versicolor'(0,1)采用回归方法进行拟合得到参数和biasmodel.fit(data_train,data_train_label)对测试数据进行预测得到概率值res=model.predict(data[:100])与训练集labels匹配后进行排序(从大到...
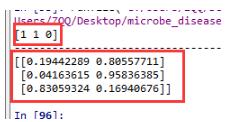 我就废话不多说了,大家还是直接看代码吧~clf=KMeans(n_clusters=5)#创建分类器对象fit_clf=clf.fit(X)#用训练器数据拟合分类器模型clf.predict(X)#也可以给新数据数据对其预测print(clf.cluster_centers_)#输出5个类的聚类中心y_pred=clf.fit_predict(X)#用训练器数据X拟合分类器模型并对训练器数据X进行预测print(y_pred)#输出预测结果补充知识:sklearn中调用某个机器学习模型model.predict(x)和model.predict_proba(x)...
我就废话不多说了,大家还是直接看代码吧~clf=KMeans(n_clusters=5)#创建分类器对象fit_clf=clf.fit(X)#用训练器数据拟合分类器模型clf.predict(X)#也可以给新数据数据对其预测print(clf.cluster_centers_)#输出5个类的聚类中心y_pred=clf.fit_predict(X)#用训练器数据X拟合分类器模型并对训练器数据X进行预测print(y_pred)#输出预测结果补充知识:sklearn中调用某个机器学习模型model.predict(x)和model.predict_proba(x)...
 很多应用多需要处理文件,而处理文件有一个固定的模式:打开文件,读入一些数据,处理这些数据,打印到屏幕上或写入另一个文件。那么,如果我们想修改之后立即写回文件,该怎么做呢?用什么模式打开?又怎么读写?我个人尝试了很多中方法,不是无法实现,就是操作非常麻烦。最终放弃。幸运的是,Python内置模块fileinput就可以轻松完成。代码如下:importfileinputforlineinfileinput.input(r"D:\1.txt",inplace=1):printl...
很多应用多需要处理文件,而处理文件有一个固定的模式:打开文件,读入一些数据,处理这些数据,打印到屏幕上或写入另一个文件。那么,如果我们想修改之后立即写回文件,该怎么做呢?用什么模式打开?又怎么读写?我个人尝试了很多中方法,不是无法实现,就是操作非常麻烦。最终放弃。幸运的是,Python内置模块fileinput就可以轻松完成。代码如下:importfileinputforlineinfileinput.input(r"D:\1.txt",inplace=1):printl...