
2020
10-06
10-06
win10下python3.8的PIL库安装过程
1.找到Python的位置我的是在C:\Users\admin\AppData\Local\Programs\Python\Python38AppData这个文件是个隐藏文件需要查询得先把隐藏文件显示出来win10里面在Microsoftstore下载的Python我只找到了exe文件,所以就卸载然后重新下载过。去官网下载的时候下载速度极其慢,可以去这下:https://python123.io/download2.PIL库的安装PIL库:具有强大的图像处理能力在上面找到的位置,打开终端,然后输入pipinstallpillow然后等待安...
继续阅读 >
 小数据用csv,大数据用h5结论1:几百KB以上的数据都用h5比较好结论2:几KB的数据h5反而很慢程序importpandasaspdimportnumpyasnpfromwja.wja_toolimporttest_timeasttfromwjaimportwja_toolastooldf=tool.generate_sampleDF(row,col)tt().run()df.to_csv('try.csv')tt().end()tt().run()df.to_hdf('try.h5','df',mode='w')tt().end()tt().run()df1=pd.read_csv('try.csv')tt().end()tt().run()df2=pd.read...
小数据用csv,大数据用h5结论1:几百KB以上的数据都用h5比较好结论2:几KB的数据h5反而很慢程序importpandasaspdimportnumpyasnpfromwja.wja_toolimporttest_timeasttfromwjaimportwja_toolastooldf=tool.generate_sampleDF(row,col)tt().run()df.to_csv('try.csv')tt().end()tt().run()df.to_hdf('try.h5','df',mode='w')tt().end()tt().run()df1=pd.read_csv('try.csv')tt().end()tt().run()df2=pd.read...
 写在前面:从昨晚的梦里回忆起数据管理的作业:实现一个自己的选题----毕业生信息管理系统,实现学生个人信息基本的增删改查,我想了想前段时间刚学习的列表,这个简单啊,设计一个学生信息列表,然后列表里面再存每个学生详细信息的列表,然后来实现一个基本的增删查改,这个不难啊!直接开始撸代码!上代码!defMenu():##菜单主界面print('*'*22)print("*查看毕业生列表输入:1*")print("*添加毕业生信息输入:2*")...
写在前面:从昨晚的梦里回忆起数据管理的作业:实现一个自己的选题----毕业生信息管理系统,实现学生个人信息基本的增删改查,我想了想前段时间刚学习的列表,这个简单啊,设计一个学生信息列表,然后列表里面再存每个学生详细信息的列表,然后来实现一个基本的增删查改,这个不难啊!直接开始撸代码!上代码!defMenu():##菜单主界面print('*'*22)print("*查看毕业生列表输入:1*")print("*添加毕业生信息输入:2*")...
 我就废话不多说了,大家还是直接看代码吧!importpandasaspddefget_under_rolling(df,window,user,name):df[name]=df[user].iloc[::-1].rolling(window=window).apply(lambdax:x[0]).iloc[::-1]returndfif__name__=='__main__':df=pd.DataFrame({'a':[1,2,3,4,5],'b':[2,3,4,5,6]})#把b列向下取值作为新的c列df=get_under_rolling(df,window=3,user='b',name='c')原始df新的df补充知识:pyt...
我就废话不多说了,大家还是直接看代码吧!importpandasaspddefget_under_rolling(df,window,user,name):df[name]=df[user].iloc[::-1].rolling(window=window).apply(lambdax:x[0]).iloc[::-1]returndfif__name__=='__main__':df=pd.DataFrame({'a':[1,2,3,4,5],'b':[2,3,4,5,6]})#把b列向下取值作为新的c列df=get_under_rolling(df,window=3,user='b',name='c')原始df新的df补充知识:pyt...
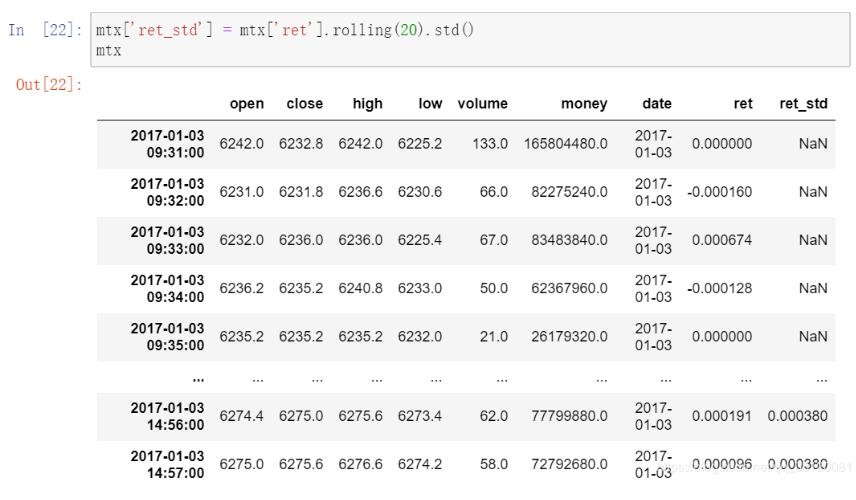 我就废话不多说了,大家还是直接看代码吧!#-*-coding:utf-8-*-"""CreatedonThuApr1211:23:462018@author:henbile"""#计算滚动波动率可以使用专门做技术分析的talib包里面的函数,也可以使用pandas包里面的滚动函数。#但是两个函数对于分母的选择,就是使用N还是N-1作为分母这件事情上是有分歧的。#另一个差异在于:talib包计算基于numpy,而pd.rolling是基于Series或者DataFrame的。importpandasaspdimportnumpy...
我就废话不多说了,大家还是直接看代码吧!#-*-coding:utf-8-*-"""CreatedonThuApr1211:23:462018@author:henbile"""#计算滚动波动率可以使用专门做技术分析的talib包里面的函数,也可以使用pandas包里面的滚动函数。#但是两个函数对于分母的选择,就是使用N还是N-1作为分母这件事情上是有分歧的。#另一个差异在于:talib包计算基于numpy,而pd.rolling是基于Series或者DataFrame的。importpandasaspdimportnumpy...
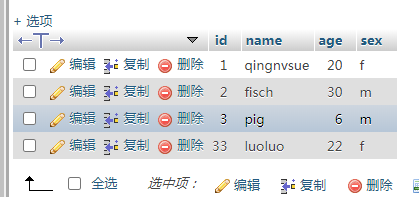 这是我的数据库student,好比输入一个值为32,查询id最接近32的整行数据,可以用以下代码importpymysqlvalue=32conn=pymysql.connect(host='39.106.168.84',user='xxxxxxx',password='xxxxxxx',port=3306,db='flask_topvj_net')cur=conn.cursor()sql="select*from`student`orderbyabs(`id`-'%s')limit1"%(value)cur.execute(sql)u=cur.fetchall()print(u)conn.close()运行结果为以上就是本文的全...
这是我的数据库student,好比输入一个值为32,查询id最接近32的整行数据,可以用以下代码importpymysqlvalue=32conn=pymysql.connect(host='39.106.168.84',user='xxxxxxx',password='xxxxxxx',port=3306,db='flask_topvj_net')cur=conn.cursor()sql="select*from`student`orderbyabs(`id`-'%s')limit1"%(value)cur.execute(sql)u=cur.fetchall()print(u)conn.close()运行结果为以上就是本文的全...
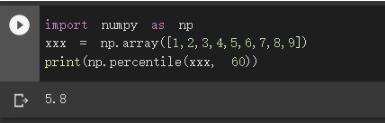 在python中计算一个多维数组的任意百分比分位数,此处的百分位是从小到大排列,只需用np.percentile即可……a=range(1,101)#求取a数列第90%分位的数值np.percentile(a,90)Out[5]:90.10000000000001a=range(101,1,-1)#百分位是从小到大排列np.percentile(a,90)Out[7]:91.10000000000001详看官方文档numpy.percentileParameters----------a:np数组q:floatinrangeof[0,100](orsequenceoffloats)Percentilet...
在python中计算一个多维数组的任意百分比分位数,此处的百分位是从小到大排列,只需用np.percentile即可……a=range(1,101)#求取a数列第90%分位的数值np.percentile(a,90)Out[5]:90.10000000000001a=range(101,1,-1)#百分位是从小到大排列np.percentile(a,90)Out[7]:91.10000000000001详看官方文档numpy.percentileParameters----------a:np数组q:floatinrangeof[0,100](orsequenceoffloats)Percentilet...
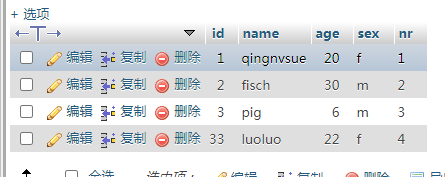 我的数据库如图结构我取了其中的nameagenr,做成array,只要所取数据存在str型,那么取出的数据,全部转化为str型,也就是array阵列的元素全是str,不管数据库定义的是不是int型。那么问题来了,取出的数据代入公式进行计算的时候,就会类型不符,这是就用到astype(np.float)代码如下importpymysqlimportnumpyasnpconn=pymysql.connect(host='39.106.168.84',user='xxxxxx',password='xxxxxx',port=3306,db...
我的数据库如图结构我取了其中的nameagenr,做成array,只要所取数据存在str型,那么取出的数据,全部转化为str型,也就是array阵列的元素全是str,不管数据库定义的是不是int型。那么问题来了,取出的数据代入公式进行计算的时候,就会类型不符,这是就用到astype(np.float)代码如下importpymysqlimportnumpyasnpconn=pymysql.connect(host='39.106.168.84',user='xxxxxx',password='xxxxxx',port=3306,db...
 删除有多行字符串的json文件中的离群值defprocessHold(eachsubject,directory,newfile):filename='CMUDataCol/Hold/subject{0}.json'.format(eachsubject)#原文件withopen(filename,'r')asf:forjsonstrinf.readlines():#按行读取原文件#这里的情况是每一行为一类数值,该行内的数据相互比较找出是否有离群值#若存在离群值,则删除该行数据data=json.loads(jsonstr)#计算四分位点a=numpy...
删除有多行字符串的json文件中的离群值defprocessHold(eachsubject,directory,newfile):filename='CMUDataCol/Hold/subject{0}.json'.format(eachsubject)#原文件withopen(filename,'r')asf:forjsonstrinf.readlines():#按行读取原文件#这里的情况是每一行为一类数值,该行内的数据相互比较找出是否有离群值#若存在离群值,则删除该行数据data=json.loads(jsonstr)#计算四分位点a=numpy...