
2020
10-06
10-06
python ETL工具 pyetl
pyetl是一个纯python开发的ETL框架,相比sqoop,datax之类的ETL工具,pyetl可以对每个字段添加udf函数,使得数据转换过程更加灵活,相比专业ETL工具pyetl更轻量,纯python代码操作,更加符合开发人员习惯安装pip3installpyetl使用示例数据库表之间数据同步frompyetlimportTask,DatabaseReader,DatabaseWriterreader=DatabaseReader("sqlite:///db1.sqlite3",table_name="source")writer=DatabaseWriter("sqlite:///d...
继续阅读 >
 路由简单来说,路由就是一个url到函数的映射,通过路由规则,可以使得url被指定的函数进行处理解析。我们都知道现在的web系统的URL都是可以自定义的,也就是我们可以指定url和具体的业务控制器相关联,而这些就是通过路由来实现的。flask中集成了路由处理模块,我们只需要简单地使用route装饰器就可以实现路由匹配。@app.route('/')defindex():return'IndexPage'@app.route('/hello')defhello():return'Hello,World'上面的...
路由简单来说,路由就是一个url到函数的映射,通过路由规则,可以使得url被指定的函数进行处理解析。我们都知道现在的web系统的URL都是可以自定义的,也就是我们可以指定url和具体的业务控制器相关联,而这些就是通过路由来实现的。flask中集成了路由处理模块,我们只需要简单地使用route装饰器就可以实现路由匹配。@app.route('/')defindex():return'IndexPage'@app.route('/hello')defhello():return'Hello,World'上面的...
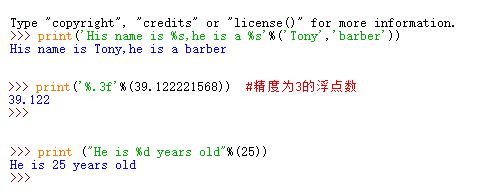 python连接数据库执行增删查改mysql数据库importpymysqlpostgresql数据库importpsycopg2普通含%的python语句sql语句中普通sql语句select*fromtableswheretablename='table_name',所以这里该加的引号还是要加不加的情况翻页的情况like的情况因为普通sql语句是where列名like'4301%'这里需要多加一个%防止转义补充知识:python中sql语句包含%怎么格式化问题描述:python中sql语句包含%时,格式化会出问题,怎...
python连接数据库执行增删查改mysql数据库importpymysqlpostgresql数据库importpsycopg2普通含%的python语句sql语句中普通sql语句select*fromtableswheretablename='table_name',所以这里该加的引号还是要加不加的情况翻页的情况like的情况因为普通sql语句是where列名like'4301%'这里需要多加一个%防止转义补充知识:python中sql语句包含%怎么格式化问题描述:python中sql语句包含%时,格式化会出问题,怎...
 在编写自己的程序时,需要实现将数据导入数据库,并且是带参数的传递。执行语句如下:sql_str="INSERTINTOteacher(t_name,t_info,t_phone,t_email)VALUES\(\'%s\',\'%s\',\'%s\',\'%s\')"%(result,result2,phoneNumber,Email)cur.execute(sql_str)执行程序后,产生错误:ProgrammingError:(1064,"YouhaveanerrorinyourSQLsyntax;checkthemanualthatcorrespondstoyourMySQLserverversionfort...
在编写自己的程序时,需要实现将数据导入数据库,并且是带参数的传递。执行语句如下:sql_str="INSERTINTOteacher(t_name,t_info,t_phone,t_email)VALUES\(\'%s\',\'%s\',\'%s\',\'%s\')"%(result,result2,phoneNumber,Email)cur.execute(sql_str)执行程序后,产生错误:ProgrammingError:(1064,"YouhaveanerrorinyourSQLsyntax;checkthemanualthatcorrespondstoyourMySQLserverversionfort...
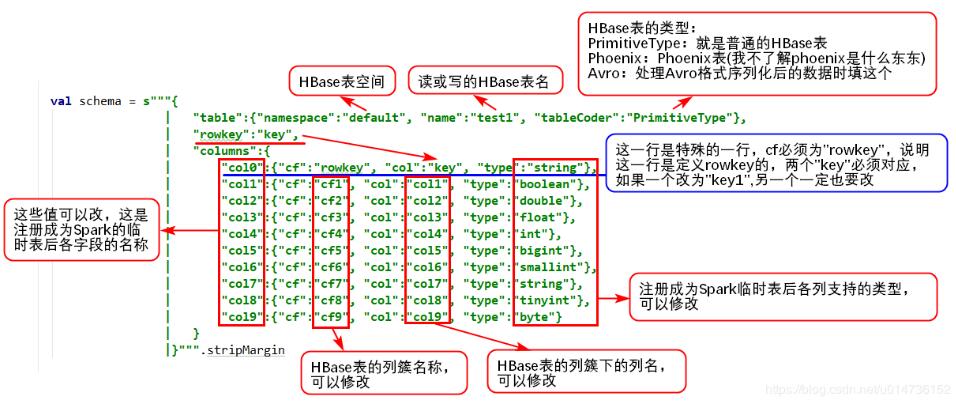 1、读Hive表数据pyspark读取hive数据非常简单,因为它有专门的接口来读取,完全不需要像hbase那样,需要做很多配置,pyspark提供的操作hive的接口,使得程序可以直接使用SQL语句从hive里面查询需要的数据,代码如下:frompyspark.sqlimportHiveContext,SparkSession_SPARK_HOST="spark://spark-master:7077"_APP_NAME="test"spark_session=SparkSession.builder.master(_SPARK_HOST).appName(_APP_NAME).getOrCreate()h...
1、读Hive表数据pyspark读取hive数据非常简单,因为它有专门的接口来读取,完全不需要像hbase那样,需要做很多配置,pyspark提供的操作hive的接口,使得程序可以直接使用SQL语句从hive里面查询需要的数据,代码如下:frompyspark.sqlimportHiveContext,SparkSession_SPARK_HOST="spark://spark-master:7077"_APP_NAME="test"spark_session=SparkSession.builder.master(_SPARK_HOST).appName(_APP_NAME).getOrCreate()h...
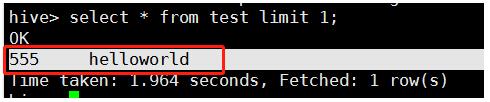 mysql可以使用nevicat导出insert语句用于数据构造,但是hive无法直接导出insert语句。我们可以先打印在hive命令行,然后使用脚本拼装成insert语句,进行数据构造。手动copy到python脚本进行sql语句构造:deftransformString(s):list_s=s.split('\t')print(len(list_s))s_new=''foriteminlist_s:s_new+='\"'+item.strip('')+'\"'+','returnstr(s_new.rstrip(','))#为手动copyhive命令行打印输出...
mysql可以使用nevicat导出insert语句用于数据构造,但是hive无法直接导出insert语句。我们可以先打印在hive命令行,然后使用脚本拼装成insert语句,进行数据构造。手动copy到python脚本进行sql语句构造:deftransformString(s):list_s=s.split('\t')print(len(list_s))s_new=''foriteminlist_s:s_new+='\"'+item.strip('')+'\"'+','returnstr(s_new.rstrip(','))#为手动copyhive命令行打印输出...
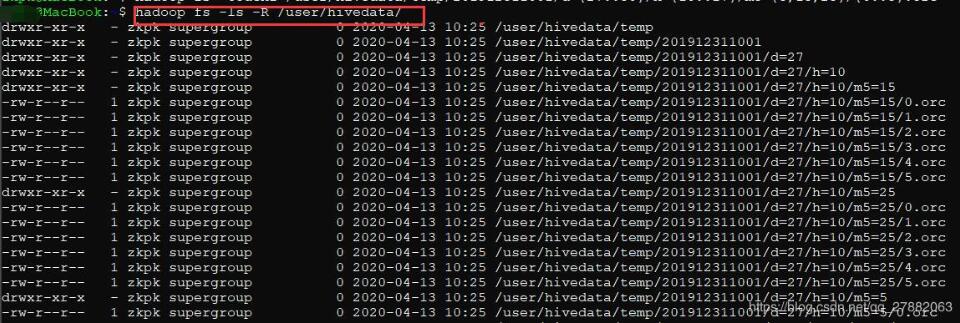 之前一直使用hdfs的命令进行hdfs操作,比如:hdfsdfs-ls/user/spark/hdfsdfs-get/user/spark/a.txt/home/spark/a.txt#从HDFS获取数据到本地hdfsdfs-put-f/home/spark/a.txt/user/spark/a.txt#从本地覆盖式上传hdfsdfs-mkdir-p/user/spark/home/datetime=20180817/....身为一个python程序员,每天操作hdfs都是在程序中写各种cmd调用的命令,一方面不好看,另一方面身为一个Pythoner这是一个耻辱,于是乎就挑了一...
之前一直使用hdfs的命令进行hdfs操作,比如:hdfsdfs-ls/user/spark/hdfsdfs-get/user/spark/a.txt/home/spark/a.txt#从HDFS获取数据到本地hdfsdfs-put-f/home/spark/a.txt/user/spark/a.txt#从本地覆盖式上传hdfsdfs-mkdir-p/user/spark/home/datetime=20180817/....身为一个python程序员,每天操作hdfs都是在程序中写各种cmd调用的命令,一方面不好看,另一方面身为一个Pythoner这是一个耻辱,于是乎就挑了一...
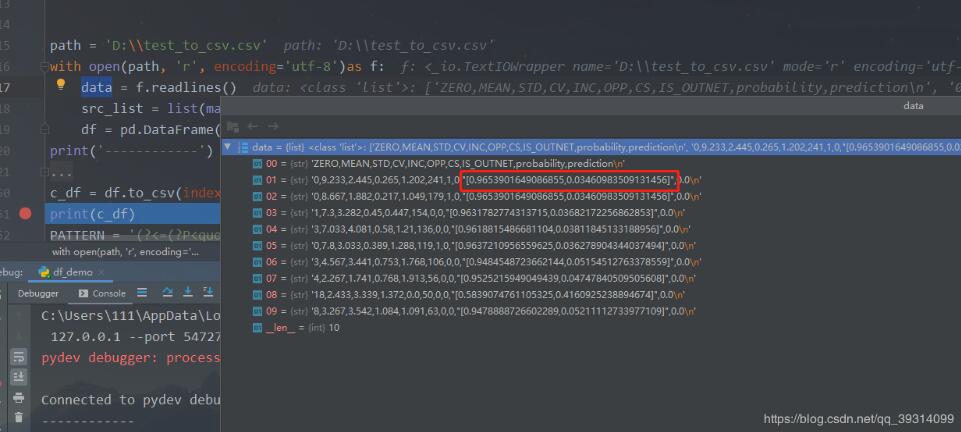 1.目标通过hadoophive或spark等数据计算框架完成数据清洗后的数据在HDFS上爬虫和机器学习在Python中容易实现在Linux环境下编写Python没有pyCharm便利需要建立Python与HDFS的读写通道2.实现安装Python模块pyhdfs版本:Python3.6,hadoop2.9读文件代码如下frompyhdfsimportHdfsClientclient=HdfsClient(hosts='ghym:50070')#hdfs地址res=client.open('/sy.txt')#hdfs文件路径,根目录/forrinres:line=str(r,encoding='utf8'...
1.目标通过hadoophive或spark等数据计算框架完成数据清洗后的数据在HDFS上爬虫和机器学习在Python中容易实现在Linux环境下编写Python没有pyCharm便利需要建立Python与HDFS的读写通道2.实现安装Python模块pyhdfs版本:Python3.6,hadoop2.9读文件代码如下frompyhdfsimportHdfsClientclient=HdfsClient(hosts='ghym:50070')#hdfs地址res=client.open('/sy.txt')#hdfs文件路径,根目录/forrinres:line=str(r,encoding='utf8'...