
2021
07-01
07-01
在pytorch中计算准确率,召回率和F1值的操作
 看代码吧~predict=output.argmax(dim=1)confusion_matrix=torch.zeros(2,2)fort,pinzip(predict.view(-1),target.view(-1)):confusion_matrix[t.long(),p.long()]+=1a_p=(confusion_matrix.diag()/confusion_matrix.sum(1))[0]b_p=(confusion_matrix.diag()/confusion_matrix.sum(1))[1]a_r=(confusion_matrix.diag()/confusion_matrix.sum(0))[0]b_r=(confusion_matrix.diag()/confusion_matrix.s...
继续阅读 >
看代码吧~predict=output.argmax(dim=1)confusion_matrix=torch.zeros(2,2)fort,pinzip(predict.view(-1),target.view(-1)):confusion_matrix[t.long(),p.long()]+=1a_p=(confusion_matrix.diag()/confusion_matrix.sum(1))[0]b_p=(confusion_matrix.diag()/confusion_matrix.sum(1))[1]a_r=(confusion_matrix.diag()/confusion_matrix.sum(0))[0]b_r=(confusion_matrix.diag()/confusion_matrix.s...
继续阅读 >
 pytorch中matmul和mm和bmm区别matmulmmbmm结论先看下官网上对这三个函数的介绍。matmulmmbmm顾名思义,就是两个batch矩阵乘法.结论从官方文档可以看出1、mm只能进行矩阵乘法,也就是输入的两个tensor维度只能是(n×m)(n\timesm)(n×m)和(m×p)(m\timesp)(m×p)2、bmm是两个三维张量相乘,两个输入tensor维度是(b×n×m)(b\timesn\timesm)(b×n×m)和(b×m×p)(b\timesm\timesp)(b×m×p),第一维b代...
pytorch中matmul和mm和bmm区别matmulmmbmm结论先看下官网上对这三个函数的介绍。matmulmmbmm顾名思义,就是两个batch矩阵乘法.结论从官方文档可以看出1、mm只能进行矩阵乘法,也就是输入的两个tensor维度只能是(n×m)(n\timesm)(n×m)和(m×p)(m\timesp)(m×p)2、bmm是两个三维张量相乘,两个输入tensor维度是(b×n×m)(b\timesn\timesm)(b×n×m)和(b×m×p)(b\timesm\timesp)(b×m×p),第一维b代...
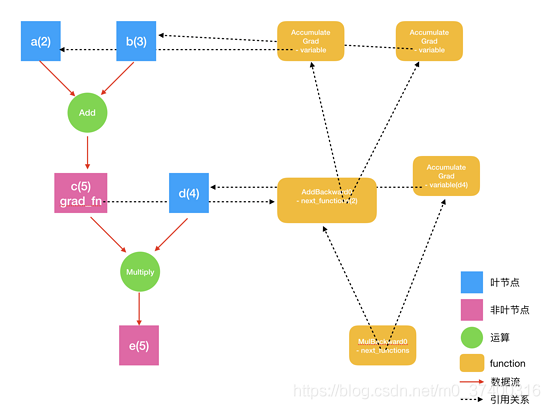 在PyTorch实现中,autograd会随着用户的操作,记录生成当前variable的所有操作,并由此建立一个有向无环图。用户每进行一个操作,相应的计算图就会发生改变。更底层的实现中,图中记录了操作Function,每一个变量在图中的位置可通过其grad_fn属性在图中的位置推测得到。在反向传播过程中,autograd沿着这个图从当前变量(根节点\textbf{z}z)溯源,可以利用链式求导法则计算所有叶子节点的梯度。每一个前向传播操作的函数都有与之...
在PyTorch实现中,autograd会随着用户的操作,记录生成当前variable的所有操作,并由此建立一个有向无环图。用户每进行一个操作,相应的计算图就会发生改变。更底层的实现中,图中记录了操作Function,每一个变量在图中的位置可通过其grad_fn属性在图中的位置推测得到。在反向传播过程中,autograd沿着这个图从当前变量(根节点\textbf{z}z)溯源,可以利用链式求导法则计算所有叶子节点的梯度。每一个前向传播操作的函数都有与之...
 错误代码:输出grad为nonea=torch.ones((2,2),requires_grad=True).to(device)b=a.sum()b.backward()print(a.grad)由于.to(device)是一次操作,此时的a已经不是叶子节点了修改后的代码为:a=torch.ones((2,2),requires_grad=True)c=a.to(device)b=c.sum()b.backward()print(a.grad)类似错误:self.miu=torch.nn.Parameter(torch.ones(self.dimensional))*0.01应该为self.miu=torch.nn.Parameter(torch.ones(se...
错误代码:输出grad为nonea=torch.ones((2,2),requires_grad=True).to(device)b=a.sum()b.backward()print(a.grad)由于.to(device)是一次操作,此时的a已经不是叶子节点了修改后的代码为:a=torch.ones((2,2),requires_grad=True)c=a.to(device)b=c.sum()b.backward()print(a.grad)类似错误:self.miu=torch.nn.Parameter(torch.ones(self.dimensional))*0.01应该为self.miu=torch.nn.Parameter(torch.ones(se...
 1.TensorBoard神经网络可视化工具TensorBoard是一个强大的可视化工具,在pytorch中有两种调用方法:1.fromtensorboardXimportSummaryWriter这种方法是在官方还不支持tensorboard时网上有大神写的2.fromtorch.utils.tensorboardimportSummaryWriter这种方法是后来更新官方加入的1.1调用方法1.1.1创建接口SummaryWriter功能:创建接口调用方法:writer=SummaryWriter("runs")参数:log_dir:eventfile输出文件夹comment:...
1.TensorBoard神经网络可视化工具TensorBoard是一个强大的可视化工具,在pytorch中有两种调用方法:1.fromtensorboardXimportSummaryWriter这种方法是在官方还不支持tensorboard时网上有大神写的2.fromtorch.utils.tensorboardimportSummaryWriter这种方法是后来更新官方加入的1.1调用方法1.1.1创建接口SummaryWriter功能:创建接口调用方法:writer=SummaryWriter("runs")参数:log_dir:eventfile输出文件夹comment:...
 大家还是直接看代码吧~netG=Generator()print('#generatorparameters:',sum(param.numel()forparaminnetG.parameters()))netD=Discriminator()print('#discriminatorparameters:',sum(param.numel()forparaminnetD.parameters()))补充:PyTorch查看网络模型的参数量PARAMS和FLOPS等在PyTorch中,可以使用torchstat这个库来查看网络模型的一些信息,包括总的参数量params、MAdd、显卡内存占用量和FLOPs等。示例代...
大家还是直接看代码吧~netG=Generator()print('#generatorparameters:',sum(param.numel()forparaminnetG.parameters()))netD=Discriminator()print('#discriminatorparameters:',sum(param.numel()forparaminnetD.parameters()))补充:PyTorch查看网络模型的参数量PARAMS和FLOPS等在PyTorch中,可以使用torchstat这个库来查看网络模型的一些信息,包括总的参数量params、MAdd、显卡内存占用量和FLOPs等。示例代...
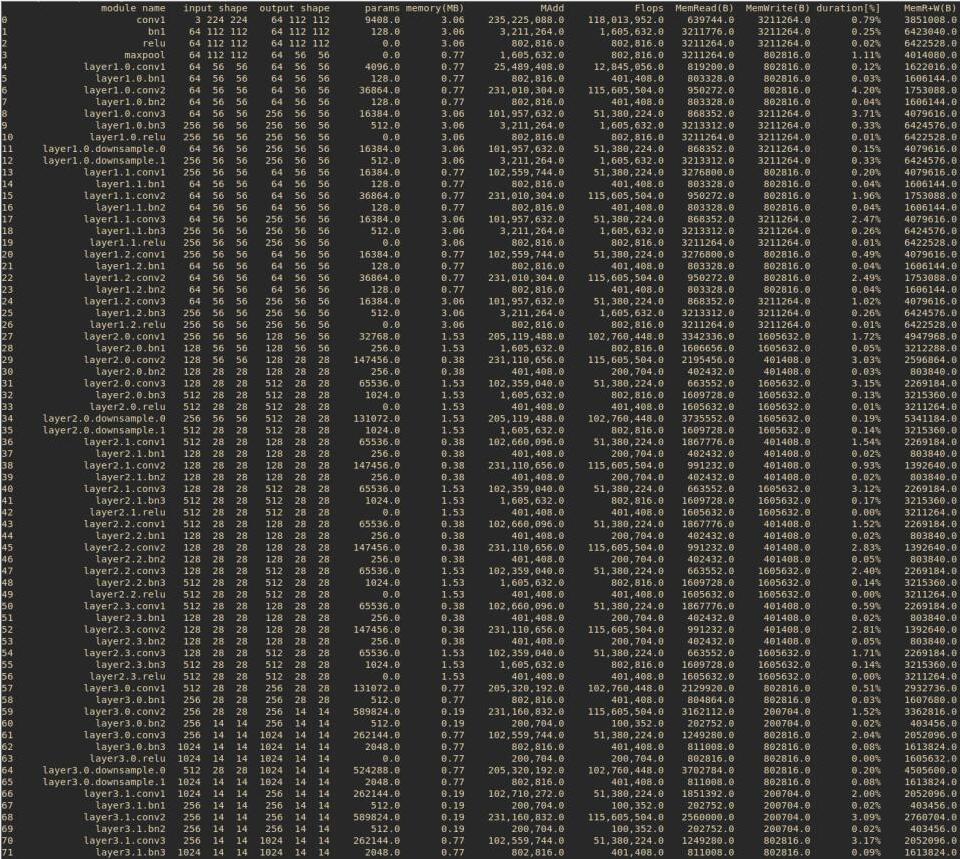
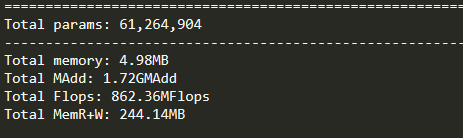 1.使用torchstatpipinstalltorchstatfromtorchstatimportstatimporttorchvision.modelsasmodelsmodel=models.resnet152()stat(model,(3,224,224))关于stat函数的参数,第一个应该是模型,第二个则是输入尺寸,3为通道数。我没有调研该函数的详细参数,也不知道为什么使用的时候并不提示相应的参数。2.使用torchsummarypipinstalltorchsummaryfromtorchsummaryimportsummarysummary(model.cuda(),input_size=(3...
1.使用torchstatpipinstalltorchstatfromtorchstatimportstatimporttorchvision.modelsasmodelsmodel=models.resnet152()stat(model,(3,224,224))关于stat函数的参数,第一个应该是模型,第二个则是输入尺寸,3为通道数。我没有调研该函数的详细参数,也不知道为什么使用的时候并不提示相应的参数。2.使用torchsummarypipinstalltorchsummaryfromtorchsummaryimportsummarysummary(model.cuda(),input_size=(3...
 我们在用神经网络求解PDE时,经常要用到输出值对输入变量(不是Weights和Biases)求导;在训练WGAN-GP时,也会用到网络对输入变量的求导。以上两种需求,均可以用pytorch中的autograd.grad()函数实现。autograd.grad(outputs,inputs,grad_outputs=None,retain_graph=None,create_graph=False,only_inputs=True,allow_unused=False)outputs:求导的因变量(需要求导的函数)inputs:求导的自变量grad_outputs:如果ou...
我们在用神经网络求解PDE时,经常要用到输出值对输入变量(不是Weights和Biases)求导;在训练WGAN-GP时,也会用到网络对输入变量的求导。以上两种需求,均可以用pytorch中的autograd.grad()函数实现。autograd.grad(outputs,inputs,grad_outputs=None,retain_graph=None,create_graph=False,only_inputs=True,allow_unused=False)outputs:求导的因变量(需要求导的函数)inputs:求导的自变量grad_outputs:如果ou...
 关于Variable和Tensor旧版本的Pytorch中,Variable是对Tensor的一个封装;在Pytorch大于v0.4的版本后,Varible和Tensor合并了,意味着Tensor可以像旧版本的Variable那样运行,当然新版本中Variable封装仍旧可以用,但是对Varieble操作返回的将是一个Tensor。importtorchastfromtorch.autogradimportVariablea=t.ones(3,requires_grad=True)print(type(a))#输出:<class'torch.Tensor'>a=Variable(a)print(type(a))#输出...
关于Variable和Tensor旧版本的Pytorch中,Variable是对Tensor的一个封装;在Pytorch大于v0.4的版本后,Varible和Tensor合并了,意味着Tensor可以像旧版本的Variable那样运行,当然新版本中Variable封装仍旧可以用,但是对Varieble操作返回的将是一个Tensor。importtorchastfromtorch.autogradimportVariablea=t.ones(3,requires_grad=True)print(type(a))#输出:<class'torch.Tensor'>a=Variable(a)print(type(a))#输出...
 今天在使用pytorch进行训练,在运行loss.backward()误差反向传播时出错:RuntimeError:gradcanbeimplicitlycreatedonlyforscalaroutputsFile"train.py",line143,intrainloss.backward()File"/usr/local/lib/python3.6/dist-packages/torch/tensor.py",line198,inbackwardtorch.autograd.backward(self,gradient,retain_graph,create_graph)File"/usr/local/lib/python3.6/dist-packages/torch/autograd/...
今天在使用pytorch进行训练,在运行loss.backward()误差反向传播时出错:RuntimeError:gradcanbeimplicitlycreatedonlyforscalaroutputsFile"train.py",line143,intrainloss.backward()File"/usr/local/lib/python3.6/dist-packages/torch/tensor.py",line198,inbackwardtorch.autograd.backward(self,gradient,retain_graph,create_graph)File"/usr/local/lib/python3.6/dist-packages/torch/autograd/...
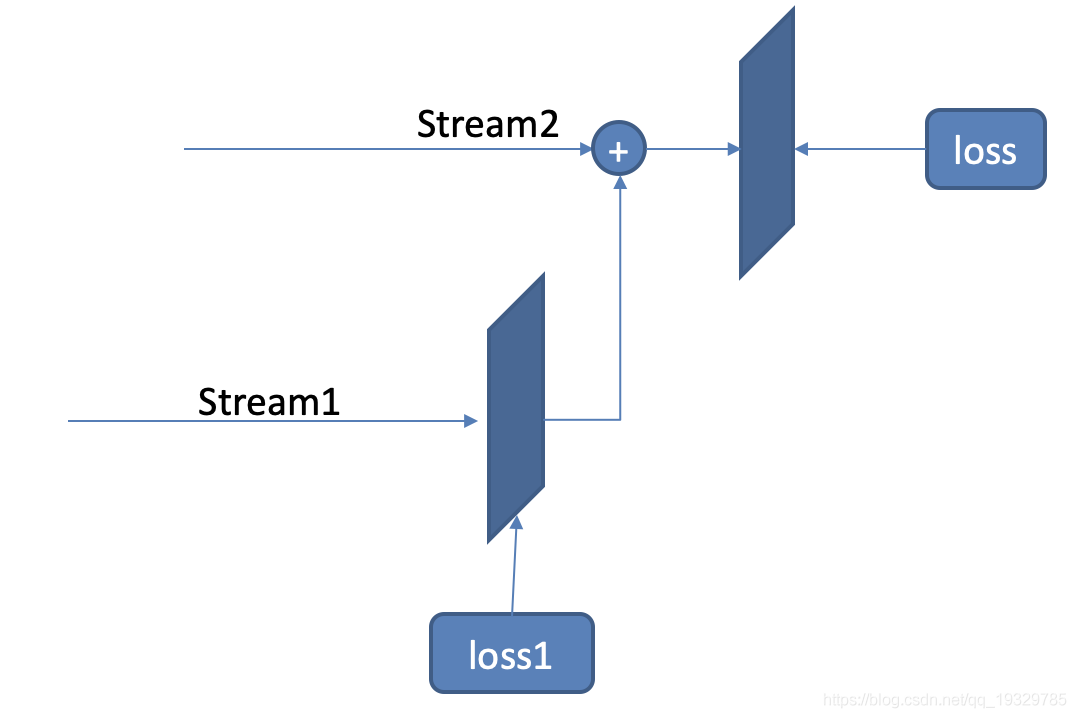
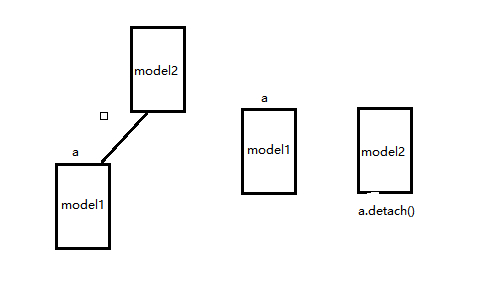 之前我的一篇文章pytorch计算图以及backward,讲了一些pytorch中基本的反向传播,理清了梯度是如何计算以及下降的,建议先看懂那个,然后再看这个。从一个错误说起:RuntimeError:Tryingtobackwardthroughthegraphasecondtime,butthebuffershavealreadybeenfreed在深度学习中,有些场景需要进行两次反向,比如Gan网络,需要对D进行一次,还要对G进行一次,很多人都会遇到上面这个错误,这个错误的意思就是尝试对...
之前我的一篇文章pytorch计算图以及backward,讲了一些pytorch中基本的反向传播,理清了梯度是如何计算以及下降的,建议先看懂那个,然后再看这个。从一个错误说起:RuntimeError:Tryingtobackwardthroughthegraphasecondtime,butthebuffershavealreadybeenfreed在深度学习中,有些场景需要进行两次反向,比如Gan网络,需要对D进行一次,还要对G进行一次,很多人都会遇到上面这个错误,这个错误的意思就是尝试对...
 一、禁止计算局部梯度torch.autogard.no_grad:禁用梯度计算的上下文管理器。当确定不会调用Tensor.backward()计算梯度时,设置禁止计算梯度会减少内存消耗。如果需要计算梯度设置Tensor.requires_grad=True两种禁用方法:将不用计算梯度的变量放在withtorch.no_grad()里>>>x=torch.tensor([1.],requires_grad=True)>>>withtorch.no_grad():...y=x*2>>>y.requires_gradOut[12]:False使用装饰器@torch.no_gard()修...
一、禁止计算局部梯度torch.autogard.no_grad:禁用梯度计算的上下文管理器。当确定不会调用Tensor.backward()计算梯度时,设置禁止计算梯度会减少内存消耗。如果需要计算梯度设置Tensor.requires_grad=True两种禁用方法:将不用计算梯度的变量放在withtorch.no_grad()里>>>x=torch.tensor([1.],requires_grad=True)>>>withtorch.no_grad():...y=x*2>>>y.requires_gradOut[12]:False使用装饰器@torch.no_gard()修...