
2020
11-29
11-29
Redis分布式锁python-redis-lock使用方法
python-redis-lock多个redis客户端访问同一个redis服务端,控制并发。github:https://pypi.org/project/python-redis-lock/在使用这个库之前,需要安装如下:pipinstallpython-redis-lock使用锁的示例:lock=redis_lock.Lock(conn,"name-of-the-lock")iflock.acquire(blocking=False):print("Gotthelock.")lock.release()else:print("Someoneelsehasthelock.")上面是单独设置锁的方式,还可以单独设置所有redis...
继续阅读 >
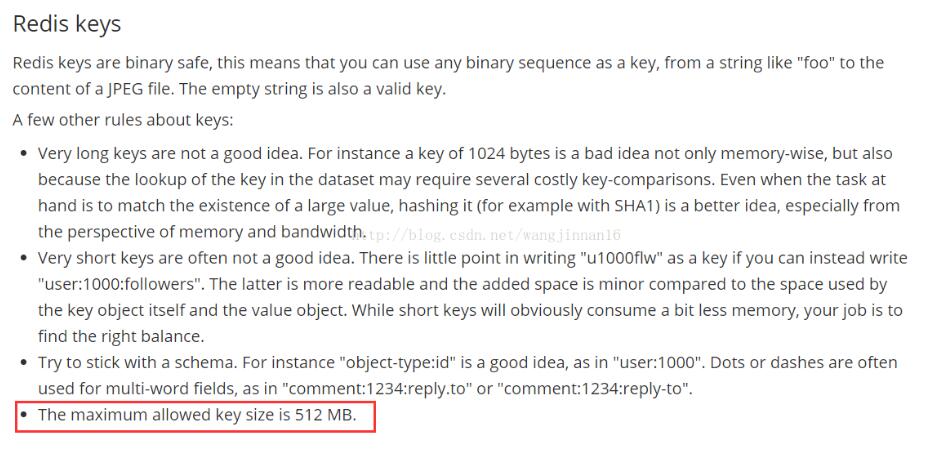 今天研究了下将javabean序列化到redis中存储起来,突然脑袋灵光一闪,对象大小会不会超过redis限制?不管怎么着,还是搞清楚一下比较好,所以就去问了下百度,果然没多少人关心这个问题,没找到比较合适的答案,所以决定还是去官网找吧。找到两句比较关键的话,截图如下。结论redis的key和string类型value限制均为512MB。补充知识:Redis获取所有键值通过遍历获取目标键值:importredisredis=redis.Redis(host='192.24.210.2',...
今天研究了下将javabean序列化到redis中存储起来,突然脑袋灵光一闪,对象大小会不会超过redis限制?不管怎么着,还是搞清楚一下比较好,所以就去问了下百度,果然没多少人关心这个问题,没找到比较合适的答案,所以决定还是去官网找吧。找到两句比较关键的话,截图如下。结论redis的key和string类型value限制均为512MB。补充知识:Redis获取所有键值通过遍历获取目标键值:importredisredis=redis.Redis(host='192.24.210.2',...
 首先要启动AOF持久化配置,在redis.windows-server.conf配置文件中做出如下更改................appendonlyyes#Thenameoftheappendonlyfile(default:"appendonly.aof")appendfilename"appendonly.aof".....................................#appendfsyncalwaysappendfsynceverysec#appendfsyncno....................测试加入不小心清空了数据:打开appendonly.aof文件,将flushall命令删除掉,并将这个文件放到red...
首先要启动AOF持久化配置,在redis.windows-server.conf配置文件中做出如下更改................appendonlyyes#Thenameoftheappendonlyfile(default:"appendonly.aof")appendfilename"appendonly.aof".....................................#appendfsyncalwaysappendfsynceverysec#appendfsyncno....................测试加入不小心清空了数据:打开appendonly.aof文件,将flushall命令删除掉,并将这个文件放到red...
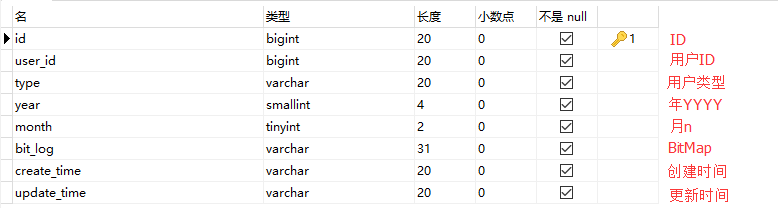 项目需求,试着写了一个简单登录统计,基本功能都实现了,日志数据量小。具体性能没有进行测试~记录下开发过程与代码,留着以后改进!1.需求 实现记录用户哪天进行了登录,每天只记录是否登录过,重复登录状态算已登录。不需要记录用户的操作行为,不需要记录用户上次登录时间和IP地址(这部分以后需要可以单独拿出来存储)区分用户类型查询数据需要精确到天2.分析...
项目需求,试着写了一个简单登录统计,基本功能都实现了,日志数据量小。具体性能没有进行测试~记录下开发过程与代码,留着以后改进!1.需求 实现记录用户哪天进行了登录,每天只记录是否登录过,重复登录状态算已登录。不需要记录用户的操作行为,不需要记录用户上次登录时间和IP地址(这部分以后需要可以单独拿出来存储)区分用户类型查询数据需要精确到天2.分析...
 一直知道redis可以用来实现计数器功能,但是之前没有实际使用过,昨天碰到一个需求:用户扫码当天达到20次即提示:当日扫码次数达到上限!当时就想到使用redis的递增方法increment()来实现计数器功能,一定要注意redisTemplate和stringRedisTemplate的使用首先设置key:该key我使用了用户id和当天日期作为key的一部分,date:xxxx-xx-xx格式,这样一来该用户在第二天扫码的时候又是一个新key,因为日期不同了设置key的过期时间:实...
一直知道redis可以用来实现计数器功能,但是之前没有实际使用过,昨天碰到一个需求:用户扫码当天达到20次即提示:当日扫码次数达到上限!当时就想到使用redis的递增方法increment()来实现计数器功能,一定要注意redisTemplate和stringRedisTemplate的使用首先设置key:该key我使用了用户id和当天日期作为key的一部分,date:xxxx-xx-xx格式,这样一来该用户在第二天扫码的时候又是一个新key,因为日期不同了设置key的过期时间:实...
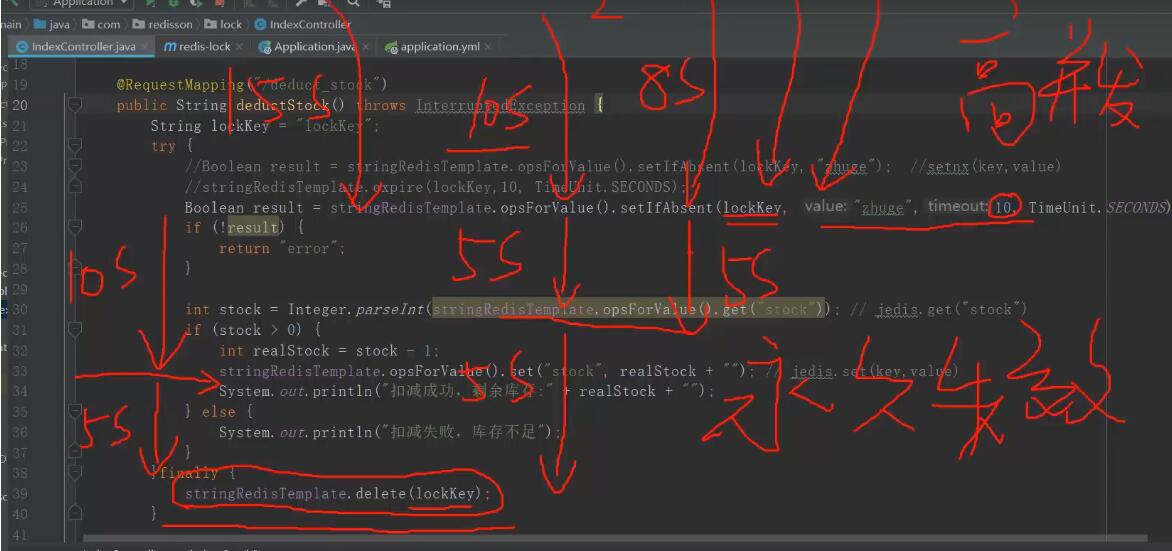 项目背景:1、新增问题件工单,工单中有工单编码字段,工单编码字段的规则为“WT”+yyyyMMdd+0000001。2、每天的工单生成量是30W,所以会存在并发问题解决思路:1、首先乐观的认为redis不会宕机,对应的缓存不会被清除(除非人为操作,人为操作会有独立的补救办法)2、将工单编码存到缓存中(redis),其值只存“WT”+yyyyMMdd后面的数字部分;对应的key为:key标识+yyyyMMdd,即每天一个key3、每次生成工单编码时,先调用redis的i...
项目背景:1、新增问题件工单,工单中有工单编码字段,工单编码字段的规则为“WT”+yyyyMMdd+0000001。2、每天的工单生成量是30W,所以会存在并发问题解决思路:1、首先乐观的认为redis不会宕机,对应的缓存不会被清除(除非人为操作,人为操作会有独立的补救办法)2、将工单编码存到缓存中(redis),其值只存“WT”+yyyyMMdd后面的数字部分;对应的key为:key标识+yyyyMMdd,即每天一个key3、每次生成工单编码时,先调用redis的i...
 我们在本地的开发中为了保证大家都开发环境一直,PHP的扩展,版本保持一致,我们使用了docker.但是由于redis/mongodb在宿主机上,所以通过127.0.0.1是连接不上的前提说明这个是在docker运行容器时使用的桥接模式(默认)时才会发生以上问题.如果使用host模式就没有.所以,我们就是要把是docker的网络模式设置为host模式.具体实现~dockerrun--networkhostphp56补充说明使用了host模式后,则表示宿主机与容器共享宿...
我们在本地的开发中为了保证大家都开发环境一直,PHP的扩展,版本保持一致,我们使用了docker.但是由于redis/mongodb在宿主机上,所以通过127.0.0.1是连接不上的前提说明这个是在docker运行容器时使用的桥接模式(默认)时才会发生以上问题.如果使用host模式就没有.所以,我们就是要把是docker的网络模式设置为host模式.具体实现~dockerrun--networkhostphp56补充说明使用了host模式后,则表示宿主机与容器共享宿...
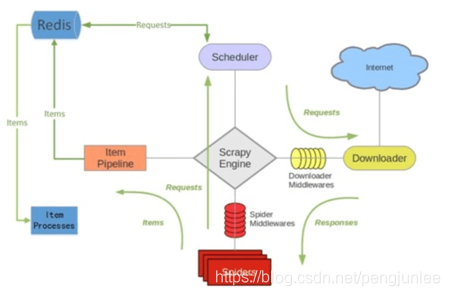 简介scrapy-redis是一个基于redis的scrapy组件,用于快速实现scrapy项目的分布式部署和数据爬取,其运行原理如下图所示。Scrapy-Redis特性分布式爬取你可以启动多个共享同一redis队列的爬虫实例,多个爬虫实例将各自提取到或者已请求的Requests在队列中统一进行登记,使得Scheduler在请求调度时能够对重复Requests进行过滤,即保证已经由某一个爬虫实例请求过的Request将不会再被其他的爬虫实例重复请求。分布式数据处理将scrapy爬...
简介scrapy-redis是一个基于redis的scrapy组件,用于快速实现scrapy项目的分布式部署和数据爬取,其运行原理如下图所示。Scrapy-Redis特性分布式爬取你可以启动多个共享同一redis队列的爬虫实例,多个爬虫实例将各自提取到或者已请求的Requests在队列中统一进行登记,使得Scheduler在请求调度时能够对重复Requests进行过滤,即保证已经由某一个爬虫实例请求过的Request将不会再被其他的爬虫实例重复请求。分布式数据处理将scrapy爬...