
2021
10-15
10-15
python3 scrapy框架的执行流程
 scrapy框架概述:Scrapy,Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。创建项目由于pycharm不能直接创建scrapy项目,必须通过命令行创建,所以相关操作在pycharm的终端进行:1、安装scrapy模块:pipinstall-ihttps://pypi.tuna.tsinghua.edu.cn/simplescrapy2、创建一个scrapy项目:scrapystartprojecttest_scra...
继续阅读 >
scrapy框架概述:Scrapy,Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。创建项目由于pycharm不能直接创建scrapy项目,必须通过命令行创建,所以相关操作在pycharm的终端进行:1、安装scrapy模块:pipinstall-ihttps://pypi.tuna.tsinghua.edu.cn/simplescrapy2、创建一个scrapy项目:scrapystartprojecttest_scra...
继续阅读 >
 项目需求在专门供爬虫初学者训练爬虫技术的网站(http://quotes.toscrape.com)上爬取名言警句。创建项目在开始爬取之前,必须创建一个新的Scrapy项目。进入您打算存储代码的目录中,运行下列命令:(base)λscrapystartprojectquotesNewscrapyproject'quotes',usingtemplatedirectory'd:\anaconda3\lib\site-packages\scrapy\temp1ates\project',createdin:D:\XXXYoucanstartyourfirstspiderwith:cd...
项目需求在专门供爬虫初学者训练爬虫技术的网站(http://quotes.toscrape.com)上爬取名言警句。创建项目在开始爬取之前,必须创建一个新的Scrapy项目。进入您打算存储代码的目录中,运行下列命令:(base)λscrapystartprojectquotesNewscrapyproject'quotes',usingtemplatedirectory'd:\anaconda3\lib\site-packages\scrapy\temp1ates\project',createdin:D:\XXXYoucanstartyourfirstspiderwith:cd...
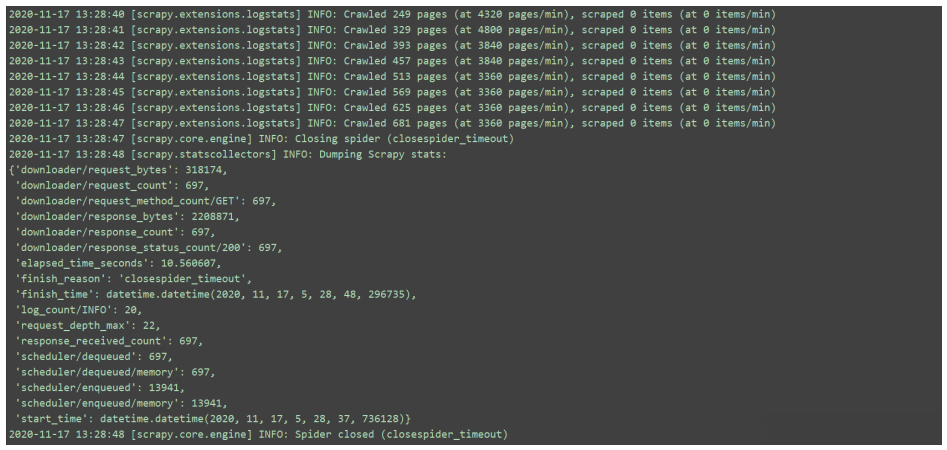 网络爬虫网络爬虫是指在互联网上自动爬取网站内容信息的程序,也被称作网络蜘蛛或网络机器人。大型的爬虫程序被广泛应用于搜索引擎、数据挖掘等领域,个人用户或企业也可以利用爬虫收集对自身有价值的数据。一个网络爬虫程序的基本执行流程可以总结三个过程:请求数据,解析数据,保存数据数据请求请求的数据除了普通的HTML之外,还有json数据、字符串数据、图片、视频、音频等。解析数据当一个数据下载完成后,对数据中的内容进行...
网络爬虫网络爬虫是指在互联网上自动爬取网站内容信息的程序,也被称作网络蜘蛛或网络机器人。大型的爬虫程序被广泛应用于搜索引擎、数据挖掘等领域,个人用户或企业也可以利用爬虫收集对自身有价值的数据。一个网络爬虫程序的基本执行流程可以总结三个过程:请求数据,解析数据,保存数据数据请求请求的数据除了普通的HTML之外,还有json数据、字符串数据、图片、视频、音频等。解析数据当一个数据下载完成后,对数据中的内容进行...
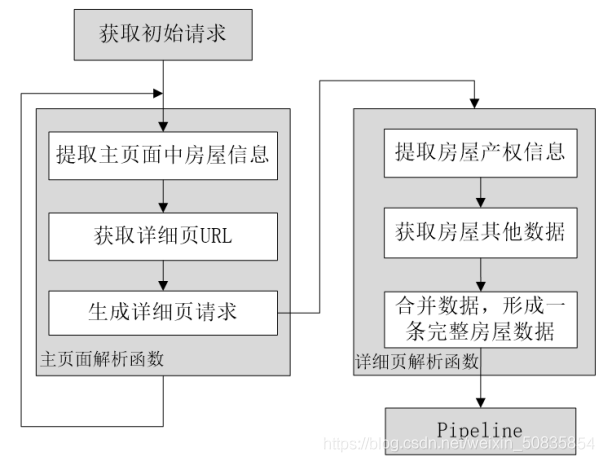 一、项目需求使用Scrapy爬取链家网中苏州市二手房交易数据并保存于CSV文件中要求:房屋面积、总价和单价只需要具体的数字,不需要单位名称。删除字段不全的房屋数据,如有的房屋朝向会显示“暂无数据”,应该剔除。保存到CSV文件中的数据,字段要按照如下顺序排列:房屋名称,房屋户型,建筑面积,房屋朝向,装修情况,有无电梯,房屋总价,房屋单价,房屋产权。二、项目分析流程图通过控制台发现所有房屋信息都在一个ul中其中每一...
一、项目需求使用Scrapy爬取链家网中苏州市二手房交易数据并保存于CSV文件中要求:房屋面积、总价和单价只需要具体的数字,不需要单位名称。删除字段不全的房屋数据,如有的房屋朝向会显示“暂无数据”,应该剔除。保存到CSV文件中的数据,字段要按照如下顺序排列:房屋名称,房屋户型,建筑面积,房屋朝向,装修情况,有无电梯,房屋总价,房屋单价,房屋产权。二、项目分析流程图通过控制台发现所有房屋信息都在一个ul中其中每一...
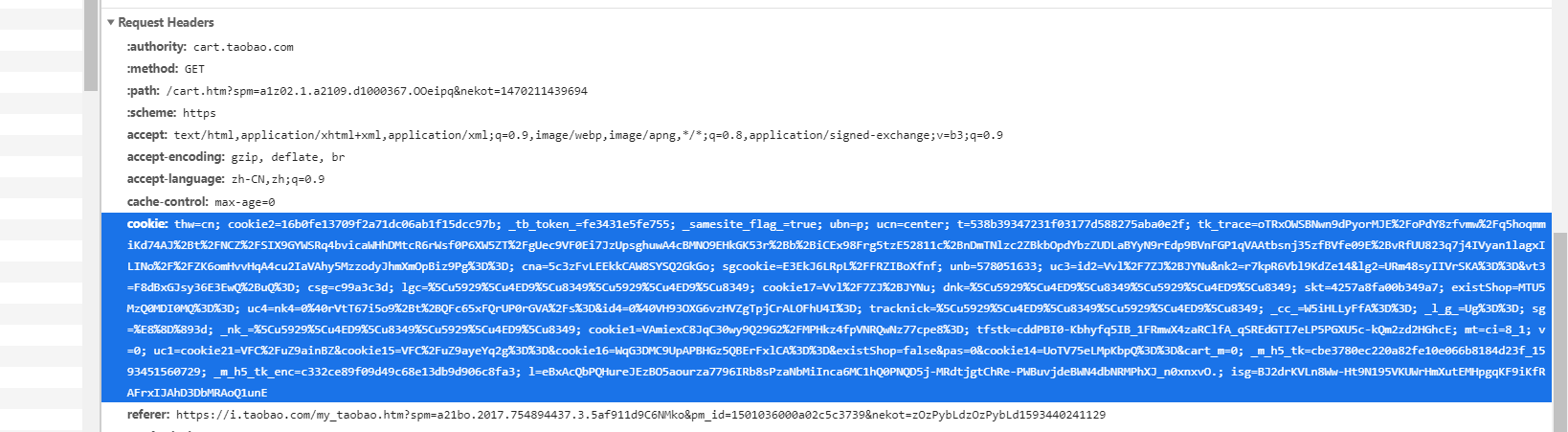 scrapy框架简介Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便scrapy架构图crapyEngine(引擎):负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。Scheduler(调度器):它负责接受引擎发送过来的Request请求,并按照一定的方式进...
scrapy框架简介Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便scrapy架构图crapyEngine(引擎):负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。Scheduler(调度器):它负责接受引擎发送过来的Request请求,并按照一定的方式进...