
2020
10-08
10-08
Python scrapy爬取小说代码案例详解
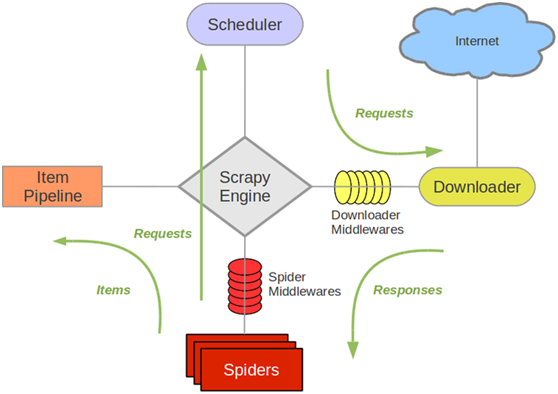 scrapy是目前python使用的最广泛的爬虫框架架构图如下解释:ScrapyEngine(引擎):负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。Scheduler(调度器):它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。Downloader(下载器):负责下载ScrapyEngine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给ScrapyEngine(引擎)...
继续阅读 >
scrapy是目前python使用的最广泛的爬虫框架架构图如下解释:ScrapyEngine(引擎):负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。Scheduler(调度器):它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。Downloader(下载器):负责下载ScrapyEngine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给ScrapyEngine(引擎)...
继续阅读 >
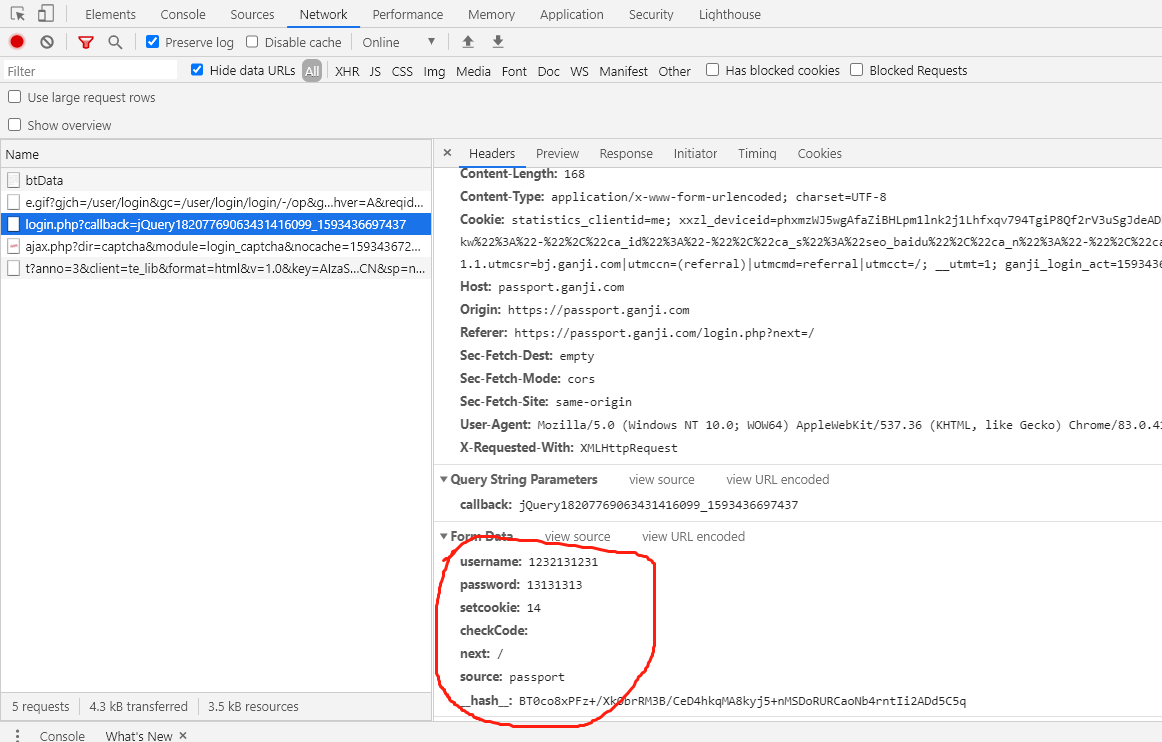 1.打开赶集网登录界面,先模拟登录并抓包,获得post请求的request参数2.我们只需构造出上面的参数传入formdata即可参数分析:setcookie:为自动登录所传的值,不勾选时默认为0。__hash__值的分析:只需要查看response网页源代码即可,然后用正则表达式提取。3.代码实现1.workon到自己的虚拟环境cmd切换到项目目录,输入scrapystartprojectganjiwangdenglu,然后就可以用pycharm打开该目录啦。2.在pycharmterminal中输...
1.打开赶集网登录界面,先模拟登录并抓包,获得post请求的request参数2.我们只需构造出上面的参数传入formdata即可参数分析:setcookie:为自动登录所传的值,不勾选时默认为0。__hash__值的分析:只需要查看response网页源代码即可,然后用正则表达式提取。3.代码实现1.workon到自己的虚拟环境cmd切换到项目目录,输入scrapystartprojectganjiwangdenglu,然后就可以用pycharm打开该目录啦。2.在pycharmterminal中输...
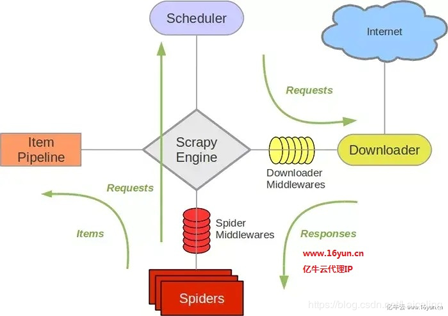 1、Scrapy框架Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。Scrapy使用了Twisted'twɪstɪd异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。ScrapyEngine(引擎):负...
1、Scrapy框架Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。Scrapy使用了Twisted'twɪstɪd异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。ScrapyEngine(引擎):负...
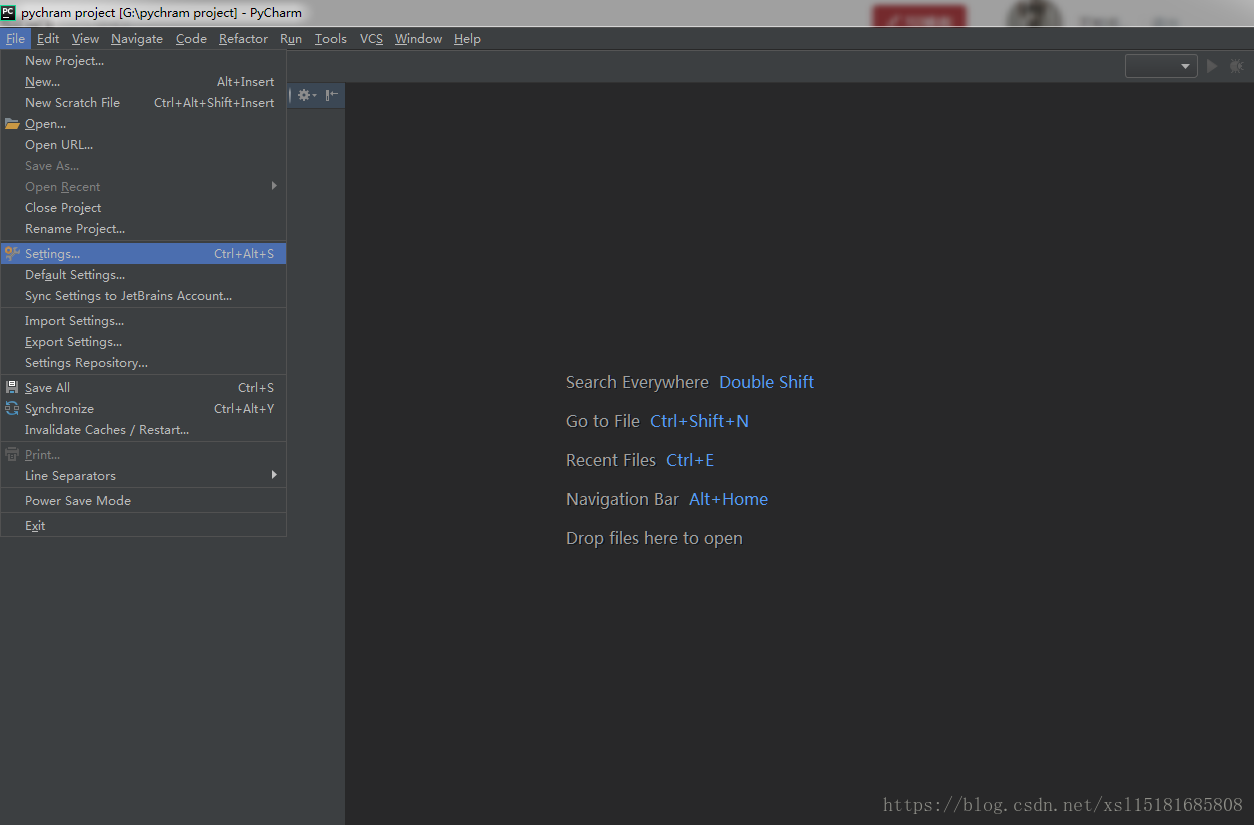 很多次遇到在pycharm中无法安装第三方库的情况,今天我就遇到了,找了很多办法都没用但是在pycharm中配置anaconda环境之后再从anaconda下载安装你所需要的库就可以diy完决你的问题了第一步安装anaconda,这个我就不说了,网上很多方法,自己找第二步配置anaconda环境到pycharm,这我来给你们说说打开pychram,file->settings 然后选择projectInterpreter把projectInterpreter复选...
很多次遇到在pycharm中无法安装第三方库的情况,今天我就遇到了,找了很多办法都没用但是在pycharm中配置anaconda环境之后再从anaconda下载安装你所需要的库就可以diy完决你的问题了第一步安装anaconda,这个我就不说了,网上很多方法,自己找第二步配置anaconda环境到pycharm,这我来给你们说说打开pychram,file->settings 然后选择projectInterpreter把projectInterpreter复选...
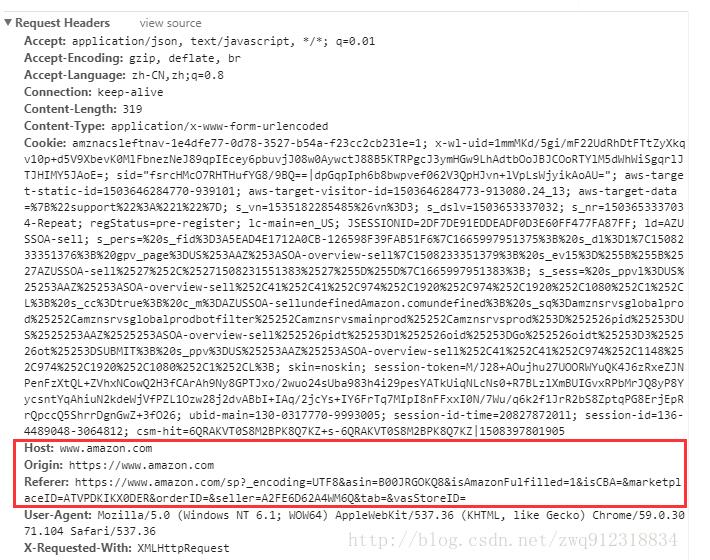 1.背景在网页爬取的时候,有时候会使用scrapy.FormRequest向目标网站提交数据(表单提交)。参照scrapy官方文档的标准写法是:#header信息unicornHeader={'Host':'www.example.com','Referer':'http://www.example.com/',}#表单需要提交的数据myFormData={'name':'JohnDoe','age':'27'}#自定义信息,向下层响应(response)传递下去customerData={'key1':'value1','key2':'value2'}yieldscrapy.FormRequest(...
1.背景在网页爬取的时候,有时候会使用scrapy.FormRequest向目标网站提交数据(表单提交)。参照scrapy官方文档的标准写法是:#header信息unicornHeader={'Host':'www.example.com','Referer':'http://www.example.com/',}#表单需要提交的数据myFormData={'name':'JohnDoe','age':'27'}#自定义信息,向下层响应(response)传递下去customerData={'key1':'value1','key2':'value2'}yieldscrapy.FormRequest(...