
2021
05-15
05-15
Selenium爬取b站主播头像并以昵称命名保存到本地
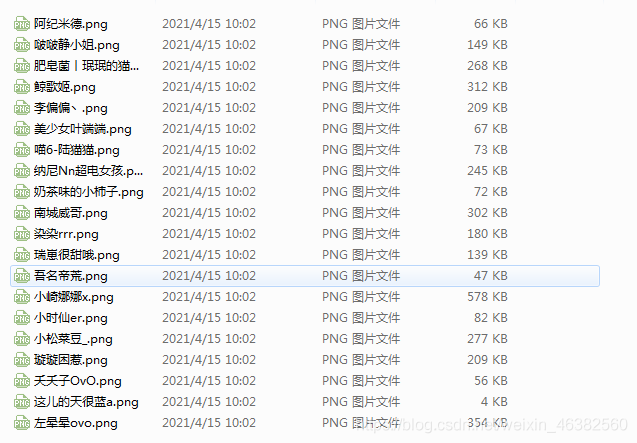 申明:资料来源于网络及书本,通过理解、实践、整理成学习笔记。Pythion的Selenium自动化测试之获取哔哩哔哩主播的头像以昵称命名保存到本地文件效果图方法1通过接口获取首先使用pip下载requests包pipinstallrequestsimportrequests#通过接口获取请求的接口:想要获取网页的urlurl='https://api.live.bilibili.com/xlive/web-interface/v1/second/getList?platform=web&parent_area_id=1&area_id=0&sort_type=sort_type_...
继续阅读 >
申明:资料来源于网络及书本,通过理解、实践、整理成学习笔记。Pythion的Selenium自动化测试之获取哔哩哔哩主播的头像以昵称命名保存到本地文件效果图方法1通过接口获取首先使用pip下载requests包pipinstallrequestsimportrequests#通过接口获取请求的接口:想要获取网页的urlurl='https://api.live.bilibili.com/xlive/web-interface/v1/second/getList?platform=web&parent_area_id=1&area_id=0&sort_type=sort_type_...
继续阅读 >
 1.背景我们在爬取网页时一般会使用到三个爬虫库:requests,scrapy,selenium。requests一般用于小型爬虫,scrapy用于构建大的爬虫项目,而selenium主要用来应付负责的页面(复杂js渲染的页面,请求非常难构造,或者构造方式经常变化)。在我们面对大型爬虫项目时,肯定会优选scrapy框架来开发,但是在解析复杂JS渲染的页面时,又很麻烦。尽管使用selenium浏览器渲染来抓取这样的页面很方便,这种方式下,我们不需要关心页面...
1.背景我们在爬取网页时一般会使用到三个爬虫库:requests,scrapy,selenium。requests一般用于小型爬虫,scrapy用于构建大的爬虫项目,而selenium主要用来应付负责的页面(复杂js渲染的页面,请求非常难构造,或者构造方式经常变化)。在我们面对大型爬虫项目时,肯定会优选scrapy框架来开发,但是在解析复杂JS渲染的页面时,又很麻烦。尽管使用selenium浏览器渲染来抓取这样的页面很方便,这种方式下,我们不需要关心页面...
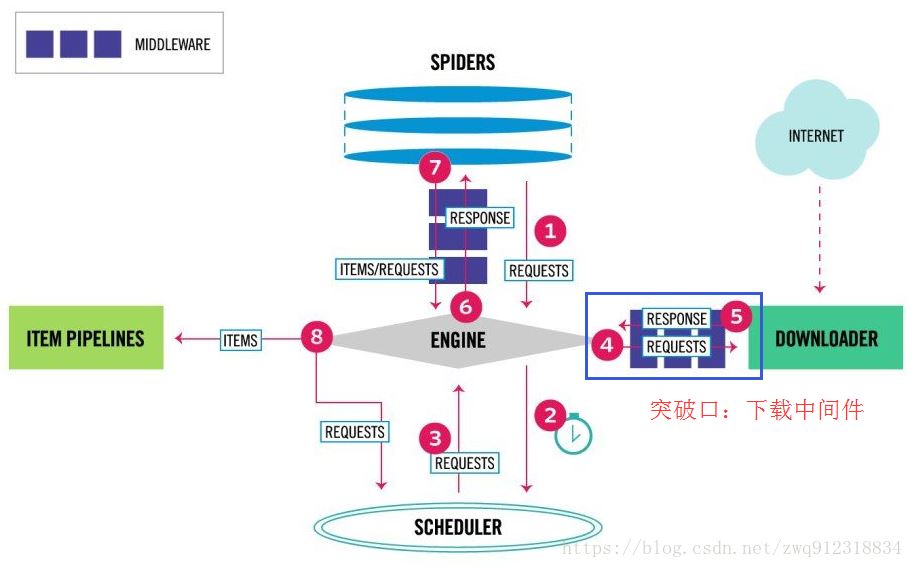
 scrapy框架只能爬取静态网站。如需爬取动态网站,需要结合着selenium进行js的渲染,才能获取到动态加载的数据。如何通过selenium请求url,而不再通过下载器Downloader去请求这个url?方法:在request对象通过中间件的时候,在中间件内部开始使用selenium去请求url,并且会得到url对应的源码,然后再将 源代码通过response对象返回,直接交给process_response()进行处理,再交给引擎。过程中相当于后续中间件的proc...
scrapy框架只能爬取静态网站。如需爬取动态网站,需要结合着selenium进行js的渲染,才能获取到动态加载的数据。如何通过selenium请求url,而不再通过下载器Downloader去请求这个url?方法:在request对象通过中间件的时候,在中间件内部开始使用selenium去请求url,并且会得到url对应的源码,然后再将 源代码通过response对象返回,直接交给process_response()进行处理,再交给引擎。过程中相当于后续中间件的proc...