
2021
10-17
10-17
Spark SQL的整体实现逻辑解析
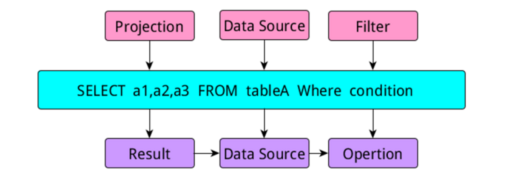 1、sql语句的模块解析 当我们写一个查询语句时,一般包含三个部分,select部分,from数据源部分,where限制条件部分,这三部分的内容在sql中有专门的名称:当我们写sql时,如上图所示,在进行逻辑解析时会把sql分成三个部分,project,DataSource,Filter模块,当生成执行部分时又把他们称为:Result模块、DataSource模块和Opertion模块。那么在关系数据库中,当我们写完一个查询语句进行执行时,发生的过程如下图所示...
继续阅读 >
1、sql语句的模块解析 当我们写一个查询语句时,一般包含三个部分,select部分,from数据源部分,where限制条件部分,这三部分的内容在sql中有专门的名称:当我们写sql时,如上图所示,在进行逻辑解析时会把sql分成三个部分,project,DataSource,Filter模块,当生成执行部分时又把他们称为:Result模块、DataSource模块和Opertion模块。那么在关系数据库中,当我们写完一个查询语句进行执行时,发生的过程如下图所示...
继续阅读 >
 今天在intellij调试spark的时候感觉每次有新的一段代码,都要重新跑一遍,如果用spark-shell,感觉也不是特别方便,如果能像python那样,使用jupyternotebook进行编程就很方便了,同时也适合代码展示,网上查了一下,试了一下,碰到了很多坑,有些是旧的版本,还有些是版本不同导致错误,这里就记录下来安装的过程。1.运行环境硬件:Mac事先装好:Jupyternotebook,spark2.1.0,scala2.11.8(这个版本很重要,关系到后面的安装...
今天在intellij调试spark的时候感觉每次有新的一段代码,都要重新跑一遍,如果用spark-shell,感觉也不是特别方便,如果能像python那样,使用jupyternotebook进行编程就很方便了,同时也适合代码展示,网上查了一下,试了一下,碰到了很多坑,有些是旧的版本,还有些是版本不同导致错误,这里就记录下来安装的过程。1.运行环境硬件:Mac事先装好:Jupyternotebook,spark2.1.0,scala2.11.8(这个版本很重要,关系到后面的安装...