
2020
10-10
10-10
Scrapy中如何向Spider传入参数的方法实现
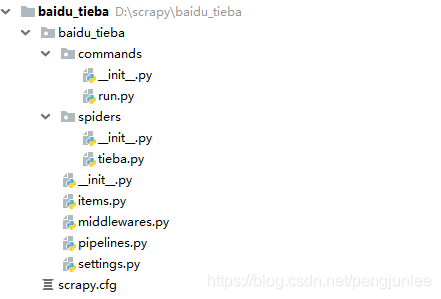 在使用Scrapy爬取数据时,有时会碰到需要根据传递给Spider的参数来决定爬取哪些Url或者爬取哪些页的情况。例如,百度贴吧的放置奇兵吧的地址如下,其中kw参数用来指定贴吧名称、pn参数用来对帖子进行翻页。https://tieba.baidu.com/f?kw=放置奇兵&ie=utf-8&pn=250如果我们希望通过参数传递的方式将贴吧名称和页数等参数传给Spider,来控制我们要爬取哪一个贴吧、爬取哪些页。遇到这种情况,有以下两种方法向Spider传递参数。...
继续阅读 >
在使用Scrapy爬取数据时,有时会碰到需要根据传递给Spider的参数来决定爬取哪些Url或者爬取哪些页的情况。例如,百度贴吧的放置奇兵吧的地址如下,其中kw参数用来指定贴吧名称、pn参数用来对帖子进行翻页。https://tieba.baidu.com/f?kw=放置奇兵&ie=utf-8&pn=250如果我们希望通过参数传递的方式将贴吧名称和页数等参数传给Spider,来控制我们要爬取哪一个贴吧、爬取哪些页。遇到这种情况,有以下两种方法向Spider传递参数。...
继续阅读 >
 一、网络爬虫网络爬虫又被称为网络蜘蛛(🕷️),我们可以把互联网想象成一个蜘蛛网,每一个网站都是一个节点,我们可以使用一只蜘蛛去各个网页抓取我们想要的资源。举一个最简单的例子,你在百度和谷歌中输入‘Python',会有大量和Python相关的网页被检索出来,百度和谷歌是如何从海量的网页中检索出你想要的资源,他们靠的就是派出大量蜘蛛去网页上爬取,检索关键字,建立索引数据库,经过复杂的排序算法,结果按照...
一、网络爬虫网络爬虫又被称为网络蜘蛛(🕷️),我们可以把互联网想象成一个蜘蛛网,每一个网站都是一个节点,我们可以使用一只蜘蛛去各个网页抓取我们想要的资源。举一个最简单的例子,你在百度和谷歌中输入‘Python',会有大量和Python相关的网页被检索出来,百度和谷歌是如何从海量的网页中检索出你想要的资源,他们靠的就是派出大量蜘蛛去网页上爬取,检索关键字,建立索引数据库,经过复杂的排序算法,结果按照...