
2021
07-31
07-31
pytorch 运行一段时间后出现GPU OOM的问题
pytorch的dataloader会将数据传到GPU上,这个过程GPU的mem占用会逐渐增加,为了避免GPUmen被无用的数据占用,可以在每个step后用del删除一些变量,也可以使用torch.cuda.empty_cache()释放显存:deltargets,input_k,input_masktorch.cuda.empty_cache()这时能观察到GPU的显存一直在动态变化。但是上述方式不是一个根本的解决方案,因为他受到峰值的影响很大。比如某个batch的数据量明显大于其他batch,可能模型处理该batch时显...
继续阅读 >
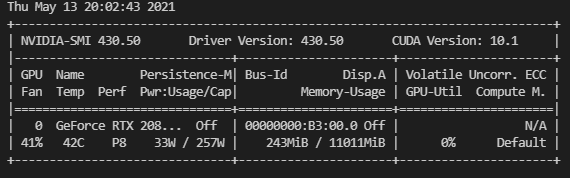 服务器环境:Ubuntu16.04.7显卡:2080cuda:10.1注:若服务器有管理员账户和个人账户,最好在个人账户下重新安装anaconda,否则安装pytorch过程中可能有些库安装失败,由于权限问题,不能删除这些失败的库重新安装。在个人账户下就不存在权限问题。一添加镜像源目的:使用默认的源地址下载速度很慢,会出现超时,导致某些第三方库只下载了部分,不完整,最终失败。首先查看当前镜像源cat~/.condarc或者condaconfig--showchann...
服务器环境:Ubuntu16.04.7显卡:2080cuda:10.1注:若服务器有管理员账户和个人账户,最好在个人账户下重新安装anaconda,否则安装pytorch过程中可能有些库安装失败,由于权限问题,不能删除这些失败的库重新安装。在个人账户下就不存在权限问题。一添加镜像源目的:使用默认的源地址下载速度很慢,会出现超时,导致某些第三方库只下载了部分,不完整,最终失败。首先查看当前镜像源cat~/.condarc或者condaconfig--showchann...
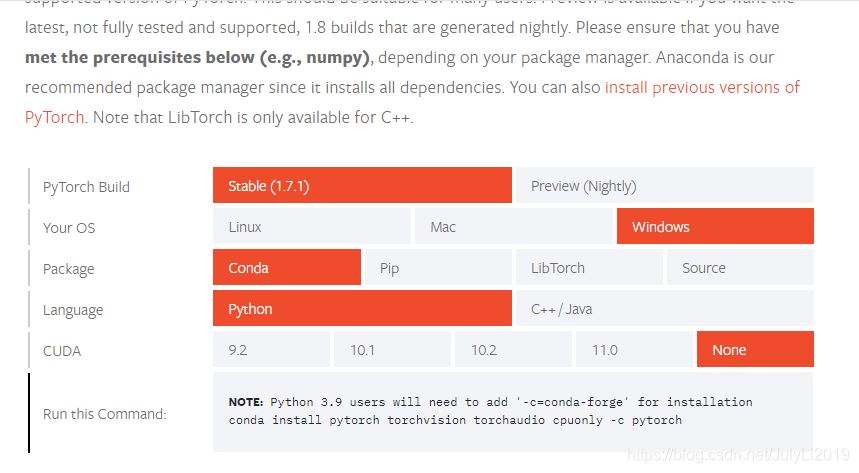 前言最近实习任务为黑烟检测,想起了可以尝试用yolov5来跑下,之前一直都是用的RCNN系列,这次就试试yolo系列。一、安装pytorch1.创建新的环境打开AnacondaPrompt命令行输入创建一个新环境,并激活进入环境。#创建了名叫yolov5的,python版本为3.8的新环境condacreate-nyolov5python=3.8#激活名叫yolov5的环境condaactivateyolov52.下载YOLOv5github项目下载地址为:https://github.com/ultralytics/yolov5如果安装了gi...
前言最近实习任务为黑烟检测,想起了可以尝试用yolov5来跑下,之前一直都是用的RCNN系列,这次就试试yolo系列。一、安装pytorch1.创建新的环境打开AnacondaPrompt命令行输入创建一个新环境,并激活进入环境。#创建了名叫yolov5的,python版本为3.8的新环境condacreate-nyolov5python=3.8#激活名叫yolov5的环境condaactivateyolov52.下载YOLOv5github项目下载地址为:https://github.com/ultralytics/yolov5如果安装了gi...
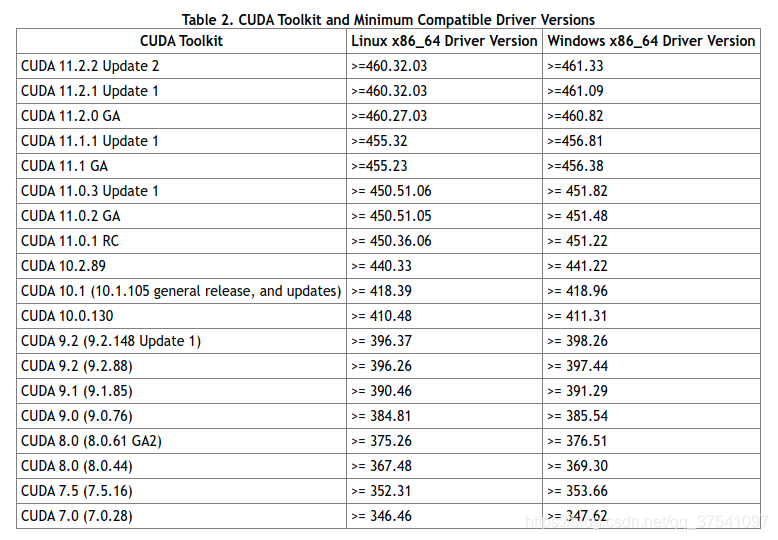 先说下自己之前的环境(都是Linux系统,差别不大):Centos7.6NVIDIADriverVersion440.33.01(等会需要更新驱动)CUDA10.1Pytorch1.6/1.7提示,如果想要保留之前的PyTorch1.6或1.7的环境,请不要卸载CUDA环境,可以通过Anaconda管理不同的环境,互不影响。但是需要注意你的NVIDIA驱动版本是否匹配。在这里能够看到官方给的对应CUDA版本所需使用驱动版本。通过上表可以发现,如果要使用CUDA11.1,那么需要将显卡的驱动更...
先说下自己之前的环境(都是Linux系统,差别不大):Centos7.6NVIDIADriverVersion440.33.01(等会需要更新驱动)CUDA10.1Pytorch1.6/1.7提示,如果想要保留之前的PyTorch1.6或1.7的环境,请不要卸载CUDA环境,可以通过Anaconda管理不同的环境,互不影响。但是需要注意你的NVIDIA驱动版本是否匹配。在这里能够看到官方给的对应CUDA版本所需使用驱动版本。通过上表可以发现,如果要使用CUDA11.1,那么需要将显卡的驱动更...
 训练的时候当然用gpu,速度快呀。我想用cpu版的tensorflow跑一下,结果报错,这个错误不太容易看懂。大概意思是没找到一些节点。后来发现原因,用gpu和cpu保存的pb模型不太一样,但是checkpoints文件是通用的。使用tensorflow-cpu再把checkpoints文件重新转换一下pb文件就可以了。完美解决!补充:tensflow-gpu版的无数坑坑坑!(tf坑大总结)自己的小本本,之前预装有的pycharm+win10+anaconda3+python3的环境2019/3/24重新安装发...
训练的时候当然用gpu,速度快呀。我想用cpu版的tensorflow跑一下,结果报错,这个错误不太容易看懂。大概意思是没找到一些节点。后来发现原因,用gpu和cpu保存的pb模型不太一样,但是checkpoints文件是通用的。使用tensorflow-cpu再把checkpoints文件重新转换一下pb文件就可以了。完美解决!补充:tensflow-gpu版的无数坑坑坑!(tf坑大总结)自己的小本本,之前预装有的pycharm+win10+anaconda3+python3的环境2019/3/24重新安装发...
 之前摸索tensorflow的时候安装踩坑的时间非常久,主要是没搞懂几个东西的关系,就在瞎调试,以及当时很多东西不懂,很多报错也一知半解的。这次重装系统后正好需要再配置一次,把再一次的经历记录一下。我的电脑是华为的matebook13,inteli5-8625U,MX250显卡,win10系统。(不得不吐槽很垃圾,只能满足测试测试调调代码的需求)深度学习利用Tensorflow平台,其中的KerasSequentialAPI对新用户非常的友好,可以将各基础组件组合...
之前摸索tensorflow的时候安装踩坑的时间非常久,主要是没搞懂几个东西的关系,就在瞎调试,以及当时很多东西不懂,很多报错也一知半解的。这次重装系统后正好需要再配置一次,把再一次的经历记录一下。我的电脑是华为的matebook13,inteli5-8625U,MX250显卡,win10系统。(不得不吐槽很垃圾,只能满足测试测试调调代码的需求)深度学习利用Tensorflow平台,其中的KerasSequentialAPI对新用户非常的友好,可以将各基础组件组合...
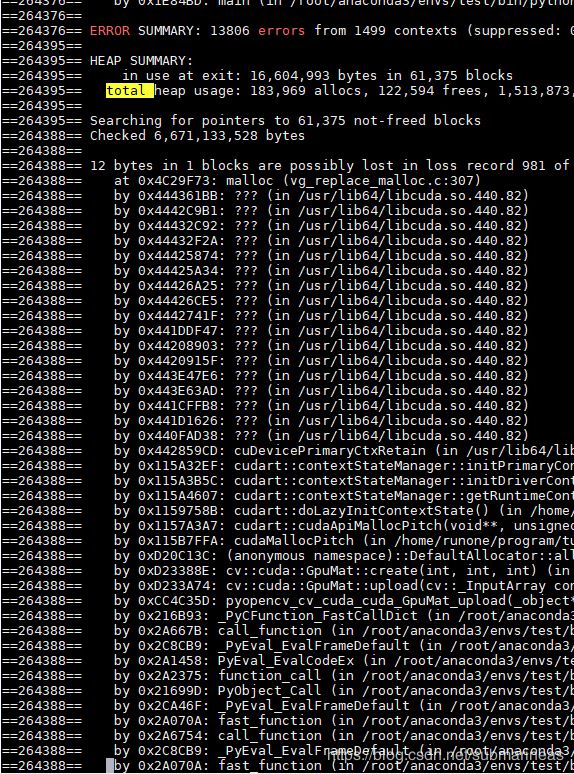 引言本篇是以python的视角介绍相关的函数还有自我使用中的一些问题,本想在这篇之前总结一下opencv编译的全过程,但遇到了太多坑,暂时不太想回看做过的笔记,所以这里主要总结python下GPU版本的opencv。主要函数说明threshold():二值化,但要指定设定阈值blendLinear():两幅图片的线形混合calcHist()createBoxFilter():创建一个规范化的2D框过滤器canny边缘检测createGaussianFilter():创建一个Gaussian过滤器createLaplacia...
引言本篇是以python的视角介绍相关的函数还有自我使用中的一些问题,本想在这篇之前总结一下opencv编译的全过程,但遇到了太多坑,暂时不太想回看做过的笔记,所以这里主要总结python下GPU版本的opencv。主要函数说明threshold():二值化,但要指定设定阈值blendLinear():两幅图片的线形混合calcHist()createBoxFilter():创建一个规范化的2D框过滤器canny边缘检测createGaussianFilter():创建一个Gaussian过滤器createLaplacia...
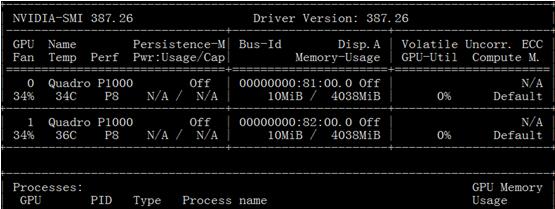 前言深度学习涉及很多向量或多矩阵运算,如矩阵相乘、矩阵相加、矩阵-向量乘法等。深层模型的算法,如BP,Auto-Encoder,CNN等,都可以写成矩阵运算的形式,无须写成循环运算。然而,在单核CPU上执行时,矩阵运算会被展开成循环的形式,本质上还是串行执行。GPU(GraphicProcessUnits,图形处理器)的众核体系结构包含几千个流处理器,可将矩阵运算并行化执行,大幅缩短计算时间。随着NVIDIA、AMD等公司不断推进其GPU的大规模并...
前言深度学习涉及很多向量或多矩阵运算,如矩阵相乘、矩阵相加、矩阵-向量乘法等。深层模型的算法,如BP,Auto-Encoder,CNN等,都可以写成矩阵运算的形式,无须写成循环运算。然而,在单核CPU上执行时,矩阵运算会被展开成循环的形式,本质上还是串行执行。GPU(GraphicProcessUnits,图形处理器)的众核体系结构包含几千个流处理器,可将矩阵运算并行化执行,大幅缩短计算时间。随着NVIDIA、AMD等公司不断推进其GPU的大规模并...
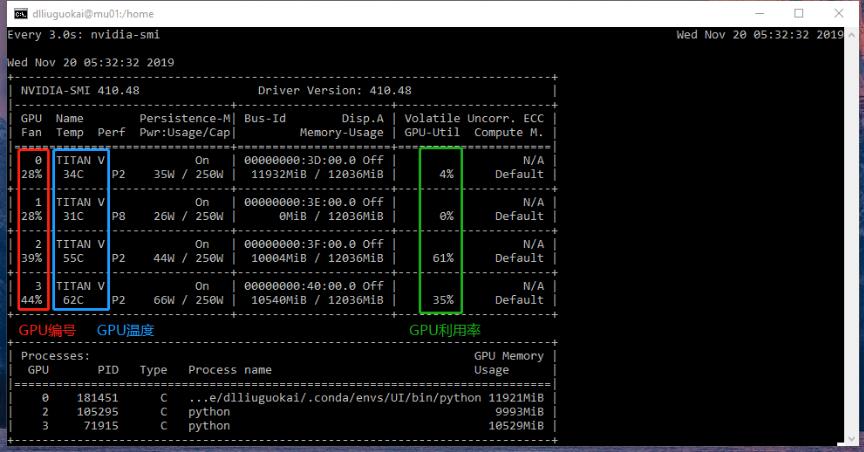 初步尝试Keras(基于Tensorflow后端)深度框架时,发现其对于GPU的使用比较神奇,默认竟然是全部占满显存,1080Ti跑个小分类问题,就一下子满了.而且是服务器上的两张1080Ti.服务器上的多张GPU都占满,有点浪费性能.因此,需要类似于Caffe等框架的可以设定GPUID和显存自动按需分配.实际中发现,Keras还可以限制GPU显存占用量.这里涉及到的内容有:GPUID设定GPU显存占用按需分配GPU显存占用限制GPU显存优化1....
初步尝试Keras(基于Tensorflow后端)深度框架时,发现其对于GPU的使用比较神奇,默认竟然是全部占满显存,1080Ti跑个小分类问题,就一下子满了.而且是服务器上的两张1080Ti.服务器上的多张GPU都占满,有点浪费性能.因此,需要类似于Caffe等框架的可以设定GPUID和显存自动按需分配.实际中发现,Keras还可以限制GPU显存占用量.这里涉及到的内容有:GPUID设定GPU显存占用按需分配GPU显存占用限制GPU显存优化1....
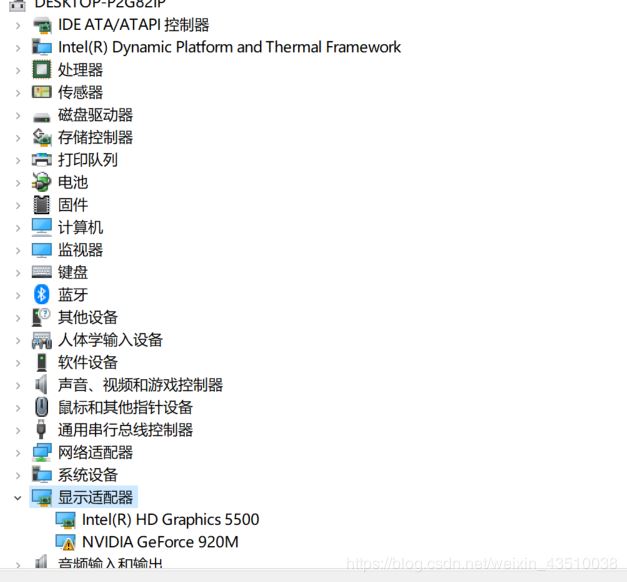 1、查看自己电脑是否匹配GPU版本。设备管理器查看。查看官网是否匹配。地址:https://developer.nvidia.com/cuda-gpus **2、进入NVIDIA对电脑版本进行查**看。如果可以的的话可以自己卸载原来版本,后安装新版本。安装地址https://developer.nvidia.com/cuda-toolkit-archive接下来,进入NVIDIA安装过程,在这安装过程中,我一开始直接选择的精简安装,但由于VS的原因,导致无法正常安装,于是我换成了自定义的安装方式,并...
1、查看自己电脑是否匹配GPU版本。设备管理器查看。查看官网是否匹配。地址:https://developer.nvidia.com/cuda-gpus **2、进入NVIDIA对电脑版本进行查**看。如果可以的的话可以自己卸载原来版本,后安装新版本。安装地址https://developer.nvidia.com/cuda-toolkit-archive接下来,进入NVIDIA安装过程,在这安装过程中,我一开始直接选择的精简安装,但由于VS的原因,导致无法正常安装,于是我换成了自定义的安装方式,并...