
2022
05-20
05-20
带你了解HDFS的Namenode 高可用机制
目录HDFSNameNode高可用HadoopNamenode高可用架构Namenode高可用的实现隔离(Fencing)QJM共享存储HDFSNameNode高可用在Hadoop2.0.0之前,一个集群只有一个Namenode,这将面临单点故障问题。如果Namenode机器挂掉了,整个集群就用不了了。只有重启Namenode,才能恢复集群。另外正常计划维护集群的时候,还必须先停用整个集群,这样没办法达到7*24小时可用状态。Hadoop2.0及之后版本增加了Namenode高可用机制...
继续阅读 >
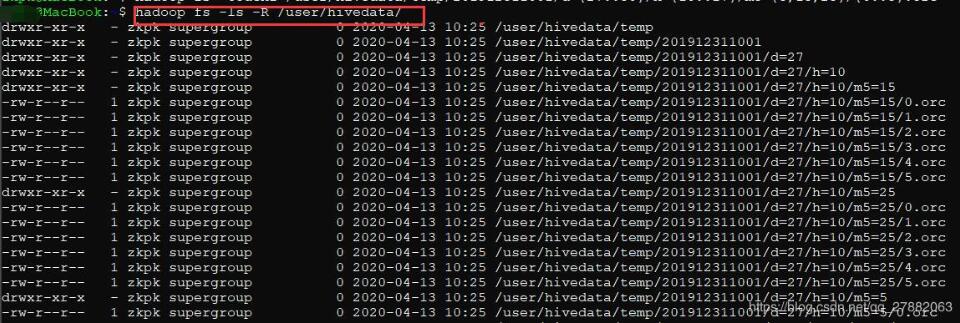 之前一直使用hdfs的命令进行hdfs操作,比如:hdfsdfs-ls/user/spark/hdfsdfs-get/user/spark/a.txt/home/spark/a.txt#从HDFS获取数据到本地hdfsdfs-put-f/home/spark/a.txt/user/spark/a.txt#从本地覆盖式上传hdfsdfs-mkdir-p/user/spark/home/datetime=20180817/....身为一个python程序员,每天操作hdfs都是在程序中写各种cmd调用的命令,一方面不好看,另一方面身为一个Pythoner这是一个耻辱,于是乎就挑了一...
之前一直使用hdfs的命令进行hdfs操作,比如:hdfsdfs-ls/user/spark/hdfsdfs-get/user/spark/a.txt/home/spark/a.txt#从HDFS获取数据到本地hdfsdfs-put-f/home/spark/a.txt/user/spark/a.txt#从本地覆盖式上传hdfsdfs-mkdir-p/user/spark/home/datetime=20180817/....身为一个python程序员,每天操作hdfs都是在程序中写各种cmd调用的命令,一方面不好看,另一方面身为一个Pythoner这是一个耻辱,于是乎就挑了一...
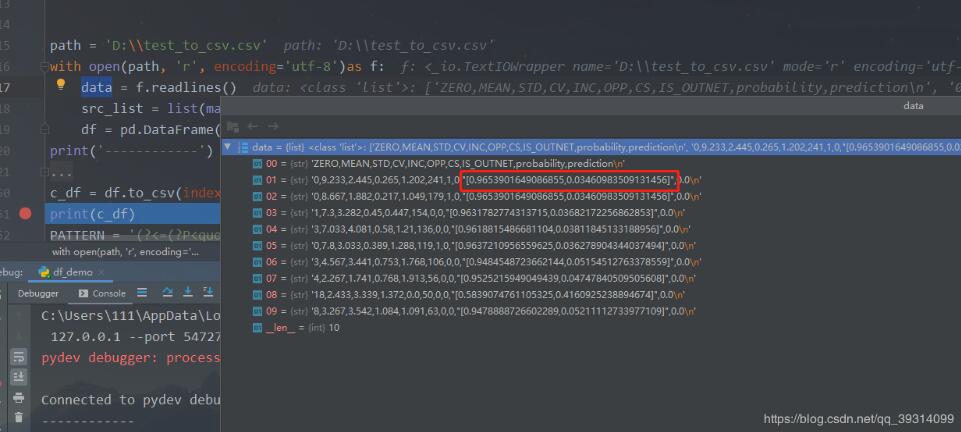 1.目标通过hadoophive或spark等数据计算框架完成数据清洗后的数据在HDFS上爬虫和机器学习在Python中容易实现在Linux环境下编写Python没有pyCharm便利需要建立Python与HDFS的读写通道2.实现安装Python模块pyhdfs版本:Python3.6,hadoop2.9读文件代码如下frompyhdfsimportHdfsClientclient=HdfsClient(hosts='ghym:50070')#hdfs地址res=client.open('/sy.txt')#hdfs文件路径,根目录/forrinres:line=str(r,encoding='utf8'...
1.目标通过hadoophive或spark等数据计算框架完成数据清洗后的数据在HDFS上爬虫和机器学习在Python中容易实现在Linux环境下编写Python没有pyCharm便利需要建立Python与HDFS的读写通道2.实现安装Python模块pyhdfs版本:Python3.6,hadoop2.9读文件代码如下frompyhdfsimportHdfsClientclient=HdfsClient(hosts='ghym:50070')#hdfs地址res=client.open('/sy.txt')#hdfs文件路径,根目录/forrinres:line=str(r,encoding='utf8'...
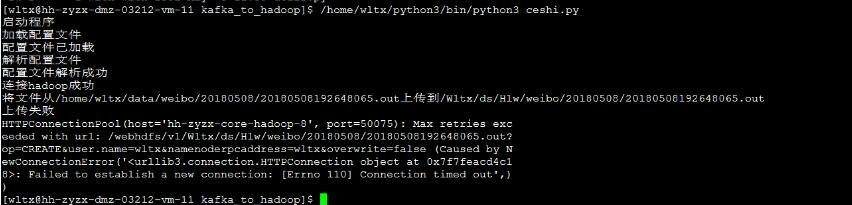 当我们使用python的hdfs包进行上传和下载文件的时候,总会出现如下问题requests.packages.urllib3.exceptions.NewConnectionError:<requests.packages.urllib3.connection.HTTPConnectionobjectat0x7fe87cc37c50>:Failedtoestablishanewconnection:[Errno-2]Nameorservicenotknown其实这主要是由于没有将各个集群节点的ip映射到/etc/hosts文件中修改/etc/hosts文件,将各个集群节点ip映射加上即可,如博主所示vim...
当我们使用python的hdfs包进行上传和下载文件的时候,总会出现如下问题requests.packages.urllib3.exceptions.NewConnectionError:<requests.packages.urllib3.connection.HTTPConnectionobjectat0x7fe87cc37c50>:Failedtoestablishanewconnection:[Errno-2]Nameorservicenotknown其实这主要是由于没有将各个集群节点的ip映射到/etc/hosts文件中修改/etc/hosts文件,将各个集群节点ip映射加上即可,如博主所示vim...
 CDNCDN系统能够实时地根据网络流量和各节点的连接、负载状况以及到用户的距离和响应时间等综合信息将用户的请求重新导向离用户最近的服务节点上。其目的是使用户可就近取得所需内容,解决Internet网络拥挤的状况,提高用户访问网站的响应速度。对于大规模电子商务平台一般需要建CDN做网络加速,大型平台如淘宝、京东都采用自建CDN,中小型的企业可以采用第三方CDN厂商合作,如蓝汛、网宿、快网等。当然在选择CDN厂商时,需要考...
CDNCDN系统能够实时地根据网络流量和各节点的连接、负载状况以及到用户的距离和响应时间等综合信息将用户的请求重新导向离用户最近的服务节点上。其目的是使用户可就近取得所需内容,解决Internet网络拥挤的状况,提高用户访问网站的响应速度。对于大规模电子商务平台一般需要建CDN做网络加速,大型平台如淘宝、京东都采用自建CDN,中小型的企业可以采用第三方CDN厂商合作,如蓝汛、网宿、快网等。当然在选择CDN厂商时,需要考...