
2022
05-30
05-30
一篇文章教会你使用java爬取想要的资源
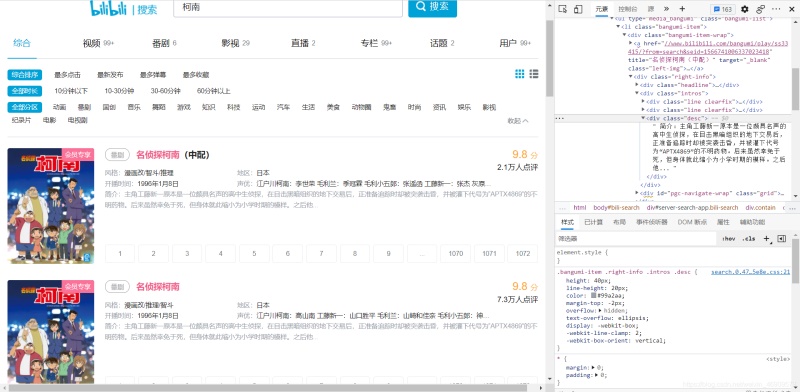 目录说明方法摘要常用的Element节点方法实战:爬取B站番剧Maven代码说明简介:你还在为想要的资源而获取不到而烦劳吗?你还在为你不会python而爬取不到资源而烦劳吗?没关系,看完我这一篇文章你就会学会用java爬取资源,从此不会因此而烦劳,下面我会以爬取京东物品来进行实战演示!!!方法摘要方法方法说明adoptNode(Nodesource)试图把另一文档...
继续阅读 >
目录说明方法摘要常用的Element节点方法实战:爬取B站番剧Maven代码说明简介:你还在为想要的资源而获取不到而烦劳吗?你还在为你不会python而爬取不到资源而烦劳吗?没关系,看完我这一篇文章你就会学会用java爬取资源,从此不会因此而烦劳,下面我会以爬取京东物品来进行实战演示!!!方法摘要方法方法说明adoptNode(Nodesource)试图把另一文档...
继续阅读 >
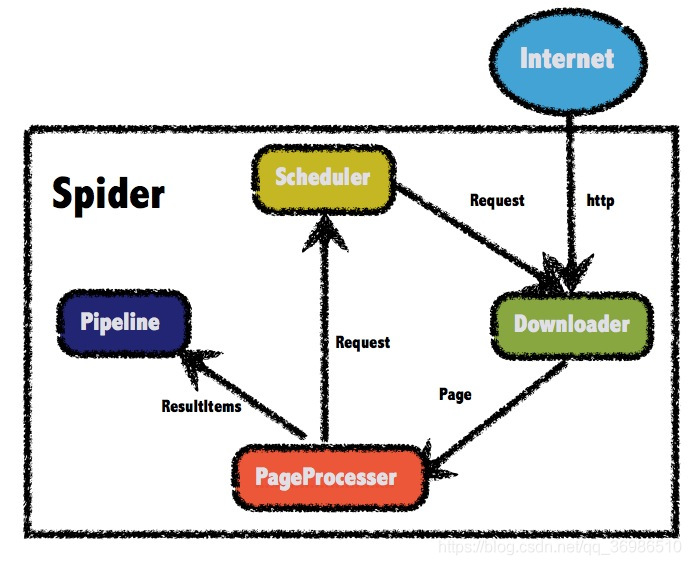 一、Java爬虫——WebMagic 1.1WebMagic总体架构图1.2WebMagic核心组件1.2.1Downloader该组件负责从互联网上下载页面。WebMagic默认使用ApacheHttpClient作为下载工具。1.2.2PageProcessor该组件负责解析页面,根据我们的业务进行抽取信息。WebMagic使用Jsoup作为HTML解析工具,并基于其开发了解析Xpath的工具Xsoup。1.2.3Scheduler该组件负责管理待抓取的URL,以及去重的工作。WebMagic默认使用JDK内存队列管理URL,通...
一、Java爬虫——WebMagic 1.1WebMagic总体架构图1.2WebMagic核心组件1.2.1Downloader该组件负责从互联网上下载页面。WebMagic默认使用ApacheHttpClient作为下载工具。1.2.2PageProcessor该组件负责解析页面,根据我们的业务进行抽取信息。WebMagic使用Jsoup作为HTML解析工具,并基于其开发了解析Xpath的工具Xsoup。1.2.3Scheduler该组件负责管理待抓取的URL,以及去重的工作。WebMagic默认使用JDK内存队列管理URL,通...
 接着上面一篇对爬虫需要的java知识,这一篇目的就是在于网络爬虫的实现,对数据的获取,以便分析。----->爬虫实现原理网络爬虫基本技术处理网络爬虫是数据采集的一种方法,实际项目开发中,通过爬虫做数据采集一般只有以下几种情况:1)搜索引擎2)竞品调研3)舆情监控4)市场分析网络爬虫的整体执行流程:1)确定一个(多个)种子网页2)进行数据的内容提取3)将网页中的关联网页连接提取出来4)将尚未爬取的关联网页内容放到一个...
接着上面一篇对爬虫需要的java知识,这一篇目的就是在于网络爬虫的实现,对数据的获取,以便分析。----->爬虫实现原理网络爬虫基本技术处理网络爬虫是数据采集的一种方法,实际项目开发中,通过爬虫做数据采集一般只有以下几种情况:1)搜索引擎2)竞品调研3)舆情监控4)市场分析网络爬虫的整体执行流程:1)确定一个(多个)种子网页2)进行数据的内容提取3)将网页中的关联网页连接提取出来4)将尚未爬取的关联网页内容放到一个...
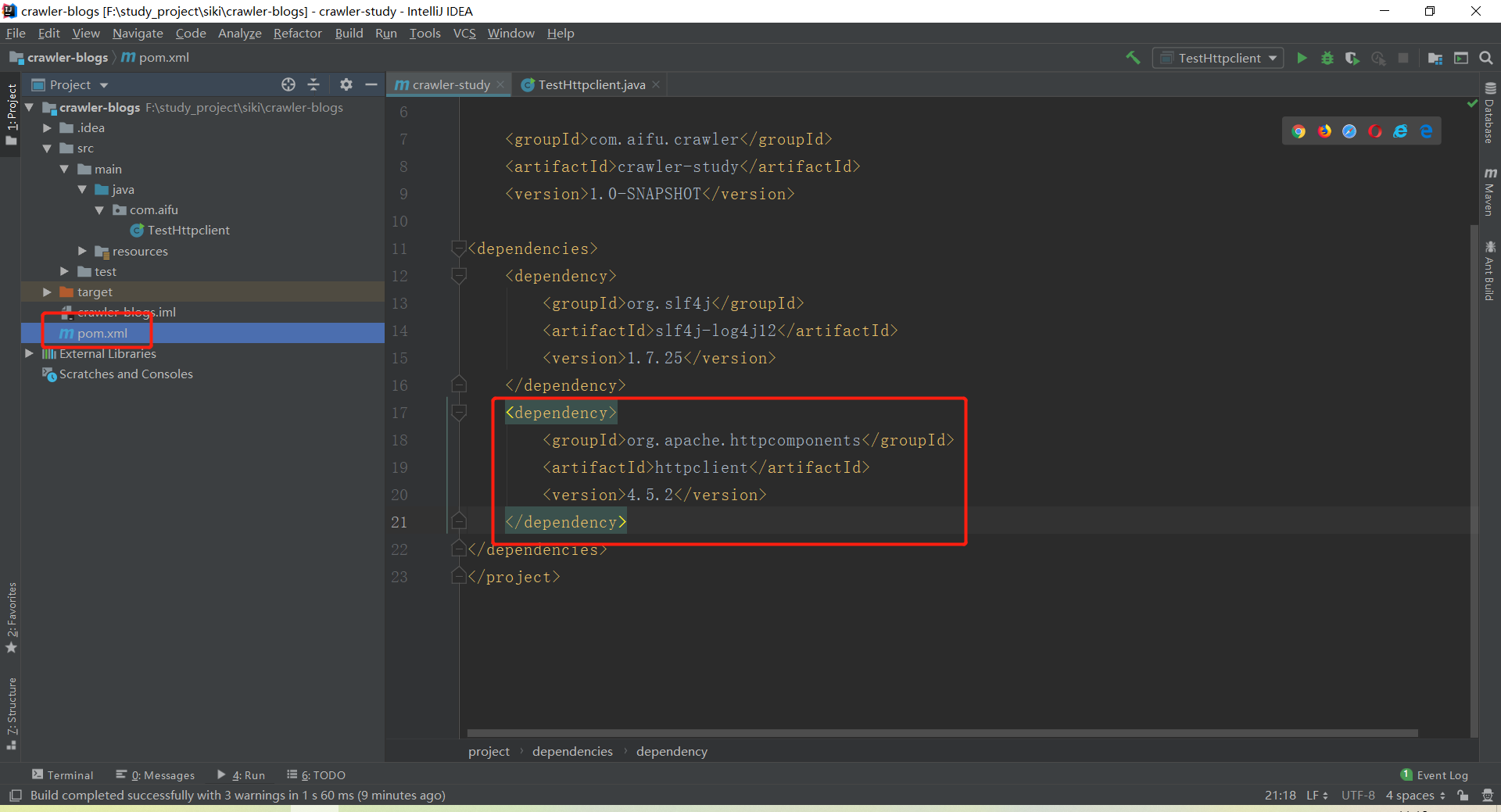 0.摘要0.1添加依赖<dependency><groupId>org.apache.httpcomponents</groupId><artifactId>httpclient</artifactId><version>4.5.2</version></dependency>0.2代码//1.打开浏览器创建httpclient对象CloseableHttpClienthttpClient=HttpClients.createDefault();//2.输入网址HttpGethttpGet=newHttpGet("http://www.baidu.com");//3.发送请求CloseableHttpResponsehttpResponse=httpClient.execute(httpGet)...
0.摘要0.1添加依赖<dependency><groupId>org.apache.httpcomponents</groupId><artifactId>httpclient</artifactId><version>4.5.2</version></dependency>0.2代码//1.打开浏览器创建httpclient对象CloseableHttpClienthttpClient=HttpClients.createDefault();//2.输入网址HttpGethttpGet=newHttpGet("http://www.baidu.com");//3.发送请求CloseableHttpResponsehttpResponse=httpClient.execute(httpGet)...