
2021
03-24
03-24
python 基于空间相似度的K-means轨迹聚类的实现
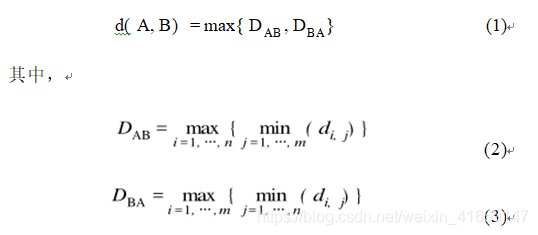 这里分享一些轨迹聚类的基本方法,涉及轨迹距离的定义、kmeans聚类应用。需要使用的python库如下importpandasaspdimportnumpyasnpimportrandomimportosimportmatplotlib.pyplotaspltimportseabornassnsfromscipy.spatial.distanceimportcdistfromitertoolsimportcombinationsfromjoblibimportParallel,delayedfromtqdmimporttqdm数据读取假设数据是每一条轨迹一个excel文件,包括经纬度、速度、方向的...
继续阅读 >
这里分享一些轨迹聚类的基本方法,涉及轨迹距离的定义、kmeans聚类应用。需要使用的python库如下importpandasaspdimportnumpyasnpimportrandomimportosimportmatplotlib.pyplotaspltimportseabornassnsfromscipy.spatial.distanceimportcdistfromitertoolsimportcombinationsfromjoblibimportParallel,delayedfromtqdmimporttqdm数据读取假设数据是每一条轨迹一个excel文件,包括经纬度、速度、方向的...
继续阅读 >
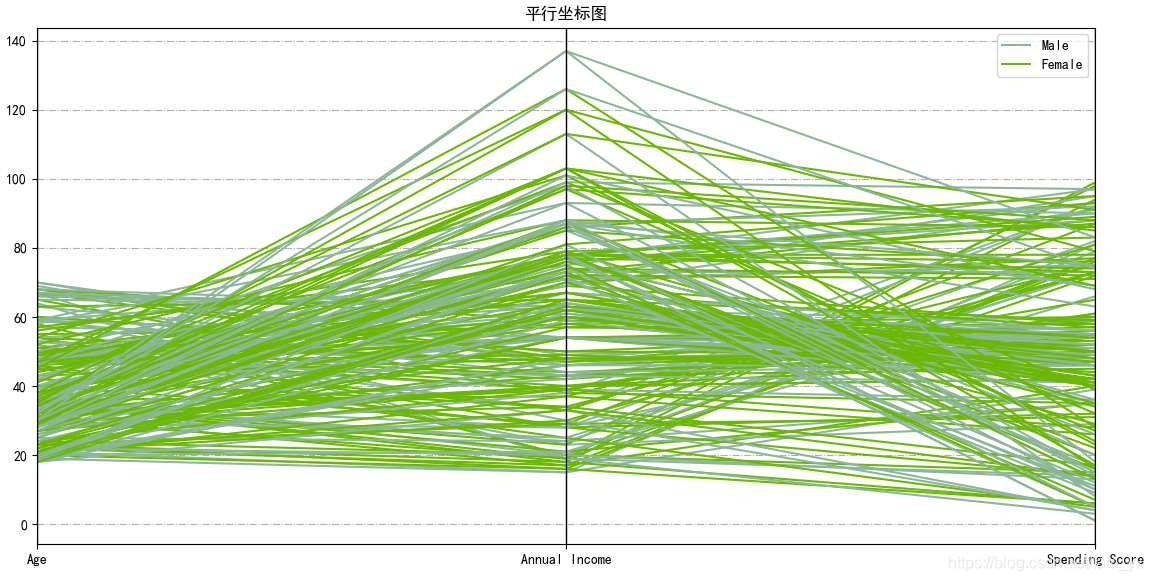 一、背景1.项目描述你拥有一个超市(SupermarketMall)。通过会员卡,你用有一些关于你的客户的基本数据,如客户ID,年龄,性别,年收入和消费分数。消费分数是根据客户行为和购买数据等定义的参数分配给客户的。问题陈述:你拥有这个商场。想要了解怎么样的顾客可以很容易地聚集在一起(目标顾客),以便可以给营销团队以灵感并相应地计划策略。2.数据描述字段名描述CustomerID客...
一、背景1.项目描述你拥有一个超市(SupermarketMall)。通过会员卡,你用有一些关于你的客户的基本数据,如客户ID,年龄,性别,年收入和消费分数。消费分数是根据客户行为和购买数据等定义的参数分配给客户的。问题陈述:你拥有这个商场。想要了解怎么样的顾客可以很容易地聚集在一起(目标顾客),以便可以给营销团队以灵感并相应地计划策略。2.数据描述字段名描述CustomerID客...
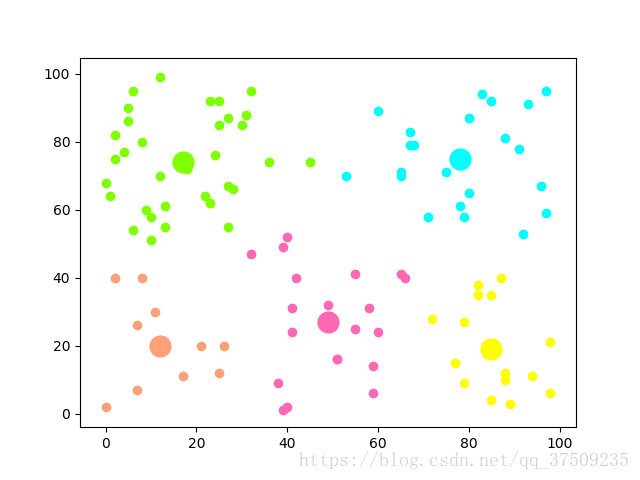 k-means聚类算法思想先随机选择k个聚类中心,把集合里的元素与最近的聚类中心聚为一类,得到一次聚类,再把每一个类的均值作为新的聚类中心重新聚类,迭代n次得到最终结果分步解析一、初始化聚类中心首先随机选择集合里的一个元素作为第一个聚类中心放入容器,选择距离第一个聚类中心最远的一个元素作为第二个聚类中心放入容器,第三、四、、、N个同理,为了优化可以选择距离开方做为评判标准二、迭代聚类依次把集合里的元素与距...
k-means聚类算法思想先随机选择k个聚类中心,把集合里的元素与最近的聚类中心聚为一类,得到一次聚类,再把每一个类的均值作为新的聚类中心重新聚类,迭代n次得到最终结果分步解析一、初始化聚类中心首先随机选择集合里的一个元素作为第一个聚类中心放入容器,选择距离第一个聚类中心最远的一个元素作为第二个聚类中心放入容器,第三、四、、、N个同理,为了优化可以选择距离开方做为评判标准二、迭代聚类依次把集合里的元素与距...
 本文实例为大家分享了Python实点云分割k-means(sklearn),供大家参考,具体内容如下植物叶片分割importnumpyasnpimportmatplotlib.pyplotaspltimportpandasaspdfromsklearn.clusterimportKMeansfromsklearn.preprocessingimportStandardScalerfrommpl_toolkits.mplot3dimportAxes3Ddata=pd.read_csv("jiaaobo1.txt",sep="")data1=data.iloc[:,0:3]#标准化transfer=StandardScaler()data_new=transf...
本文实例为大家分享了Python实点云分割k-means(sklearn),供大家参考,具体内容如下植物叶片分割importnumpyasnpimportmatplotlib.pyplotaspltimportpandasaspdfromsklearn.clusterimportKMeansfromsklearn.preprocessingimportStandardScalerfrommpl_toolkits.mplot3dimportAxes3Ddata=pd.read_csv("jiaaobo1.txt",sep="")data1=data.iloc[:,0:3]#标准化transfer=StandardScaler()data_new=transf...