
2020
10-08
10-08
浅谈keras 模型用于预测时的注意事项
为什么训练误差比测试误差高很多?一个Keras的模型有两个模式:训练模式和测试模式。一些正则机制,如Dropout,L1/L2正则项在测试模式下将不被启用。另外,训练误差是训练数据每个batch的误差的平均。在训练过程中,每个epoch起始时的batch的误差要大一些,而后面的batch的误差要小一些。另一方面,每个epoch结束时计算的测试误差是由模型在epoch结束时的状态决定的,这时候的网络将产生较小的误差。【Tips】可以通过定义回调函数...
继续阅读 >
 网上的教程大多数是教大家如何加载自定义模型和函数,如下图这个SelfAttention层是在训练过程自己定义的一个class,但如果要加载这个自定义层,需要在load_model里添加custom_objects字典,这个自定义的类,不要用import,最好是直接复制进再训练的模型中,这些是基本教程。------------------分割线讲重点------------------如果直接运行上面的代码,会出现一个init初始化错误,如下图,再来看看这个SelfAttention自定义的类的...
网上的教程大多数是教大家如何加载自定义模型和函数,如下图这个SelfAttention层是在训练过程自己定义的一个class,但如果要加载这个自定义层,需要在load_model里添加custom_objects字典,这个自定义的类,不要用import,最好是直接复制进再训练的模型中,这些是基本教程。------------------分割线讲重点------------------如果直接运行上面的代码,会出现一个init初始化错误,如下图,再来看看这个SelfAttention自定义的类的...
 卷积核可视化importmatplotlib.pyplotaspltimportnumpyasnpfromkerasimportbackendasKfromkeras.modelsimportload_model#将浮点图像转换成有效图像defdeprocess_image(x):#对张量进行规范化x-=x.mean()x/=(x.std()+1e-5)x*=0.1x+=0.5x=np.clip(x,0,1)#转化到RGB数组x*=255x=np.clip(x,0,255).astype('uint8')returnx#可视化滤波器defkernelvisual(model,layer_target=1,num_...
卷积核可视化importmatplotlib.pyplotaspltimportnumpyasnpfromkerasimportbackendasKfromkeras.modelsimportload_model#将浮点图像转换成有效图像defdeprocess_image(x):#对张量进行规范化x-=x.mean()x/=(x.std()+1e-5)x*=0.1x+=0.5x=np.clip(x,0,1)#转化到RGB数组x*=255x=np.clip(x,0,255).astype('uint8')returnx#可视化滤波器defkernelvisual(model,layer_target=1,num_...
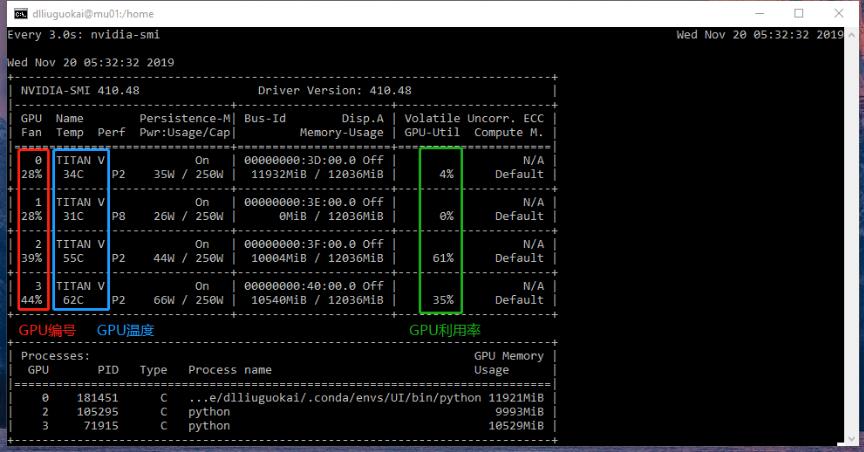 初步尝试Keras(基于Tensorflow后端)深度框架时,发现其对于GPU的使用比较神奇,默认竟然是全部占满显存,1080Ti跑个小分类问题,就一下子满了.而且是服务器上的两张1080Ti.服务器上的多张GPU都占满,有点浪费性能.因此,需要类似于Caffe等框架的可以设定GPUID和显存自动按需分配.实际中发现,Keras还可以限制GPU显存占用量.这里涉及到的内容有:GPUID设定GPU显存占用按需分配GPU显存占用限制GPU显存优化1....
初步尝试Keras(基于Tensorflow后端)深度框架时,发现其对于GPU的使用比较神奇,默认竟然是全部占满显存,1080Ti跑个小分类问题,就一下子满了.而且是服务器上的两张1080Ti.服务器上的多张GPU都占满,有点浪费性能.因此,需要类似于Caffe等框架的可以设定GPUID和显存自动按需分配.实际中发现,Keras还可以限制GPU显存占用量.这里涉及到的内容有:GPUID设定GPU显存占用按需分配GPU显存占用限制GPU显存优化1....
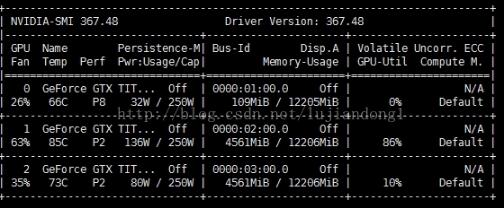 场景:某台机器上有三块卡,想同时开三个程序,放到三块卡上去训练。策略:CUDA_VISIBLE_DEVICES=1pythontrain.py就可以指定程序在某块卡上训练。补充知识:keras指定GPU及显存使用量指定GPUimportosos.environ["CUDA_VISIBLE_DEVICES"]="0"指定GPU和显存使用量importosfromkeras.backend.tensorflow_backendimportset_sessionos.environ["CUDA_VISIBLE_DEVICES"]="0"config=tf.ConfigProto()config.gpu_options.per_...
场景:某台机器上有三块卡,想同时开三个程序,放到三块卡上去训练。策略:CUDA_VISIBLE_DEVICES=1pythontrain.py就可以指定程序在某块卡上训练。补充知识:keras指定GPU及显存使用量指定GPUimportosos.environ["CUDA_VISIBLE_DEVICES"]="0"指定GPU和显存使用量importosfromkeras.backend.tensorflow_backendimportset_sessionos.environ["CUDA_VISIBLE_DEVICES"]="0"config=tf.ConfigProto()config.gpu_options.per_...
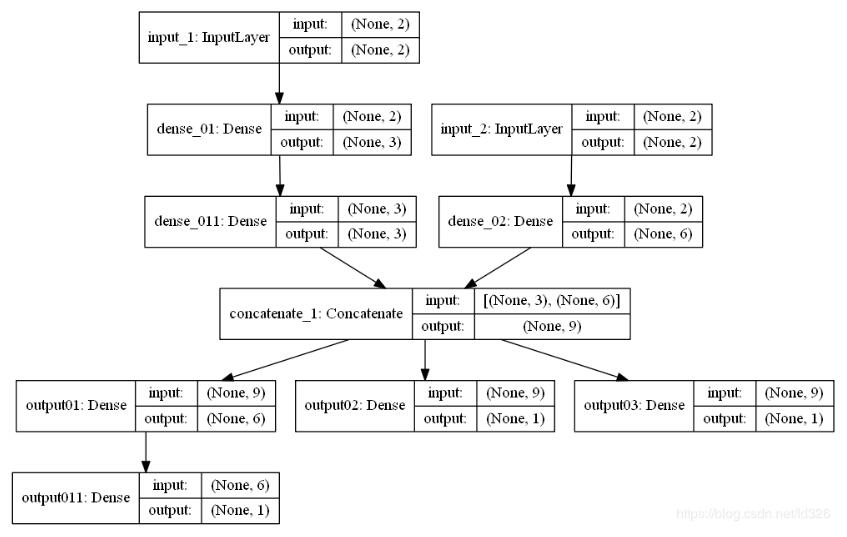 1、模型结果设计2、代码fromkerasimportInput,Modelfromkeras.layersimportDense,Concatenateimportnumpyasnpfromkeras.utilsimportplot_modelfromnumpyimportrandomasrdsamples_n=3000samples_dim_01=2samples_dim_02=2#样本数据x1=rd.rand(samples_n,samples_dim_01)x2=rd.rand(samples_n,samples_dim_02)y_1=[]y_2=[]y_3=[]forx11,x22inzip(x1,x2):y_1.append(np.sum(x11)+np.s...
1、模型结果设计2、代码fromkerasimportInput,Modelfromkeras.layersimportDense,Concatenateimportnumpyasnpfromkeras.utilsimportplot_modelfromnumpyimportrandomasrdsamples_n=3000samples_dim_01=2samples_dim_02=2#样本数据x1=rd.rand(samples_n,samples_dim_01)x2=rd.rand(samples_n,samples_dim_02)y_1=[]y_2=[]y_3=[]forx11,x22inzip(x1,x2):y_1.append(np.sum(x11)+np.s...
 记录一下:#Threelossfunctionscategory_predict1=Dense(100,activation='softmax',name='ctg_out_1')(Dropout(0.5)(feature1))category_predict2=Dense(100,activation='softmax',name='ctg_out_2')(Dropout(0.5)(feature2))dis=Lambda(eucl_dist,name='square')([feature1,feature2])judge=Dense(2,activation='softmax',name='bin_out')(dis)model=Model(inputs=[img1,img2],outputs=[category_pred...
记录一下:#Threelossfunctionscategory_predict1=Dense(100,activation='softmax',name='ctg_out_1')(Dropout(0.5)(feature1))category_predict2=Dense(100,activation='softmax',name='ctg_out_2')(Dropout(0.5)(feature2))dis=Lambda(eucl_dist,name='square')([feature1,feature2])judge=Dense(2,activation='softmax',name='bin_out')(dis)model=Model(inputs=[img1,img2],outputs=[category_pred...
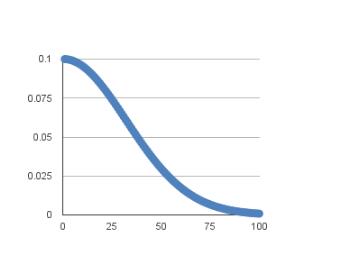 SGD随机梯度下降Keras中包含了各式优化器供我们使用,但通常我会倾向于使用SGD验证模型能否快速收敛,然后调整不同的学习速率看看模型最后的性能,然后再尝试使用其他优化器。Keras中文文档中对SGD的描述如下:keras.optimizers.SGD(lr=0.01,momentum=0.0,decay=0.0,nesterov=False)随机梯度下降法,支持动量参数,支持学习衰减率,支持Nesterov动量参数:lr:大或等于0的浮点数,学习率momentum:大或等于0的浮点数,动...
SGD随机梯度下降Keras中包含了各式优化器供我们使用,但通常我会倾向于使用SGD验证模型能否快速收敛,然后调整不同的学习速率看看模型最后的性能,然后再尝试使用其他优化器。Keras中文文档中对SGD的描述如下:keras.optimizers.SGD(lr=0.01,momentum=0.0,decay=0.0,nesterov=False)随机梯度下降法,支持动量参数,支持学习衰减率,支持Nesterov动量参数:lr:大或等于0的浮点数,学习率momentum:大或等于0的浮点数,动...
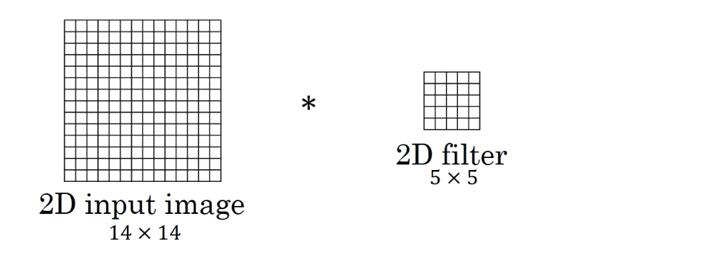 如有错误,欢迎斧正。我的答案是,在Conv2D输入通道为1的情况下,二者是没有区别或者说是可以相互转化的。首先,二者调用的最后的代码都是后端代码(以TensorFlow为例,在tensorflow_backend.py里面可以找到):x=tf.nn.convolution(input=x,filter=kernel,dilation_rate=(dilation_rate,),strides=(strides,),padding=padding,data_format=tf_data_format)区别在于input和filter传递的参数不同,input不必说,filter=kern...
如有错误,欢迎斧正。我的答案是,在Conv2D输入通道为1的情况下,二者是没有区别或者说是可以相互转化的。首先,二者调用的最后的代码都是后端代码(以TensorFlow为例,在tensorflow_backend.py里面可以找到):x=tf.nn.convolution(input=x,filter=kernel,dilation_rate=(dilation_rate,),strides=(strides,),padding=padding,data_format=tf_data_format)区别在于input和filter传递的参数不同,input不必说,filter=kern...