
2020
09-24
09-24
Pyspark读取parquet数据过程解析
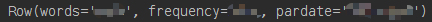 parquet数据:列式存储结构,由Twitter和Cloudera合作开发,相比于行式存储,其特点是:可以跳过不符合条件的数据,只读取需要的数据,降低IO数据量;压缩编码可以降低磁盘存储空间,使用更高效的压缩编码节约存储空间;只读取需要的列,支持向量运算,能够获取更好的扫描性能。那么我们怎么在pyspark中读取和使用parquet数据呢?我以local模式,linux下的pycharm执行作说明。首先,导入库文件和配置环境:importosfrompysparki...
继续阅读 >
parquet数据:列式存储结构,由Twitter和Cloudera合作开发,相比于行式存储,其特点是:可以跳过不符合条件的数据,只读取需要的数据,降低IO数据量;压缩编码可以降低磁盘存储空间,使用更高效的压缩编码节约存储空间;只读取需要的列,支持向量运算,能够获取更好的扫描性能。那么我们怎么在pyspark中读取和使用parquet数据呢?我以local模式,linux下的pycharm执行作说明。首先,导入库文件和配置环境:importosfrompysparki...
继续阅读 >