
2022
09-20
09-20
利用python数据分析处理进行炒股实战行情
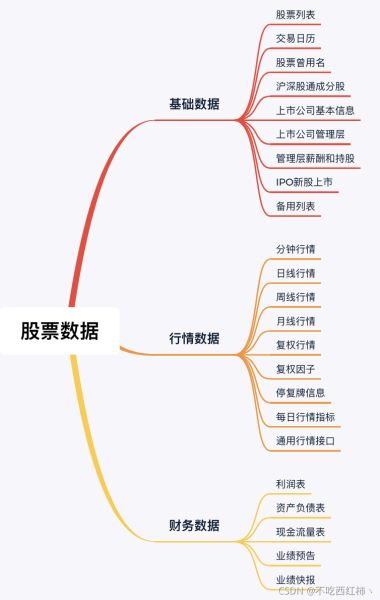 目录数据内容:1、数据采集我们现在要取一批特定股票的日线行情库名:stock表名:stock_all2、数据预处理以机器学习的视角来看,数据预处理主要包括应用有监督学习的算法对个股进行建模3、SVM建模机器学习中有诸多有监督学习算法作为一个新手,你需要以下3个步骤:1、用户注册>2、获取token>3、调取数据数据内容:包含股票、基金、期货、债券、外汇、行业大数据,同时包括了数字货币行情等区块链数据的全数据品类的金融大数据...
继续阅读 >
目录数据内容:1、数据采集我们现在要取一批特定股票的日线行情库名:stock表名:stock_all2、数据预处理以机器学习的视角来看,数据预处理主要包括应用有监督学习的算法对个股进行建模3、SVM建模机器学习中有诸多有监督学习算法作为一个新手,你需要以下3个步骤:1、用户注册>2、获取token>3、调取数据数据内容:包含股票、基金、期货、债券、外汇、行业大数据,同时包括了数字货币行情等区块链数据的全数据品类的金融大数据...
继续阅读 >
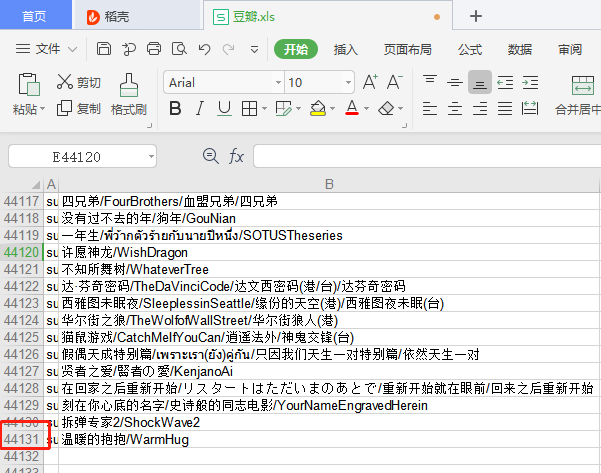 一、前言二、爬取观影数据https://movie.douban.com/在『豆瓣』平台爬取用户观影数据。爬取用户列表网页分析为了获取用户,我选择了其中一部电影的影评,这样可以根据评论的用户去获取其用户名称(后面爬取用户观影记录只需要『用户名称』)。https://movie.douban.com/subject/24733428/reviews?start=0url中start参数是页数(page*20,每一页20条数据),因此start=0、20、40...,也就是20的倍数,通过改变start参数值就可以...
一、前言二、爬取观影数据https://movie.douban.com/在『豆瓣』平台爬取用户观影数据。爬取用户列表网页分析为了获取用户,我选择了其中一部电影的影评,这样可以根据评论的用户去获取其用户名称(后面爬取用户观影记录只需要『用户名称』)。https://movie.douban.com/subject/24733428/reviews?start=0url中start参数是页数(page*20,每一页20条数据),因此start=0、20、40...,也就是20的倍数,通过改变start参数值就可以...
 目录一、前言二、数据分析与可视化三、一个真实的案例一、前言随着三胎政策的开放,人们对于生娃的讨论也逐渐热烈了起来,经常能够在各大社交媒体当中看到相关的话题,而随着时间慢慢地流逝,中国的首批“丁克家庭”已步入晚年,而相关的话题“那些当初选择不生孩子,现在四五十岁的人怎么样了?”也逐渐受到了人们的关注,尤其是现在年轻人生育的欲望已经不再那么的高了的情况下,二、数据分析与可视化首先我们对于网友的评论进行...
目录一、前言二、数据分析与可视化三、一个真实的案例一、前言随着三胎政策的开放,人们对于生娃的讨论也逐渐热烈了起来,经常能够在各大社交媒体当中看到相关的话题,而随着时间慢慢地流逝,中国的首批“丁克家庭”已步入晚年,而相关的话题“那些当初选择不生孩子,现在四五十岁的人怎么样了?”也逐渐受到了人们的关注,尤其是现在年轻人生育的欲望已经不再那么的高了的情况下,二、数据分析与可视化首先我们对于网友的评论进行...
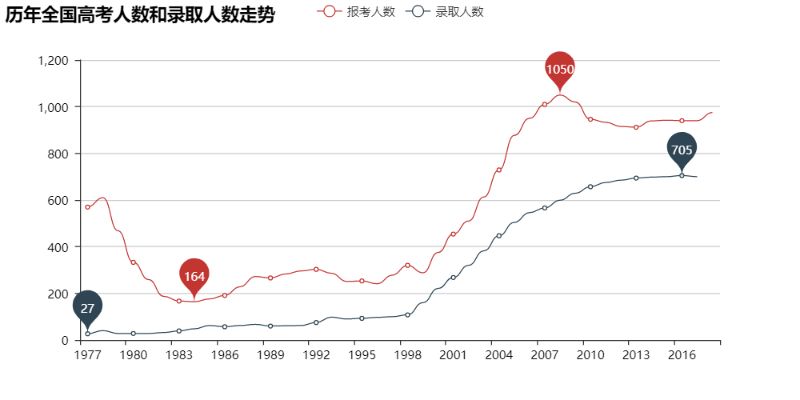 开发工具**Python版本:**3.6.4相关模块:pyecharts模块;以及一些Python自带的模块。环境搭建安装Python并添加到环境变量,pip安装需要的相关模块即可。pyecharts模块的安装可参考:Python简单分析微信好友“一本正经的分析”首先让我们来看看从恢复高考(1977年)开始高考报名、最终录取的总人数走势吧:T_T看来学生党确实是越来越多了。不过这样似乎并不能很直观地看出每年的录取比例?Ok,让我们直观地看看吧:看来上大学越来越...
开发工具**Python版本:**3.6.4相关模块:pyecharts模块;以及一些Python自带的模块。环境搭建安装Python并添加到环境变量,pip安装需要的相关模块即可。pyecharts模块的安装可参考:Python简单分析微信好友“一本正经的分析”首先让我们来看看从恢复高考(1977年)开始高考报名、最终录取的总人数走势吧:T_T看来学生党确实是越来越多了。不过这样似乎并不能很直观地看出每年的录取比例?Ok,让我们直观地看看吧:看来上大学越来越...
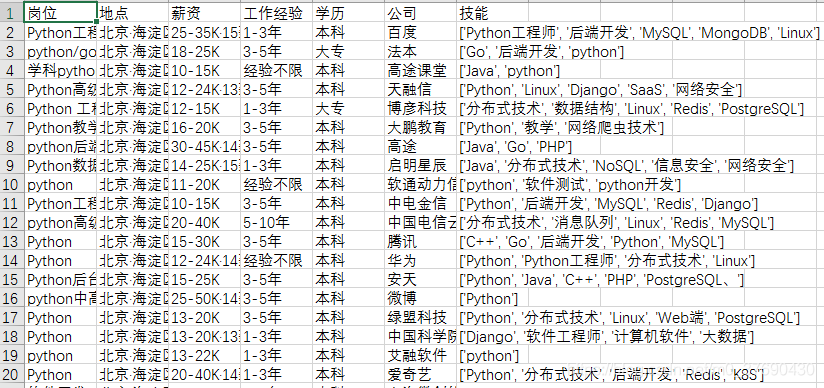 目录一、数据爬取的代码二、获取到的数据如图所示三、数据分析的代码四、学历分析五、工作经验分析六、14个热门城市的各区县招聘薪资情况七、各城市各区县的薪资情况八、技能栈一、数据爬取的代码#encoding='utf-8'fromseleniumimportwebdriverimporttimeimportreimportpandasaspdimportosdefclose_windows():#如果有登录弹窗,就关闭try:time.sleep(0.5)ifdr.find_element_by_class_name("jco...
目录一、数据爬取的代码二、获取到的数据如图所示三、数据分析的代码四、学历分析五、工作经验分析六、14个热门城市的各区县招聘薪资情况七、各城市各区县的薪资情况八、技能栈一、数据爬取的代码#encoding='utf-8'fromseleniumimportwebdriverimporttimeimportreimportpandasaspdimportosdefclose_windows():#如果有登录弹窗,就关闭try:time.sleep(0.5)ifdr.find_element_by_class_name("jco...
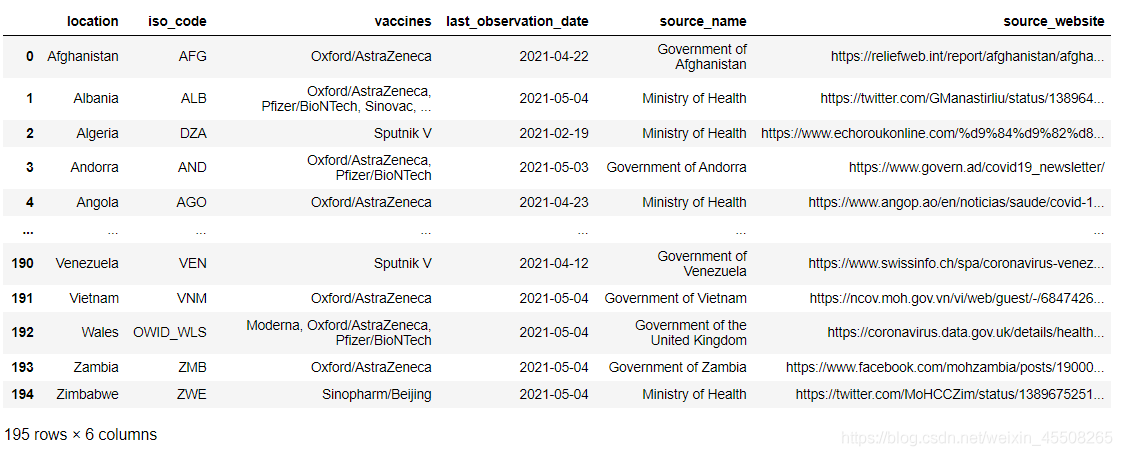 目录一、安装plotly库二、疫苗研发情况三、数据处理四、可视化疫苗的分布情况五、各品牌疫苗上市情况(仅部分国家)六、组织宽表七、补全缺失数据八、绘制堆叠柱状图一、安装plotly库因为这部分内容主要是用plotly库进行数据动态展示,所以要先安装plotly库pipinstallplotly除此之外,我们对数据的处理还用了numpy和pandas库,如果你没有安装的话,可以用以下命令一行安装pipinstallplotlynumpypandas#导入所需库importpand...
目录一、安装plotly库二、疫苗研发情况三、数据处理四、可视化疫苗的分布情况五、各品牌疫苗上市情况(仅部分国家)六、组织宽表七、补全缺失数据八、绘制堆叠柱状图一、安装plotly库因为这部分内容主要是用plotly库进行数据动态展示,所以要先安装plotly库pipinstallplotly除此之外,我们对数据的处理还用了numpy和pandas库,如果你没有安装的话,可以用以下命令一行安装pipinstallplotlynumpypandas#导入所需库importpand...
 目录一、图示二、csv文件三、数据库交互一、图示二、csv文件1.读取csv文件read_csv(file_pathorbuf,usecols,encoding):file_path:文件路径,usecols:指定读取的列名,encoding:编码data=pd.read_csv('d:/test_data/food_rank.csv',encoding='utf8')data.head()namenum0酥油茶219.01青稞酒95.02酸奶62.03糌粑16.04琵琶肉2.0#指定读取的列名data=pd.read_csv('d:/test_data/...
目录一、图示二、csv文件三、数据库交互一、图示二、csv文件1.读取csv文件read_csv(file_pathorbuf,usecols,encoding):file_path:文件路径,usecols:指定读取的列名,encoding:编码data=pd.read_csv('d:/test_data/food_rank.csv',encoding='utf8')data.head()namenum0酥油茶219.01青稞酒95.02酸奶62.03糌粑16.04琵琶肉2.0#指定读取的列名data=pd.read_csv('d:/test_data/...
 目录一、Anaconda二、nacondaprompt三、AnacondaNavigator四、Spyder五、jupyternotebook六、conda基本使用一、AnacondaAnaconda(水蟒)是一个捆绑了Python、conda、其他相关依赖包的一个软件。包含了180多个可学计算包及其依赖。Anaconda3是集成了Python3的环境,Anaconda2是集成了Python2的环境。Anaconda默认集成的包,是属于内置的Python的包。并且支持绝大部分操作系统(比如:Windows、Mac、Linux等)。下载地址如下:ht...
目录一、Anaconda二、nacondaprompt三、AnacondaNavigator四、Spyder五、jupyternotebook六、conda基本使用一、AnacondaAnaconda(水蟒)是一个捆绑了Python、conda、其他相关依赖包的一个软件。包含了180多个可学计算包及其依赖。Anaconda3是集成了Python3的环境,Anaconda2是集成了Python2的环境。Anaconda默认集成的包,是属于内置的Python的包。并且支持绝大部分操作系统(比如:Windows、Mac、Linux等)。下载地址如下:ht...
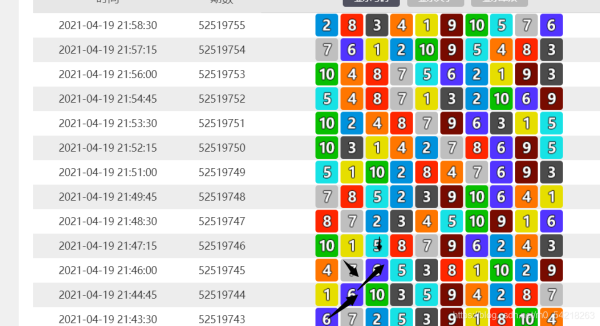 一、需求介绍该需求主要是分析彩票的历史数据客户的需求是根据彩票的前两期的情况,如果存在某个斜着的两个数字相等,那么就买第三期的同一个位置处的彩票对于1、,如果相等的数字是:1-5,那就买6-10,如果相等的数字是:6-10,那就买1-5;对于2、,如果相等的数字是:1-5,那就买1-5,如果相等的数字是:6-10,,那就买6-10。然后,根据这个方案,有可能会买中,但是也有可能买不中,于是,客户希望我可以统计出来在100天中,按...
一、需求介绍该需求主要是分析彩票的历史数据客户的需求是根据彩票的前两期的情况,如果存在某个斜着的两个数字相等,那么就买第三期的同一个位置处的彩票对于1、,如果相等的数字是:1-5,那就买6-10,如果相等的数字是:6-10,那就买1-5;对于2、,如果相等的数字是:1-5,那就买1-5,如果相等的数字是:6-10,,那就买6-10。然后,根据这个方案,有可能会买中,但是也有可能买不中,于是,客户希望我可以统计出来在100天中,按...
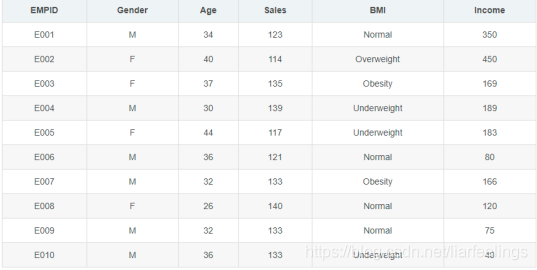 一、实验目的(1)熟练使用Counter类进行统计(2)掌握pandas中的cut方法进行分类(3)掌握matplotlib第三方库,能熟练使用该三方库库绘制图形二、实验内容采集到的数据集如下表格所示:三、实验要求1.按照性别进行分类,然后分别汇总男生和女生总的收入,并用直方图进行展示。2.男生和女生各占公司总人数的比例,并用扇形图进行展示。3.按照年龄进行分类(20-29岁,30-39岁,40-49岁),然后统计出各个年龄段有多少人,并用直方图...
一、实验目的(1)熟练使用Counter类进行统计(2)掌握pandas中的cut方法进行分类(3)掌握matplotlib第三方库,能熟练使用该三方库库绘制图形二、实验内容采集到的数据集如下表格所示:三、实验要求1.按照性别进行分类,然后分别汇总男生和女生总的收入,并用直方图进行展示。2.男生和女生各占公司总人数的比例,并用扇形图进行展示。3.按照年龄进行分类(20-29岁,30-39岁,40-49岁),然后统计出各个年龄段有多少人,并用直方图...
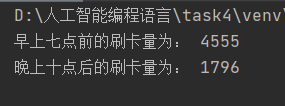 一、背景交通大数据是由交通运行管理直接产生的数据(包括各类道路交通、公共交通、对外交通的刷卡、线圈、卡口、GPS、视频、图片等数据)、交通相关行业和领域导入的数据(气象、环境、人口、规划、移动通信手机信令等数据),以及来自公众互动提供的交通状况数据(通过微博、微信、论坛、广播电台等提供的文字、图片、音视频等数据)构成的。现在给出了一个公交刷卡样例数据集,包含有交易类型、交易时间、交易卡号、刷卡类型、...
一、背景交通大数据是由交通运行管理直接产生的数据(包括各类道路交通、公共交通、对外交通的刷卡、线圈、卡口、GPS、视频、图片等数据)、交通相关行业和领域导入的数据(气象、环境、人口、规划、移动通信手机信令等数据),以及来自公众互动提供的交通状况数据(通过微博、微信、论坛、广播电台等提供的文字、图片、音视频等数据)构成的。现在给出了一个公交刷卡样例数据集,包含有交易类型、交易时间、交易卡号、刷卡类型、...
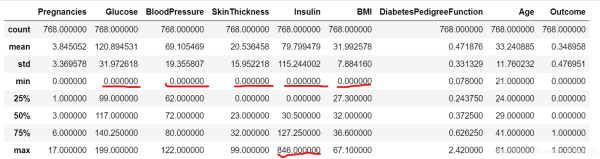 一、数据集描述本数据集内含十个属性列Pergnancies:怀孕次数Glucose:血糖浓度BloodPressure:舒张压(毫米汞柱)SkinThickness:肱三头肌皮肤褶皱厚度(毫米)Insulin:两个小时血清胰岛素(μU/毫升)BMI:身体质量指数,体重除以身高的平方DiabetsPedigreeFunction:疾病血统指数是否和遗传相关,Height:身高(厘米)Age:年龄Outcome:0表示不患病,1表示患病。任务:建立机器学习模型以准确预测数据集中的患者是否患有糖尿病二、...
一、数据集描述本数据集内含十个属性列Pergnancies:怀孕次数Glucose:血糖浓度BloodPressure:舒张压(毫米汞柱)SkinThickness:肱三头肌皮肤褶皱厚度(毫米)Insulin:两个小时血清胰岛素(μU/毫升)BMI:身体质量指数,体重除以身高的平方DiabetsPedigreeFunction:疾病血统指数是否和遗传相关,Height:身高(厘米)Age:年龄Outcome:0表示不患病,1表示患病。任务:建立机器学习模型以准确预测数据集中的患者是否患有糖尿病二、...
 一、前言春节档贺岁片《你好,李焕英》,于2月23日最新数据出来后,票房已经突破42亿,并且赶超其他贺岁片,成为2021的一匹黑马。从小品演员再到导演,贾玲处女作《你好李焕英》,为何能这么火?接下来荣仔带你运用Python借助电影网站从各个角度剖析这部电影喜得高票房的原因。二、影评爬取并词云分析毫无疑问,中国的电影评论伴随着整个社会文化语境的变迁以及不同场域和载体的更迭正发生着明显的变化。在纸质类影评统御了中国电...
一、前言春节档贺岁片《你好,李焕英》,于2月23日最新数据出来后,票房已经突破42亿,并且赶超其他贺岁片,成为2021的一匹黑马。从小品演员再到导演,贾玲处女作《你好李焕英》,为何能这么火?接下来荣仔带你运用Python借助电影网站从各个角度剖析这部电影喜得高票房的原因。二、影评爬取并词云分析毫无疑问,中国的电影评论伴随着整个社会文化语境的变迁以及不同场域和载体的更迭正发生着明显的变化。在纸质类影评统御了中国电...