
2022
08-16
08-16
python机器学习高数篇之函数极限与导数
 目录函数极限函数极限练习题.1函数极限练习题.2导数python求导数的三种写法方法一方法二方法三不知道大家有没有类似的经历,斗志满满地翻开厚厚的机器学习书,很快被一个个公式炸蒙了。想要学习机器学习算法,却很难看的懂里面的数学公式,实际应用只会调用库里的函数,无法优化算法。学好机器学习,没有数学知识是不行的。数学知识的积累是一个漫长的过程,罗马也不是一夜建成的。如果想要入门机器学习,数学基础比较薄弱,想打牢...
继续阅读 >
目录函数极限函数极限练习题.1函数极限练习题.2导数python求导数的三种写法方法一方法二方法三不知道大家有没有类似的经历,斗志满满地翻开厚厚的机器学习书,很快被一个个公式炸蒙了。想要学习机器学习算法,却很难看的懂里面的数学公式,实际应用只会调用库里的函数,无法优化算法。学好机器学习,没有数学知识是不行的。数学知识的积累是一个漫长的过程,罗马也不是一夜建成的。如果想要入门机器学习,数学基础比较薄弱,想打牢...
继续阅读 >
 不少同学一提到泰勒公式,脑海里立马浮现高大上的定义和长长的公式,令人望而生畏。实际上,泰勒公式没有那么可怕,它是用简单的多项式来逼近一个光滑的函数,从而近似替代不熟悉的函数。由于泰勒公式具有将复杂函数近似成多个幂函数叠加形式的性质,可以用它进行比较、求极限、求导、解微分方程等。我们先来看一下泰勒公式的发明者,布鲁克·泰勒——布鲁克·泰勒(BrookTaylor,1685-1732),英国数学家,牛顿学派最优秀的代表人...
不少同学一提到泰勒公式,脑海里立马浮现高大上的定义和长长的公式,令人望而生畏。实际上,泰勒公式没有那么可怕,它是用简单的多项式来逼近一个光滑的函数,从而近似替代不熟悉的函数。由于泰勒公式具有将复杂函数近似成多个幂函数叠加形式的性质,可以用它进行比较、求极限、求导、解微分方程等。我们先来看一下泰勒公式的发明者,布鲁克·泰勒——布鲁克·泰勒(BrookTaylor,1685-1732),英国数学家,牛顿学派最优秀的代表人...
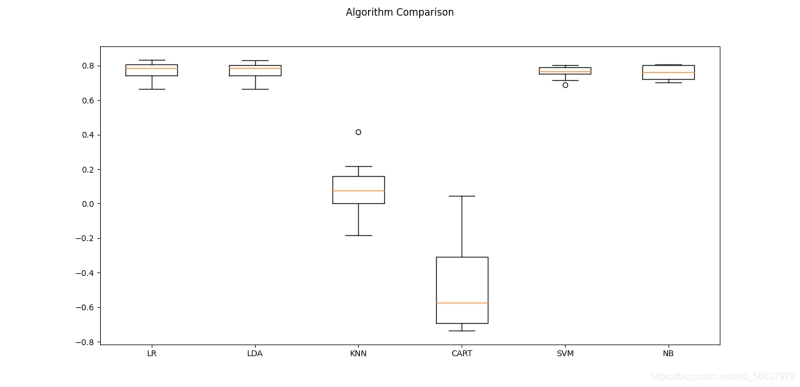 目录1.审查分类算法1.1线性算法审查1.1.1逻辑回归1.1.2线性判别分析1.2非线性算法审查1.2.1K近邻算法1.2.2贝叶斯分类器1.2.3分类与回归树1.2.4支持向量机2.审查回归算法2.1线性算法审查2.1.1线性回归算法2.1.2岭回归算法2.1.3套索回归算法2.1.4弹性网络回归算法2.2非线性算法审查2.2.1K近邻算法2.2.2分类与回归树2.2.3支持向量机3.算法比较总结程序测试是展现BUG存在的有效方式,但令人绝望的是它不足以展现其缺位。——艾兹格·迪...
目录1.审查分类算法1.1线性算法审查1.1.1逻辑回归1.1.2线性判别分析1.2非线性算法审查1.2.1K近邻算法1.2.2贝叶斯分类器1.2.3分类与回归树1.2.4支持向量机2.审查回归算法2.1线性算法审查2.1.1线性回归算法2.1.2岭回归算法2.1.3套索回归算法2.1.4弹性网络回归算法2.2非线性算法审查2.2.1K近邻算法2.2.2分类与回归树2.2.3支持向量机3.算法比较总结程序测试是展现BUG存在的有效方式,但令人绝望的是它不足以展现其缺位。——艾兹格·迪...
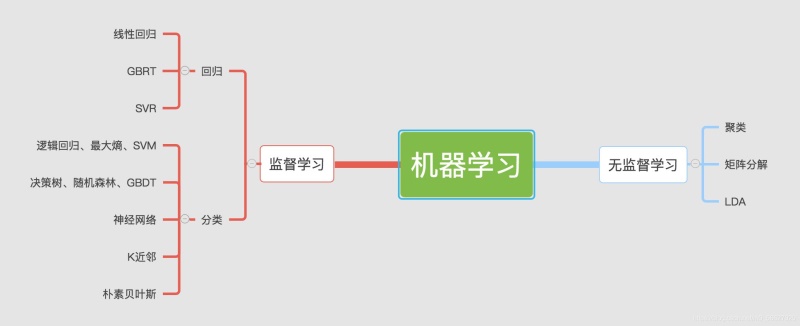 目录前言写在前面1.什么是机器学习?1.1监督学习1.2无监督学习2.Python中的机器学习3.必须环境安装Anacodna安装总结前言每一次变革都由技术驱动。纵观人类历史,上古时代,人类从采集狩猎社会,进化为农业社会;由农业社会进入到工业社会;从工业社会到现在信息社会。每一次变革,都由新技术引导。在历次的技术革命中,一个人、一家企业,甚至一个国家,可以选择的道路只有两条:要么加入时代的变革,勇立潮头;要么徘徊观望,抱...
目录前言写在前面1.什么是机器学习?1.1监督学习1.2无监督学习2.Python中的机器学习3.必须环境安装Anacodna安装总结前言每一次变革都由技术驱动。纵观人类历史,上古时代,人类从采集狩猎社会,进化为农业社会;由农业社会进入到工业社会;从工业社会到现在信息社会。每一次变革,都由新技术引导。在历次的技术革命中,一个人、一家企业,甚至一个国家,可以选择的道路只有两条:要么加入时代的变革,勇立潮头;要么徘徊观望,抱...
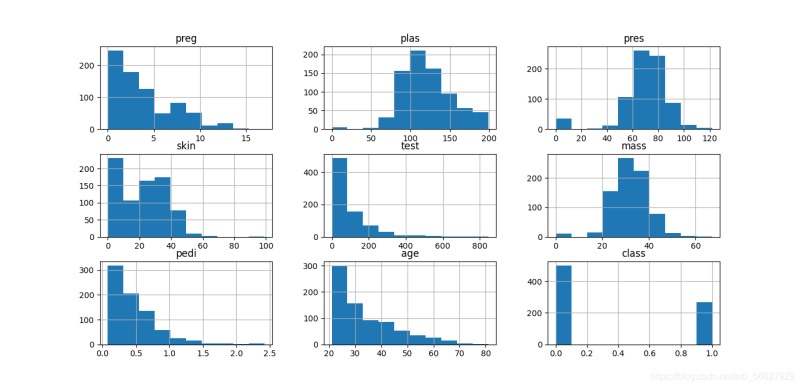 目录1.数据导入1.1使用标准Python类库导入数据1.2使用Numpy导入数据1.3使用Pandas导入数据2.数据理解2.1数据基本属性2.1.1查看前10行数据2.1.2查看数据维度,数据属性和类型:2.1.3查看数据描述性统计2.2数据相关性和分布分析2.2.1数据相关矩阵2.2.2数据分布分析3.数据可视化3.1单一图表3.1.1直方图3.1.2密度图3.1.3箱线图3.2多重图表3.2.1相关矩阵图3.2.2散点矩阵图总结统计学是什么?概率与数学。用概率与数学来分析人,分析的永...
目录1.数据导入1.1使用标准Python类库导入数据1.2使用Numpy导入数据1.3使用Pandas导入数据2.数据理解2.1数据基本属性2.1.1查看前10行数据2.1.2查看数据维度,数据属性和类型:2.1.3查看数据描述性统计2.2数据相关性和分布分析2.2.1数据相关矩阵2.2.2数据分布分析3.数据可视化3.1单一图表3.1.1直方图3.1.2密度图3.1.3箱线图3.2多重图表3.2.1相关矩阵图3.2.2散点矩阵图总结统计学是什么?概率与数学。用概率与数学来分析人,分析的永...
 目录1.数据分离与验证1.1分离训练数据集和评估数据集1.2K折交叉验证分离1.3弃一交叉验证分离1.4重复随机分离评估数据集与训练数据集2.算法评估2.1分类算法评估2.1.1分类准确度2.1.2分类报告2.2回归算法评估2.2.1平均绝对误差2.2.2均方误差2.2.3判定系数()1.数据分离与验证要知道算法模型对未知的数据表现如何,最好的评估办法是利用已经明确知道结果的数据运行生成的算法模型进行验证。此外还可以使用新的数据来评估算法模型。在...
目录1.数据分离与验证1.1分离训练数据集和评估数据集1.2K折交叉验证分离1.3弃一交叉验证分离1.4重复随机分离评估数据集与训练数据集2.算法评估2.1分类算法评估2.1.1分类准确度2.1.2分类报告2.2回归算法评估2.2.1平均绝对误差2.2.2均方误差2.2.3判定系数()1.数据分离与验证要知道算法模型对未知的数据表现如何,最好的评估办法是利用已经明确知道结果的数据运行生成的算法模型进行验证。此外还可以使用新的数据来评估算法模型。在...
 目录01直接生成一、基础类型1、月牙形数据集合2、方形数据集3、螺旋形数据集合02样本生成器一、基础数据集1、点簇形数据集合2、线簇形数据集合3、环形数据集合4、月牙数据集合测试结论01直接生成这类方法是利用基本程序软件包numpy的随机数产生方法来生成各类用于聚类算法数据集合,也是自行制作轮子的生成方法。一、基础类型1、月牙形数据集合fromheadmimport*importnumpyasnppltgif=PlotGIF()defmoon2Data(datanum):...
目录01直接生成一、基础类型1、月牙形数据集合2、方形数据集3、螺旋形数据集合02样本生成器一、基础数据集1、点簇形数据集合2、线簇形数据集合3、环形数据集合4、月牙数据集合测试结论01直接生成这类方法是利用基本程序软件包numpy的随机数产生方法来生成各类用于聚类算法数据集合,也是自行制作轮子的生成方法。一、基础类型1、月牙形数据集合fromheadmimport*importnumpyasnppltgif=PlotGIF()defmoon2Data(datanum):...
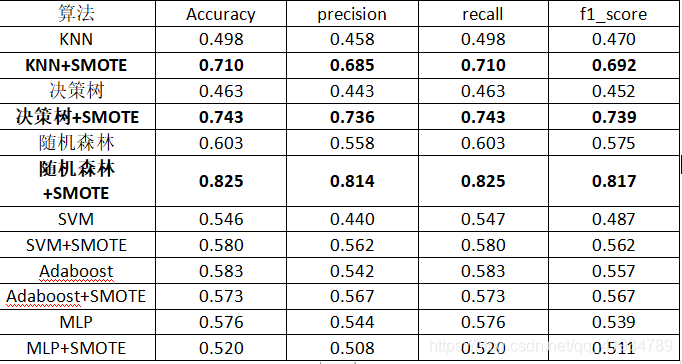 Python算法的分类对葡萄酒数据集进行测试,由于数据集是多分类且数据的样本分布不平衡,所以直接对数据测试,效果不理想。所以使用SMOTE过采样对数据进行处理,对数据去重,去空,处理后数据达到均衡,然后进行测试,与之前测试相比,准确率提升较高。例如:决策树:Smote处理前:Smote处理后:fromtypingimportCounterfrommatplotlibimportcolors,markersimportnumpyasnpimportpandasaspdimportoperatorimportmatp...
Python算法的分类对葡萄酒数据集进行测试,由于数据集是多分类且数据的样本分布不平衡,所以直接对数据测试,效果不理想。所以使用SMOTE过采样对数据进行处理,对数据去重,去空,处理后数据达到均衡,然后进行测试,与之前测试相比,准确率提升较高。例如:决策树:Smote处理前:Smote处理后:fromtypingimportCounterfrommatplotlibimportcolors,markersimportnumpyasnpimportpandasaspdimportoperatorimportmatp...
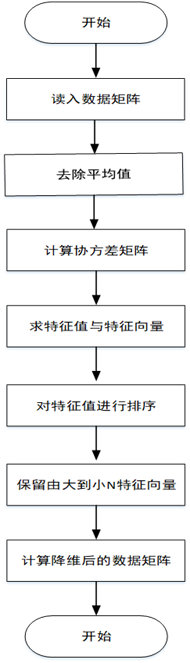 目录一、算法概述二、算法步骤三、相关概念四、算法优缺点五、算法实现六、算法优化一、算法概述主成分分析(PrincipalComponentAnalysis,PCA)是一种掌握事物主要矛盾的统计分析方法,它可以从多元事物中解析出主要影响因素,揭示事物的本质,简化复杂的问题。PCA是最常用的一种降维方法,它的目标是通过某种线性投影,将高维的数据映射到低维的空间中,并期望在所投影的维度上数据的方差最大,以此使用较少的维度,...
目录一、算法概述二、算法步骤三、相关概念四、算法优缺点五、算法实现六、算法优化一、算法概述主成分分析(PrincipalComponentAnalysis,PCA)是一种掌握事物主要矛盾的统计分析方法,它可以从多元事物中解析出主要影响因素,揭示事物的本质,简化复杂的问题。PCA是最常用的一种降维方法,它的目标是通过某种线性投影,将高维的数据映射到低维的空间中,并期望在所投影的维度上数据的方差最大,以此使用较少的维度,...
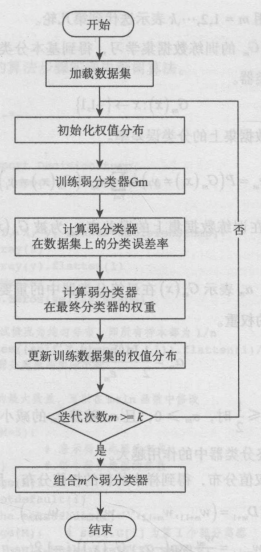 目录一、算法概述二、算法原理三、算法步骤四、算法实现五、算法优化一、算法概述AdaBoost是英文AdaptiveBoosting(自适应增强)的缩写,由YoavFreund和RobertSchapire在1995年提出。AdaBoost的自适应在于前一个基本分类器分类错误的样本的权重会得到加强,加强后的全体样本再次被用来训练下一个基本分类器。同时,在每一轮训练中加入一个新的弱分类器,直到达到某个预定的足够小的错误率或达到预先指定的最大迭...
目录一、算法概述二、算法原理三、算法步骤四、算法实现五、算法优化一、算法概述AdaBoost是英文AdaptiveBoosting(自适应增强)的缩写,由YoavFreund和RobertSchapire在1995年提出。AdaBoost的自适应在于前一个基本分类器分类错误的样本的权重会得到加强,加强后的全体样本再次被用来训练下一个基本分类器。同时,在每一轮训练中加入一个新的弱分类器,直到达到某个预定的足够小的错误率或达到预先指定的最大迭...
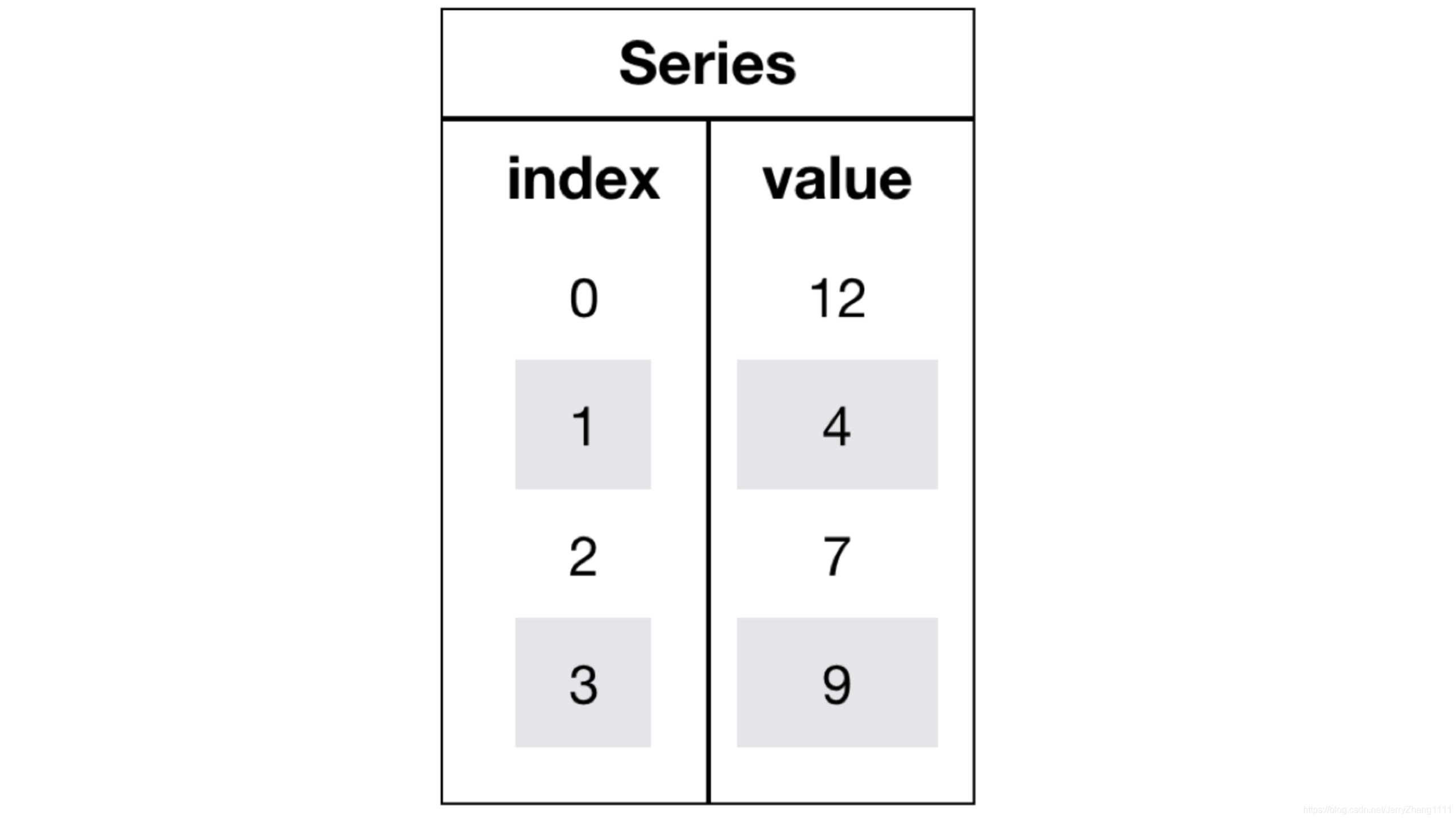 一、Pandas2008年WesMcKinney开发出的库专门用于数据挖掘的开源python库以Numpy为基础,借力Numpy模块在计算方面性能高的优势基于matplotlib,能够简便的画图独特的数据结构二、数据结构Pandas中一共有三种数据结构,分别为:Series、DataFrame和MultiIndex。三、SeriesSeries是一个类似于一维数组的数据结构,它能够保存任何类型的数据,比如整数、字符串、浮点数等,主要由一组数据和与之相关的索引两部分构成。Series的...
一、Pandas2008年WesMcKinney开发出的库专门用于数据挖掘的开源python库以Numpy为基础,借力Numpy模块在计算方面性能高的优势基于matplotlib,能够简便的画图独特的数据结构二、数据结构Pandas中一共有三种数据结构,分别为:Series、DataFrame和MultiIndex。三、SeriesSeries是一个类似于一维数组的数据结构,它能够保存任何类型的数据,比如整数、字符串、浮点数等,主要由一组数据和与之相关的索引两部分构成。Series的...
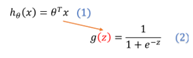 一、题目1.主题:逻辑回归2.描述:假设你是某大学招生主管,你想根据两次考试的结果决定每个申请者的录取机会。现有以往申请者的历史数据,可以此作为训练集建立逻辑回归模型,并用其预测某学生能否被大学录取。3.数据集:文件ex2data1.txt,第一列、第二列分别表示申请者两次考试的成绩,第三列表示录取结果(1表示录取,0表示不录取)。二、目的1.理解逻辑回归模型2.掌握逻辑回归模型的参数估计算法三、平台1.硬件:计算机2....
一、题目1.主题:逻辑回归2.描述:假设你是某大学招生主管,你想根据两次考试的结果决定每个申请者的录取机会。现有以往申请者的历史数据,可以此作为训练集建立逻辑回归模型,并用其预测某学生能否被大学录取。3.数据集:文件ex2data1.txt,第一列、第二列分别表示申请者两次考试的成绩,第三列表示录取结果(1表示录取,0表示不录取)。二、目的1.理解逻辑回归模型2.掌握逻辑回归模型的参数估计算法三、平台1.硬件:计算机2....
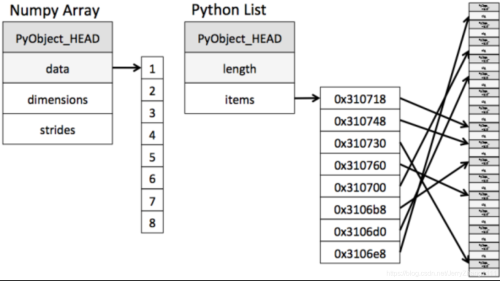 一、前言机器学习三大件:numpy,pandas,matplotlibNumpy(NumericalPython)是一个开源的Python科学计算库,用于快速处理任意维度的数组。Numpy支持常见的数组和矩阵操作。对于同样的数值计算任务,使用Numpy比直接使用Python要简洁的多。Numpy使用ndarray对象来处理多维数组,该对象是一个快速而灵活的大数据容器。NumPy提供了一个N维数组类型ndarrayimportnumpyasnpscore=np.array([[80,89,86,67,79],[78,97,89,...
一、前言机器学习三大件:numpy,pandas,matplotlibNumpy(NumericalPython)是一个开源的Python科学计算库,用于快速处理任意维度的数组。Numpy支持常见的数组和矩阵操作。对于同样的数值计算任务,使用Numpy比直接使用Python要简洁的多。Numpy使用ndarray对象来处理多维数组,该对象是一个快速而灵活的大数据容器。NumPy提供了一个N维数组类型ndarrayimportnumpyasnpscore=np.array([[80,89,86,67,79],[78,97,89,...
 一、要求二、原理决策树是一种类似于流程图的结构,其中每个内部节点代表一个属性上的“测试”,每个分支代表测试的结果,每个叶节点代表一个测试结果。类标签(在计算所有属性后做出的决定)。从根到叶的路径代表分类规则。决策树学习的目的是为了产生一棵泛化能力强,即处理未见示例能力强的决策树。因此如何构建决策树,是后续预测的关键!而构建决策树,就需要确定类标签判断的先后,其决定了构建的决策树的性能。决策树的分支...
一、要求二、原理决策树是一种类似于流程图的结构,其中每个内部节点代表一个属性上的“测试”,每个分支代表测试的结果,每个叶节点代表一个测试结果。类标签(在计算所有属性后做出的决定)。从根到叶的路径代表分类规则。决策树学习的目的是为了产生一棵泛化能力强,即处理未见示例能力强的决策树。因此如何构建决策树,是后续预测的关键!而构建决策树,就需要确定类标签判断的先后,其决定了构建的决策树的性能。决策树的分支...