
2021
05-20
05-20
python爬虫之爬取谷歌趋势数据
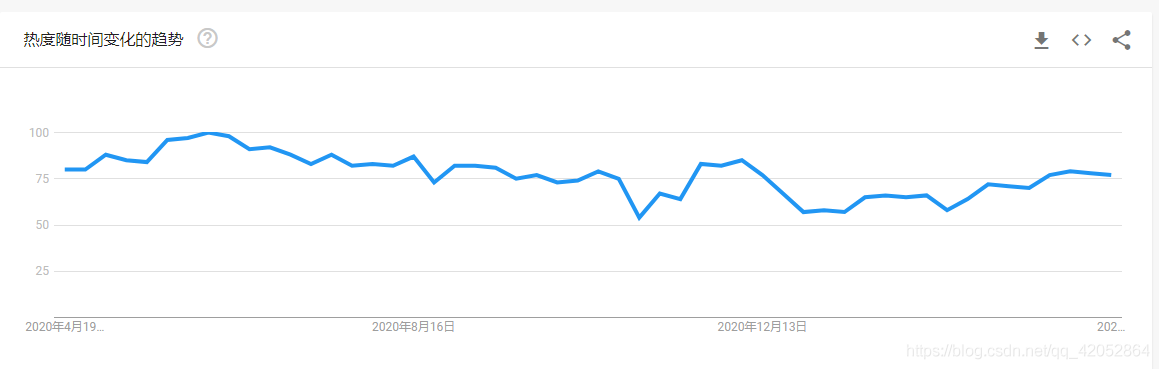 一、前言 爬取谷歌趋势数据需要科学上网~二、思路谷歌数据的爬取很简单,就是代码有点长。主要分下面几个就行了爬取的三个界面返回的都是json数据。主要获取对应的token值和req,然后构造url请求数据就行token值和req值都在这个链接的返回数据里。解析后得到token和req就行socks5代理不太懂,抄网上的作业,假如了当前程序的全局代理后就可以跑了。全部代码如下importsocketimportsocksimportrequestsimportjsonimportpa...
继续阅读 >
一、前言 爬取谷歌趋势数据需要科学上网~二、思路谷歌数据的爬取很简单,就是代码有点长。主要分下面几个就行了爬取的三个界面返回的都是json数据。主要获取对应的token值和req,然后构造url请求数据就行token值和req值都在这个链接的返回数据里。解析后得到token和req就行socks5代理不太懂,抄网上的作业,假如了当前程序的全局代理后就可以跑了。全部代码如下importsocketimportsocksimportrequestsimportjsonimportpa...
继续阅读 >
 一、主要目的最近在玩Python网络爬虫,然后接触到了selenium这个模块,就捉摸着搞点有意思的,顺便记录一下自己的学习过程。二、前期准备操作系统:windows10浏览器:谷歌浏览器(GoogleChrome)浏览器驱动:chromedriver.exe(我的版本—>89.0.4389.128)程序中我使用的模块importcsvimportosimportreimportjsonimporttimeimportrequestsfromselenium.webdriverimportChromefromselenium.webdriver.re...
一、主要目的最近在玩Python网络爬虫,然后接触到了selenium这个模块,就捉摸着搞点有意思的,顺便记录一下自己的学习过程。二、前期准备操作系统:windows10浏览器:谷歌浏览器(GoogleChrome)浏览器驱动:chromedriver.exe(我的版本—>89.0.4389.128)程序中我使用的模块importcsvimportosimportreimportjsonimporttimeimportrequestsfromselenium.webdriverimportChromefromselenium.webdriver.re...
 1.收集数据1.1爬取晋江文学城收藏排行榜前50页的小说信息获取收藏榜前50页的小说列表,第一页网址为‘http://www.jjwxc.net/bookbase.php?fw0=0&fbsj=0&ycx0=0&xx2=2&mainview0=0&sd0=0&lx0=0&fg0=0&sortType=0&isfinish=0&collectiontypes=ors&searchkeywords=&page=1',第二页网址中page=2,以此类推,直到第50页中page=50。爬取每个小说的ID,小说名字,小说作者。将爬取到的信息存储到晋江排行榜【按收藏数】.txt文件...
1.收集数据1.1爬取晋江文学城收藏排行榜前50页的小说信息获取收藏榜前50页的小说列表,第一页网址为‘http://www.jjwxc.net/bookbase.php?fw0=0&fbsj=0&ycx0=0&xx2=2&mainview0=0&sd0=0&lx0=0&fg0=0&sortType=0&isfinish=0&collectiontypes=ors&searchkeywords=&page=1',第二页网址中page=2,以此类推,直到第50页中page=50。爬取每个小说的ID,小说名字,小说作者。将爬取到的信息存储到晋江排行榜【按收藏数】.txt文件...
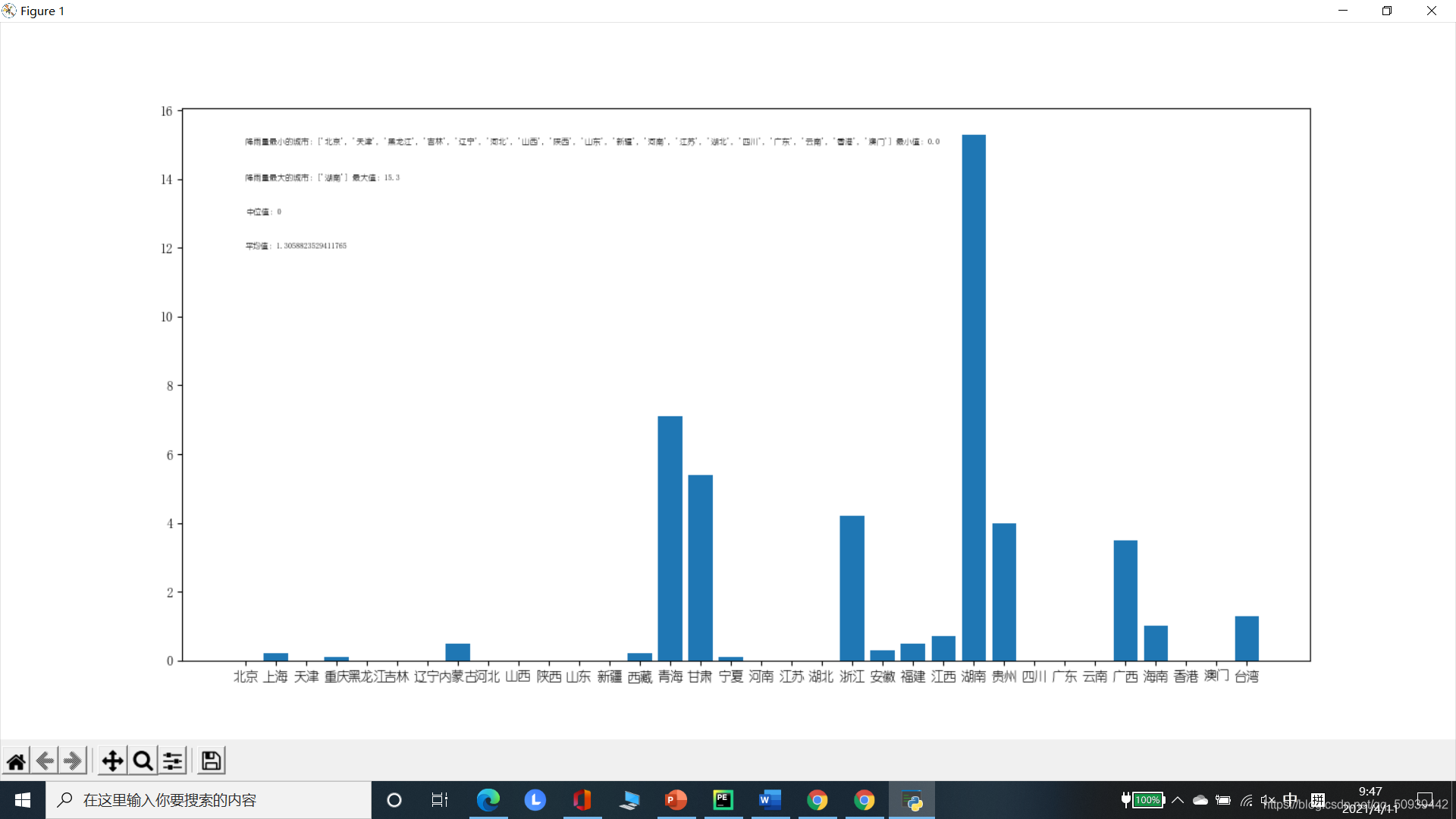 在具体数据的选取上,我爬取的是各省份降水量实时数据话不多说,开始实操正文 1.爬取数据使用python爬虫,爬取中国天气网各省份24时整点气象数据由于降水量为动态数据,以js形式进行存储,故采用selenium方法经xpath爬取数据—ps:在进行数据爬取时,最初使用的方法是漂亮汤法(beautifulsoup)法,但当输出爬取的内容(<class=split>时,却空空如也。在源代码界面Ctrl+Shift+F搜索后也无法找到降水量,后查询得知...
在具体数据的选取上,我爬取的是各省份降水量实时数据话不多说,开始实操正文 1.爬取数据使用python爬虫,爬取中国天气网各省份24时整点气象数据由于降水量为动态数据,以js形式进行存储,故采用selenium方法经xpath爬取数据—ps:在进行数据爬取时,最初使用的方法是漂亮汤法(beautifulsoup)法,但当输出爬取的内容(<class=split>时,却空空如也。在源代码界面Ctrl+Shift+F搜索后也无法找到降水量,后查询得知...
 一、shapely模块1、shapelyshapely是python中开源的针对空间几何进行处理的模块,支持点、线、面等基本几何对象类型以及相关空间操作。2、point→Point类curve→LineString和LinearRing类;surface→Polygon类集合方法分别对应MultiPoint、MultiLineString、MultiPolygon3、导入所需模块#导入所需模块fromshapelyimportgeometryasgeofromshapelyimportwktfromshapelyimportopsimportnumpyasnpfromshapely.geometry...
一、shapely模块1、shapelyshapely是python中开源的针对空间几何进行处理的模块,支持点、线、面等基本几何对象类型以及相关空间操作。2、point→Point类curve→LineString和LinearRing类;surface→Polygon类集合方法分别对应MultiPoint、MultiLineString、MultiPolygon3、导入所需模块#导入所需模块fromshapelyimportgeometryasgeofromshapelyimportwktfromshapelyimportopsimportnumpyasnpfromshapely.geometry...
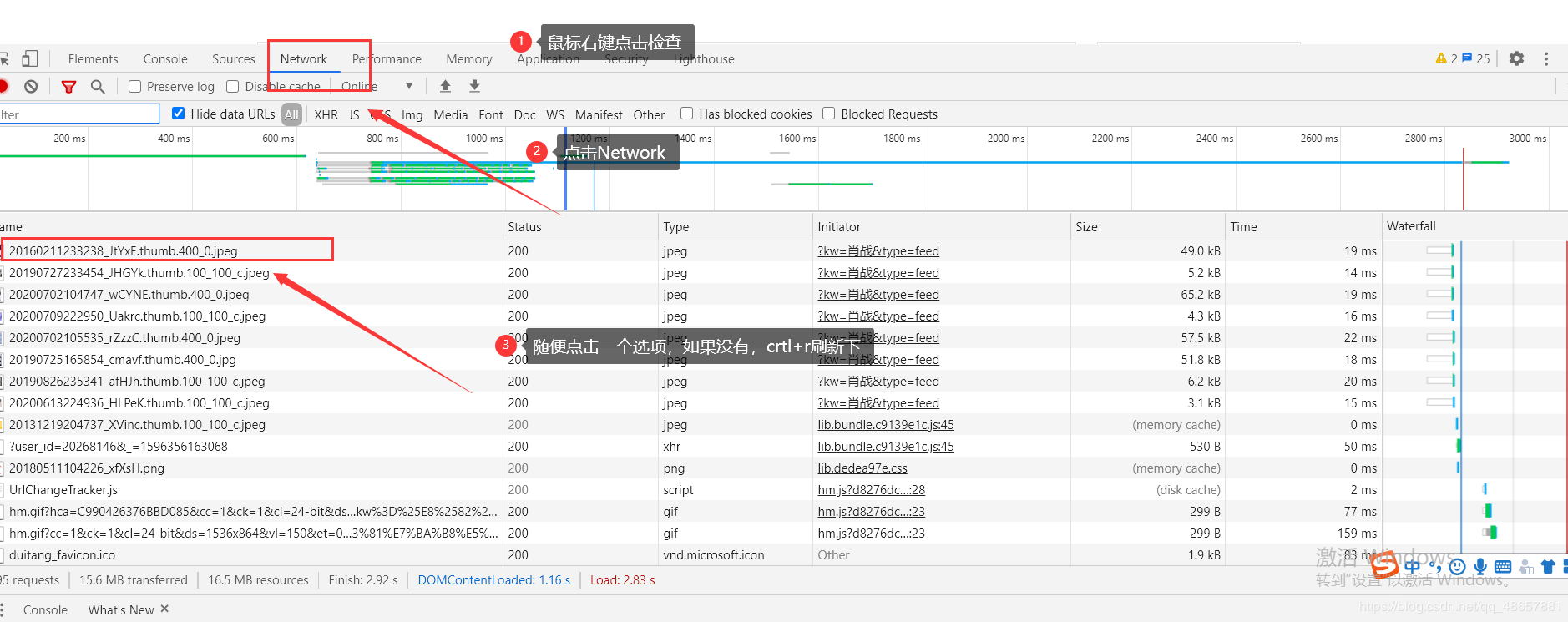 本次小编向大家介绍的是根据用户的需求输入想爬取的内容及页数。主要步骤:1.提示用户输入爬取的内容及页码。2.根据用户输入,获取网址列表。3.模拟浏览器向服务器发送请求,获取响应。4.利用xpath方法找到图片的标签。5.保存数据。代码用面向过程的形式编写的。关键字:requests库,xpath,面向过程现在就来讲解代码书写的过程:1.导入模块importparsel#该模块主要用来将请求后的字符串格式解析成re,xpath,css进行内容的匹配imp...
本次小编向大家介绍的是根据用户的需求输入想爬取的内容及页数。主要步骤:1.提示用户输入爬取的内容及页码。2.根据用户输入,获取网址列表。3.模拟浏览器向服务器发送请求,获取响应。4.利用xpath方法找到图片的标签。5.保存数据。代码用面向过程的形式编写的。关键字:requests库,xpath,面向过程现在就来讲解代码书写的过程:1.导入模块importparsel#该模块主要用来将请求后的字符串格式解析成re,xpath,css进行内容的匹配imp...