
2021
06-23
06-23
python基础之爬虫入门
 前言python基础爬虫主要针对一些反爬机制较为简单的网站,是对爬虫整个过程的了解与爬虫策略的熟练过程。爬虫分为四个步骤:请求,解析数据,提取数据,存储数据。本文也会从这四个角度介绍基础爬虫的案例。一、简单静态网页的爬取我们要爬取的是一个壁纸网站的所有壁纸http://www.netbian.com/dongman/1.1选取爬虫策略——缩略图首先打开开发者模式,观察网页结构,找到每一张图对应的的图片标签,可以发现我们只要获取到标黄的i...
继续阅读 >
前言python基础爬虫主要针对一些反爬机制较为简单的网站,是对爬虫整个过程的了解与爬虫策略的熟练过程。爬虫分为四个步骤:请求,解析数据,提取数据,存储数据。本文也会从这四个角度介绍基础爬虫的案例。一、简单静态网页的爬取我们要爬取的是一个壁纸网站的所有壁纸http://www.netbian.com/dongman/1.1选取爬虫策略——缩略图首先打开开发者模式,观察网页结构,找到每一张图对应的的图片标签,可以发现我们只要获取到标黄的i...
继续阅读 >
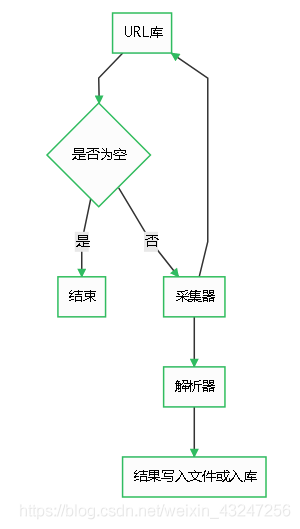 前言本文目的:根据本人的习惯与理解,用最简洁的表述,介绍爬虫的定义、组成部分、爬取流程,并讲解示例代码。基础爬虫的定义:定向抓取互联网内容(大部分为网页)、并进行自动化数据处理的程序。主要用于对松散的海量信息进行收集和结构化处理,为数据分析和挖掘提供原材料。今日t条就是一只巨大的“爬虫”。爬虫由URL库、采集器、解析器组成。流程如果待爬取的url库不为空,采集器会自动爬取相关内容,并将结果给到解析器,解...
前言本文目的:根据本人的习惯与理解,用最简洁的表述,介绍爬虫的定义、组成部分、爬取流程,并讲解示例代码。基础爬虫的定义:定向抓取互联网内容(大部分为网页)、并进行自动化数据处理的程序。主要用于对松散的海量信息进行收集和结构化处理,为数据分析和挖掘提供原材料。今日t条就是一只巨大的“爬虫”。爬虫由URL库、采集器、解析器组成。流程如果待爬取的url库不为空,采集器会自动爬取相关内容,并将结果给到解析器,解...
 本文主要涉及python爬虫知识点:web是如何交互的requests库的get、post函数的应用response对象的相关函数,属性python文件的打开,保存代码中给出了注释,并且可以直接运行哦如何安装requests库(安装好python的朋友可以直接参考,没有的,建议先装一哈python环境)windows用户,Linux用户几乎一样:打开cmd输入以下命令即可,如果python的环境在C盘的目录,会提示权限不够,只需以管理员方式运行cmd窗口pipinstall-ihttps://pypi.t...
本文主要涉及python爬虫知识点:web是如何交互的requests库的get、post函数的应用response对象的相关函数,属性python文件的打开,保存代码中给出了注释,并且可以直接运行哦如何安装requests库(安装好python的朋友可以直接参考,没有的,建议先装一哈python环境)windows用户,Linux用户几乎一样:打开cmd输入以下命令即可,如果python的环境在C盘的目录,会提示权限不够,只需以管理员方式运行cmd窗口pipinstall-ihttps://pypi.t...