
2023
01-13
01-13
python爬虫Scrapy框架:媒体管道原理学习分析
 目录一、媒体管道1.1、媒体管道的特性媒体管道实现了以下特性:图像管道具有一些额外的图像处理功能:1.2、媒体管道的设置二、ImagesPipeline类简介三、小案例:使用图片管道爬取百度图片3.1、spider文件3.2、items文件3.3、settings文件3.4、pipelines文件一、媒体管道1.1、媒体管道的特性媒体管道实现了以下特性:避免重新下载最近下载的媒体指定存储位置(文件系统目录,AmazonS3bucket,谷歌云存储bucket)图像管道具有...
继续阅读 >
目录一、媒体管道1.1、媒体管道的特性媒体管道实现了以下特性:图像管道具有一些额外的图像处理功能:1.2、媒体管道的设置二、ImagesPipeline类简介三、小案例:使用图片管道爬取百度图片3.1、spider文件3.2、items文件3.3、settings文件3.4、pipelines文件一、媒体管道1.1、媒体管道的特性媒体管道实现了以下特性:避免重新下载最近下载的媒体指定存储位置(文件系统目录,AmazonS3bucket,谷歌云存储bucket)图像管道具有...
继续阅读 >
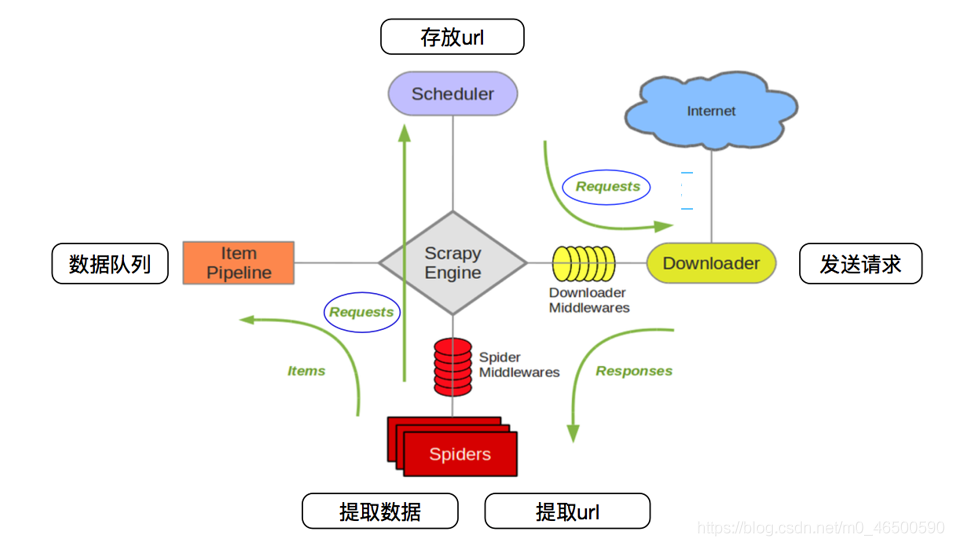 一、介绍官方文档:中文2.3版本下面这张图大家应该很熟悉,很多有关scrapy框架的介绍中都会出现这张图,感兴趣的再去查询相关资料,当然学会使用scrapy才是最主要的。二、基本使用2.1环境安装1.linux和mac操作系统:pipinstallscrapy2.windows系统:先安装wheel:pipinstallwheel下载twisted:下载地址安装twisted:pipinstallTwisted‑17.1.0‑cp36‑cp36m‑win_amd64.whl(记得带后缀)pipi...
一、介绍官方文档:中文2.3版本下面这张图大家应该很熟悉,很多有关scrapy框架的介绍中都会出现这张图,感兴趣的再去查询相关资料,当然学会使用scrapy才是最主要的。二、基本使用2.1环境安装1.linux和mac操作系统:pipinstallscrapy2.windows系统:先安装wheel:pipinstallwheel下载twisted:下载地址安装twisted:pipinstallTwisted‑17.1.0‑cp36‑cp36m‑win_amd64.whl(记得带后缀)pipi...
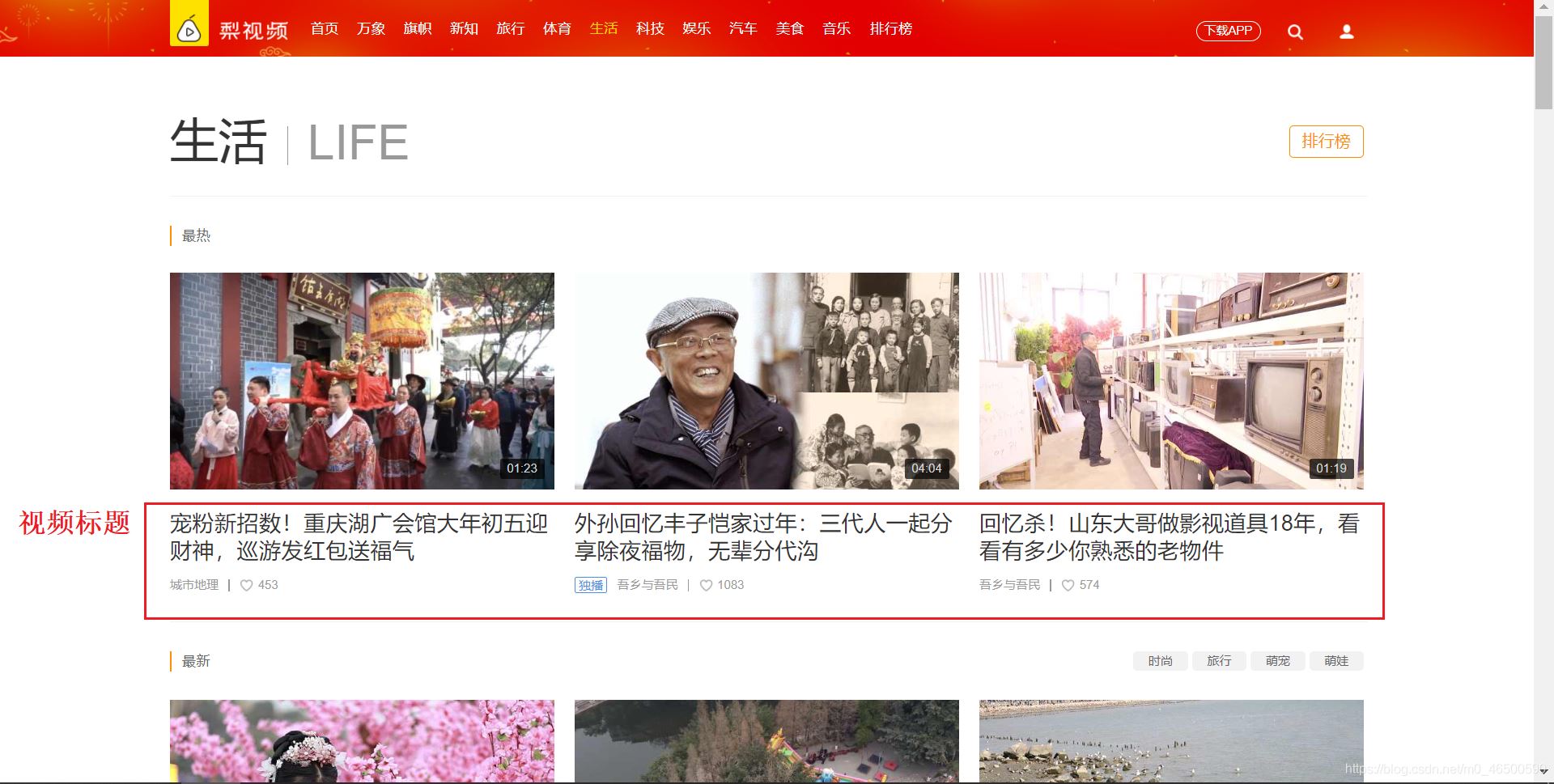 之前我们使用lxml对梨视频网站中的视频进行了下载,感兴趣的朋友点击查看吧。下面我用scrapy框架对梨视频网站中的视频标题和视频页中对视频的描述进行爬取分析:我们要爬取的内容并不在同一个页面,视频描述内容需要我们点开视频,跳转到新的url中才能获取,我们就不能在一个方法中去解析我们需要的不同内容1.爬虫文件这里我们可以仿照爬虫文件中的parse方法,写一个新的parse方法,可以将新的url的响应对象传给这个新的parse方...
之前我们使用lxml对梨视频网站中的视频进行了下载,感兴趣的朋友点击查看吧。下面我用scrapy框架对梨视频网站中的视频标题和视频页中对视频的描述进行爬取分析:我们要爬取的内容并不在同一个页面,视频描述内容需要我们点开视频,跳转到新的url中才能获取,我们就不能在一个方法中去解析我们需要的不同内容1.爬虫文件这里我们可以仿照爬虫文件中的parse方法,写一个新的parse方法,可以将新的url的响应对象传给这个新的parse方...