
2021
05-20
05-20
R语言中文本文件分割 符号 sep的用法
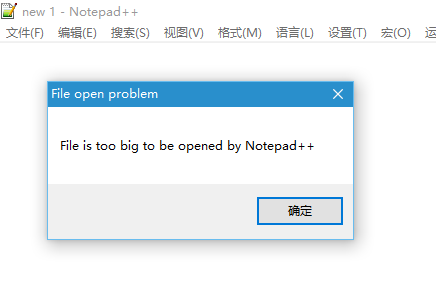 一般情况下:csv文件sep=“,”#以逗号分割txt文件sep=“\t”#以制表符分割其他文件sep=""#以空格分割具体情况,具体调整sep=文件中的字段分离符,用于文件数据文本的读取和保存过程中指定分割符号。补充:用R语言把超大文本文件拆分成几个小文本文件近一段时间一直在研究一些医院的数据。前两天遇到一个尴尬:想打开一个仅有3G左右的文本文件(有时候必须要打开,直接传到数据库满足不了需求),破电脑(4G内存的...
继续阅读 >
一般情况下:csv文件sep=“,”#以逗号分割txt文件sep=“\t”#以制表符分割其他文件sep=""#以空格分割具体情况,具体调整sep=文件中的字段分离符,用于文件数据文本的读取和保存过程中指定分割符号。补充:用R语言把超大文本文件拆分成几个小文本文件近一段时间一直在研究一些医院的数据。前两天遇到一个尴尬:想打开一个仅有3G左右的文本文件(有时候必须要打开,直接传到数据库满足不了需求),破电脑(4G内存的...
继续阅读 >
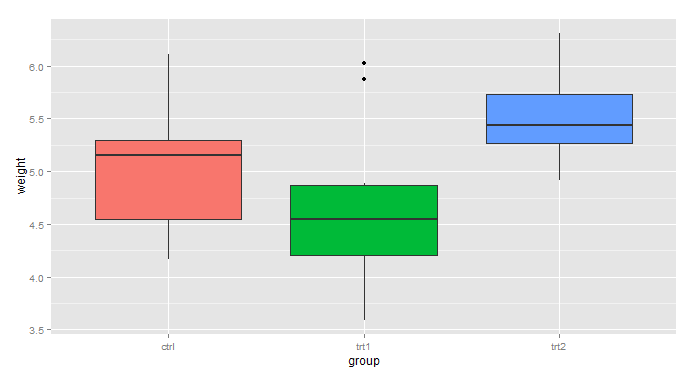 引言图例的设置包括移除图例、改变图例的位置、改变标签的顺序、改变图例的标题等。移除图例有时候你想移除图例,使用guides()。library(ggplot2)p<-ggplot(PlantGrowth,aes(x=group,y=weight,fill=group))+geom_boxplot()p+guides(fill=FALSE)改变图例的位置我们可以用theme(legend.position=…)将图例移到图表的上方、下方、左边和右边。p<-ggplot(PlantGrowth,aes(x=group,y=weight,fill=group))+geom_boxplot...
引言图例的设置包括移除图例、改变图例的位置、改变标签的顺序、改变图例的标题等。移除图例有时候你想移除图例,使用guides()。library(ggplot2)p<-ggplot(PlantGrowth,aes(x=group,y=weight,fill=group))+geom_boxplot()p+guides(fill=FALSE)改变图例的位置我们可以用theme(legend.position=…)将图例移到图表的上方、下方、左边和右边。p<-ggplot(PlantGrowth,aes(x=group,y=weight,fill=group))+geom_boxplot...
 assign函数在循环时候,给变量赋值,算是比较方便1、给变量赋值for(iin1:(length(rowSeq)-1)){assign(paste("nginx_server_fields7_",i,sep=""),nginx_server_fields7[(rowSeq[(i-1)+1]):(rowSeq[i+1]),])}2、通过for循环给变量a1、a2、a3赋值for(iin1:3){assign(paste("a",i,sep=""),i:10)}ls()[1]"a1""a2""a3""i">a1[1]12345678910>a2[1]23456789103、get和a...
assign函数在循环时候,给变量赋值,算是比较方便1、给变量赋值for(iin1:(length(rowSeq)-1)){assign(paste("nginx_server_fields7_",i,sep=""),nginx_server_fields7[(rowSeq[(i-1)+1]):(rowSeq[i+1]),])}2、通过for循环给变量a1、a2、a3赋值for(iin1:3){assign(paste("a",i,sep=""),i:10)}ls()[1]"a1""a2""a3""i">a1[1]12345678910>a2[1]23456789103、get和a...
 1、只有负下标里才能有零先看一个例子>a<-c(1,2,3,4)>a[-1:1]>a[-1:1]Errorina[-1:1]:只有负下标里才能有零(1)只有负下标里才能有零,在这里的意思为:a[-1:0]可行a[0:4]也可行a[-1:1]不可行也就是说要么是负索引到0,或者0到正索引,但不能同时出现正负索引。(2)a[0]结果为numberic(0),结果没有意义,如>a[0]+10.9numeric(0)>a[1]+10.9[1]11.9索引为0,不会得到正确的结果,但不会报错。2、容易混淆的例子>a<-c(1,2...
1、只有负下标里才能有零先看一个例子>a<-c(1,2,3,4)>a[-1:1]>a[-1:1]Errorina[-1:1]:只有负下标里才能有零(1)只有负下标里才能有零,在这里的意思为:a[-1:0]可行a[0:4]也可行a[-1:1]不可行也就是说要么是负索引到0,或者0到正索引,但不能同时出现正负索引。(2)a[0]结果为numberic(0),结果没有意义,如>a[0]+10.9numeric(0)>a[1]+10.9[1]11.9索引为0,不会得到正确的结果,但不会报错。2、容易混淆的例子>a<-c(1,2...
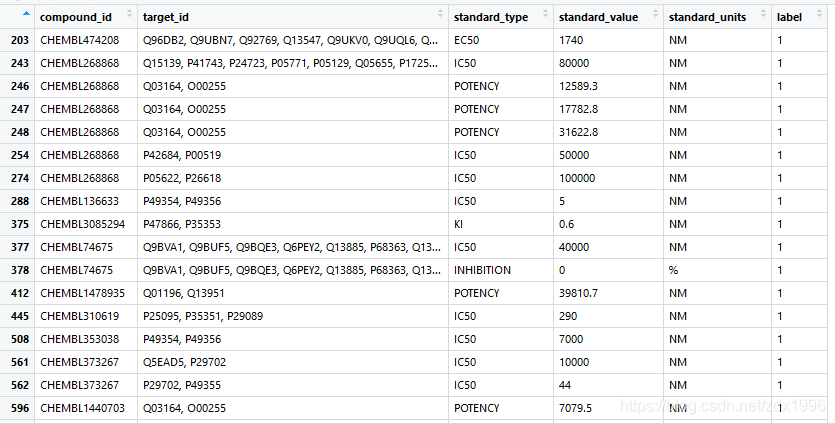 总的来说,R的运算速度不算快,不过类似并行运算之类的改进可以提高运算的性能。下面非常简要地介绍如何利用R语言进行并行运算library(parallel)cl.cores<-detectCores()cl<-makeCluster(cl.cores)detectCores()检查当前电脑可用核数。makeCluster(cl.cores)使用刚才检测的核并行运算。R-Doc里这样描述makeCluster函数:CreatesasetofcopiesofRrunninginparallelandcommunicatingoversockets.即同时创建数个R进...
总的来说,R的运算速度不算快,不过类似并行运算之类的改进可以提高运算的性能。下面非常简要地介绍如何利用R语言进行并行运算library(parallel)cl.cores<-detectCores()cl<-makeCluster(cl.cores)detectCores()检查当前电脑可用核数。makeCluster(cl.cores)使用刚才检测的核并行运算。R-Doc里这样描述makeCluster函数:CreatesasetofcopiesofRrunninginparallelandcommunicatingoversockets.即同时创建数个R进...
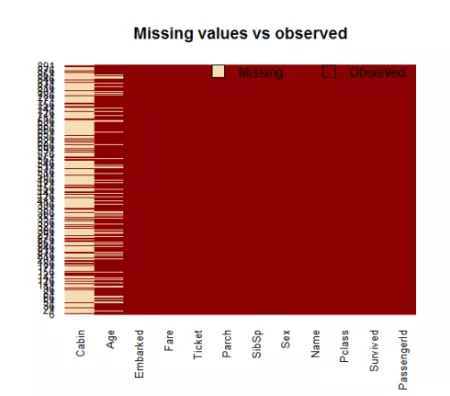 逻辑回归是拟合回归曲线的方法,当y是分类变量时,y=f(x)。典型的使用这种模式被预测Ÿ给定一组预测的X。预测因子可以是连续的,分类的或两者的混合。R中的逻辑回归实现R可以很容易地拟合逻辑回归模型。要调用的函数是glm(),拟合过程与线性回归中使用的过程没有太大差别。在这篇文章中,我将拟合一个二元逻辑回归模型并解释每一步。数据集我们将研究泰坦尼克号数据集。这个数据集有不同版本可以在线免费获得,但我建议使...
逻辑回归是拟合回归曲线的方法,当y是分类变量时,y=f(x)。典型的使用这种模式被预测Ÿ给定一组预测的X。预测因子可以是连续的,分类的或两者的混合。R中的逻辑回归实现R可以很容易地拟合逻辑回归模型。要调用的函数是glm(),拟合过程与线性回归中使用的过程没有太大差别。在这篇文章中,我将拟合一个二元逻辑回归模型并解释每一步。数据集我们将研究泰坦尼克号数据集。这个数据集有不同版本可以在线免费获得,但我建议使...
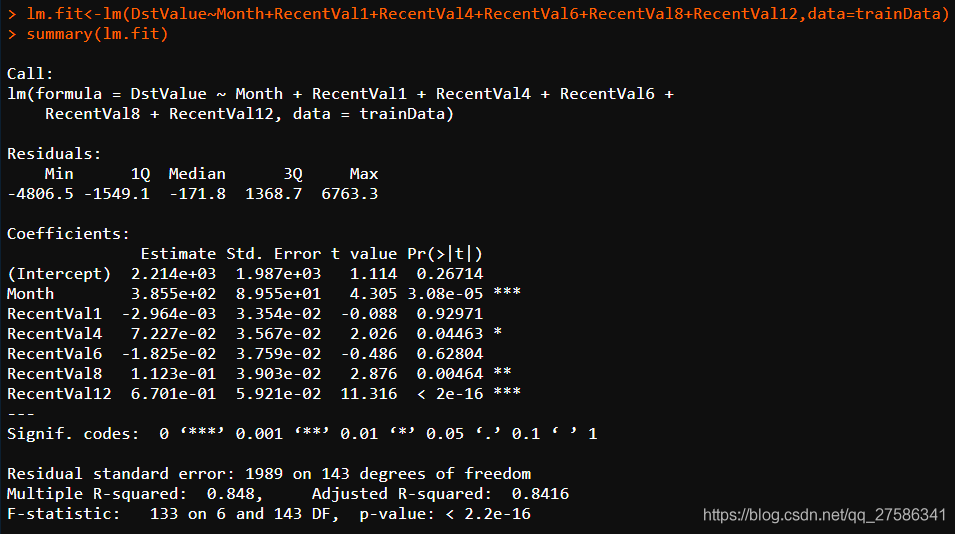 summary():获取描述性统计量,可以提供最小值、最大值、四分位数和数值型变量的均值,以及因子向量和逻辑型向量的频数统计等。结果解读如下:1.调用:Calllm(formula=DstValue~Month+RecentVal1+RecentVal4+RecentVal6+RecentVal8+RecentVal12,data=trainData)当创建模型时,以上代码表明lm是如何被调用的。2.残差统计量:ResidualsMin1QMedian3QMax...
summary():获取描述性统计量,可以提供最小值、最大值、四分位数和数值型变量的均值,以及因子向量和逻辑型向量的频数统计等。结果解读如下:1.调用:Calllm(formula=DstValue~Month+RecentVal1+RecentVal4+RecentVal6+RecentVal8+RecentVal12,data=trainData)当创建模型时,以上代码表明lm是如何被调用的。2.残差统计量:ResidualsMin1QMedian3QMax...
 R语言cut()函数使用cut()切割将x的范围划分为时间间隔,并根据其所处的时间间隔对x中的值进行编码。参数:breaks:两个或更多个唯一切割点或单个数字(大于或等于2)的数字向量,给出x被切割的间隔的个数。breaks采用fivenum():返回五个数据:最小值、下四分位数、中位数、上四分位数、最大值。labels为区间数,打标签ordered_result逻辑结果应该是一个有序的因素吗?先用fivenum求出5个数,再用labels为每两个数之间,贴标签,采...
R语言cut()函数使用cut()切割将x的范围划分为时间间隔,并根据其所处的时间间隔对x中的值进行编码。参数:breaks:两个或更多个唯一切割点或单个数字(大于或等于2)的数字向量,给出x被切割的间隔的个数。breaks采用fivenum():返回五个数据:最小值、下四分位数、中位数、上四分位数、最大值。labels为区间数,打标签ordered_result逻辑结果应该是一个有序的因素吗?先用fivenum求出5个数,再用labels为每两个数之间,贴标签,采...
 主要介绍tapply函数:每次只能求一列aggregate函数:每次按组可以求多列tapply(shuju[shuju[,3],shuju$year,mean)以年份为组,求shuju表第三列的均值aggregate(shuju[,3:4],list(shuju[,2]),mean)以年份为均值,求数据表第三列,第四列的均值补充:R语言按某一列分类求均值+绘图总结看代码吧~D<-aggregate(.~K,data=data1,mean)#求数据集data1按照K分类后所有列的均值rm(list=ls())#删除所有对象attach()#锁定某个对象with(...
主要介绍tapply函数:每次只能求一列aggregate函数:每次按组可以求多列tapply(shuju[shuju[,3],shuju$year,mean)以年份为组,求shuju表第三列的均值aggregate(shuju[,3:4],list(shuju[,2]),mean)以年份为均值,求数据表第三列,第四列的均值补充:R语言按某一列分类求均值+绘图总结看代码吧~D<-aggregate(.~K,data=data1,mean)#求数据集data1按照K分类后所有列的均值rm(list=ls())#删除所有对象attach()#锁定某个对象with(...