
2020
10-10
10-10
Pytho爬虫中Requests设置请求头Headers的方法
1、为什么要设置headers?在请求网页爬取的时候,输出的text信息中会出现抱歉,无法访问等字眼,这就是禁止爬取,需要通过反爬机制去解决这个问题。headers是解决requests请求反爬的方法之一,相当于我们进去这个网页的服务器本身,假装自己本身在爬取数据。对反爬虫网页,可以设置一些headers信息,模拟成浏览器取访问网站。2、headers在哪里找?谷歌或者火狐浏览器,在网页面上点击:右键?>检查?>剩余按照图中显示操作,...
继续阅读 >
 电脑环境:windows764位 python3.7问题:在PyCharm中,使用setting下的projectInterpreter安装pytest以及requests失败解决方法:(亲测有效)1、打开Gitbash,定位到python的安装目录:我的安装目录是D:\pythonAnZhuang\Python37\Scripts2、输入:pipinstallrequests,等待安装完成3、输入:pipinstallpytest,等待安装完成4、检测是否安装成功的方法: 第一种:piplist 可...
电脑环境:windows764位 python3.7问题:在PyCharm中,使用setting下的projectInterpreter安装pytest以及requests失败解决方法:(亲测有效)1、打开Gitbash,定位到python的安装目录:我的安装目录是D:\pythonAnZhuang\Python37\Scripts2、输入:pipinstallrequests,等待安装完成3、输入:pipinstallpytest,等待安装完成4、检测是否安装成功的方法: 第一种:piplist 可...
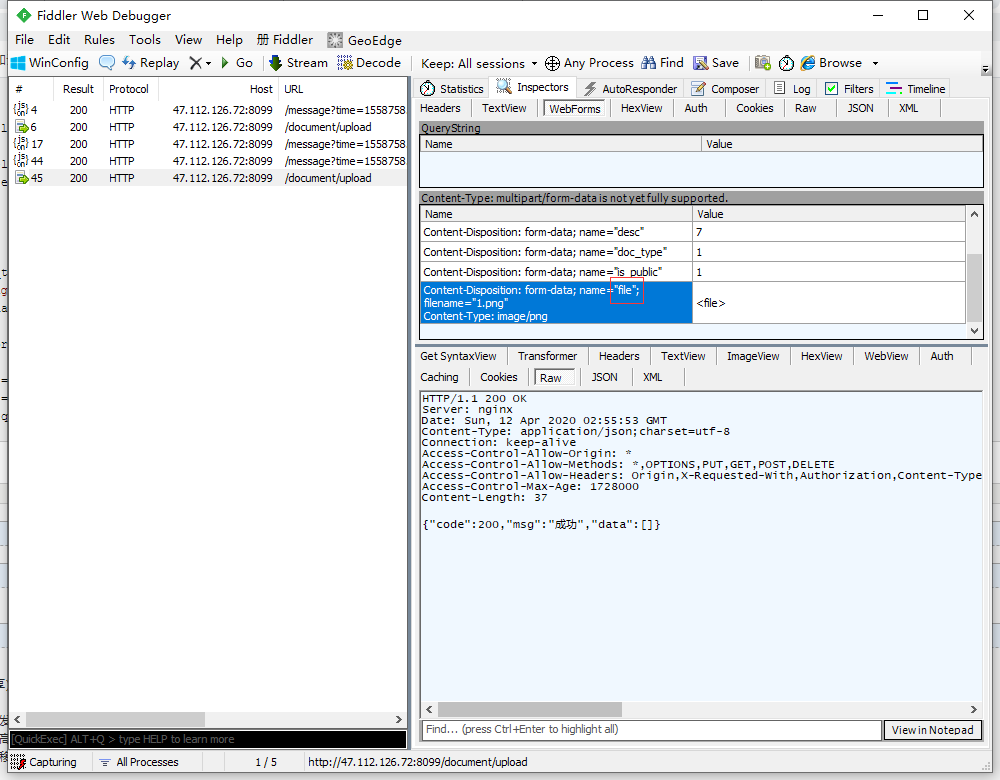 方法1:1.安装requests_toolbelt依赖库#代码实现defupload(self):login_token=self.token.loadTokenList()fortokeninlogin_token:tempPassword_url=self.config['crm_test_api']+'/document/upload'tempPassword_data=self.data_to_str.strToDict('''title:1.pngcourse_name_id:63course_id:1112desc:7doc_type:1is_public:1''',value_type='str')files={'file...
方法1:1.安装requests_toolbelt依赖库#代码实现defupload(self):login_token=self.token.loadTokenList()fortokeninlogin_token:tempPassword_url=self.config['crm_test_api']+'/document/upload'tempPassword_data=self.data_to_str.strToDict('''title:1.pngcourse_name_id:63course_id:1112desc:7doc_type:1is_public:1''',value_type='str')files={'file...
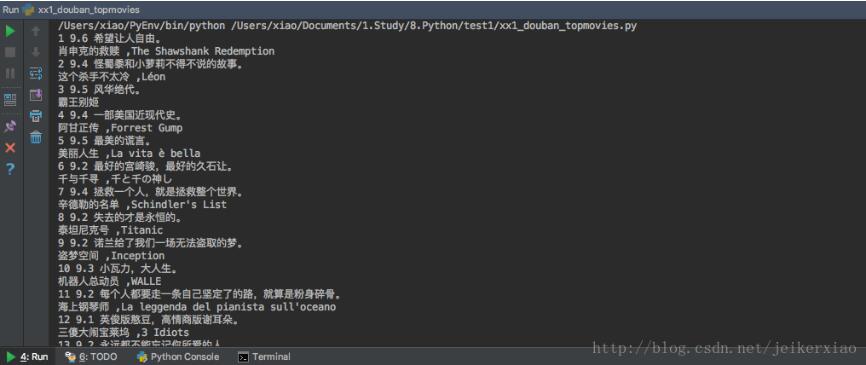 根据一个爬取豆瓣电影排名的小应用,来简单使用etree和request库。etree使用xpath语法。importrequestsimportsslfromlxmlimportetreessl._create_default_https_context=ssl._create_unverified_contextsession=requests.Session()foridinrange(0,251,25):URL='https://movie.douban.com/top250/?start='+str(id)req=session.get(URL)#设置网页编码格式req.encoding='utf8'#将request.content转...
根据一个爬取豆瓣电影排名的小应用,来简单使用etree和request库。etree使用xpath语法。importrequestsimportsslfromlxmlimportetreessl._create_default_https_context=ssl._create_unverified_contextsession=requests.Session()foridinrange(0,251,25):URL='https://movie.douban.com/top250/?start='+str(id)req=session.get(URL)#设置网页编码格式req.encoding='utf8'#将request.content转...