
2020
12-07
12-07
scrapy头部修改的方法详解
被Scrapy自动添加的头部在没有任何配置的情况下,scrapy会对请求默认加上一些头部信息Scrapy会通过配置文件中的USER_AGENT配置,自动为头部添加User-Agent,这条配置会被任何包含User-Agent的配置覆盖当请求经过下载器后,会被自动添加头部Accept-Encoding:gzip,deflate,会被任意包含Accept-Encoding的头部配置覆盖配置settings.py文件中默认的头部#DEFAULT_REQUEST_HEADERS={#'Accept':'text/html,application/xhtml+xml,ap...
继续阅读 >
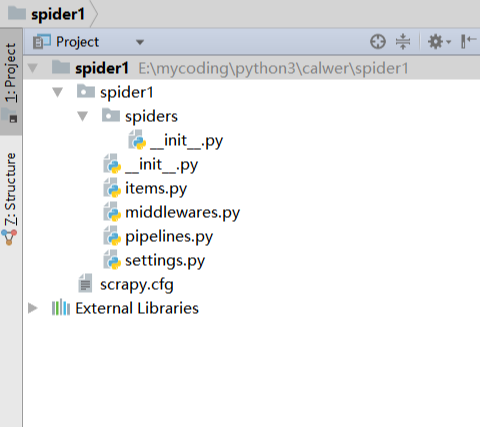 我们平时生活的娱乐中,看电影是大部分小伙伴都喜欢的事情。周围的人总会有意无意的在谈论,有什么影片上映,好不好看之类的话题,没事的时候谈论电影是非常不错的话题。那么,一些好看的影片如果不去电影院的话,在其他地方看都会有大大小小的限制,今天小编就教大家用python中的scrapy获取影片的办法吧。1. 创建项目运行命令:scrapystartprojectmyfrist(your_project_name)文件说明:名称|作用--|--scrapy.cfg|...
我们平时生活的娱乐中,看电影是大部分小伙伴都喜欢的事情。周围的人总会有意无意的在谈论,有什么影片上映,好不好看之类的话题,没事的时候谈论电影是非常不错的话题。那么,一些好看的影片如果不去电影院的话,在其他地方看都会有大大小小的限制,今天小编就教大家用python中的scrapy获取影片的办法吧。1. 创建项目运行命令:scrapystartprojectmyfrist(your_project_name)文件说明:名称|作用--|--scrapy.cfg|...
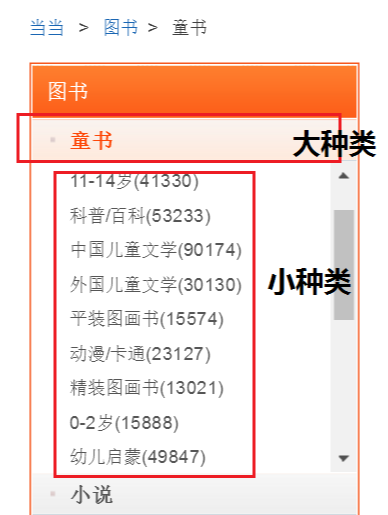 我们去图书馆的时候,会直接去自己喜欢的分类栏目找寻书籍。如果其中的分类不是很细致的话,想找某一本书还是有一些困难的。同样的如果我们获取了一些图书的数据,原始的文件里各种数据混杂在一起,非常不利于我们的查找和使用。所以今天小编教大家如何用python爬虫中scrapy给图书分类,大家一起学习下:spider抓取程序:在贴上代码之前,先对抓取的页面和链接做一个分析:网址:http://category.dangdang.com/pg4-cp01.25.17.00.0...
我们去图书馆的时候,会直接去自己喜欢的分类栏目找寻书籍。如果其中的分类不是很细致的话,想找某一本书还是有一些困难的。同样的如果我们获取了一些图书的数据,原始的文件里各种数据混杂在一起,非常不利于我们的查找和使用。所以今天小编教大家如何用python爬虫中scrapy给图书分类,大家一起学习下:spider抓取程序:在贴上代码之前,先对抓取的页面和链接做一个分析:网址:http://category.dangdang.com/pg4-cp01.25.17.00.0...
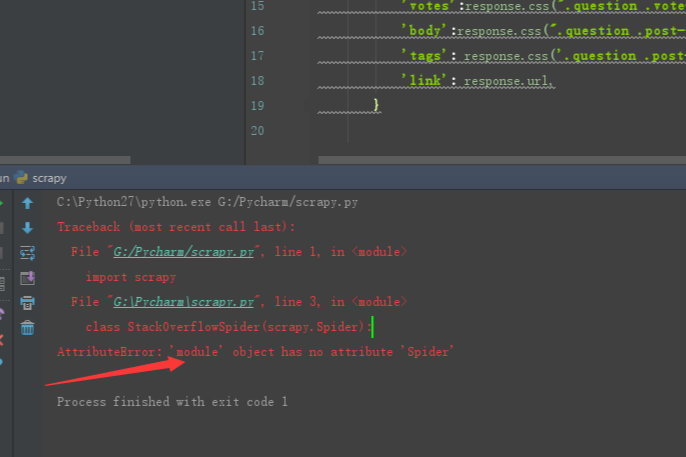 在之前文章给大家分享后不久,就有位小伙伴跟小编说在用scrapy搭建python爬虫中出现错误了。一开始的时候小编也没有看出哪里有问题,好在经过不断地讨论与测试,最终解决了出错点的问题。有同样出错的小伙伴可要好好看看到底是哪里疏忽了,小编这里先不说出问题点。问题描述:安装位置:环境变量:解决办法:文件命名叫scrapy.py,明显和scrapy自己的包名冲突了,这里classStackOverFlowSpider(scrapy.Spider)会直接找当前文件(s...
在之前文章给大家分享后不久,就有位小伙伴跟小编说在用scrapy搭建python爬虫中出现错误了。一开始的时候小编也没有看出哪里有问题,好在经过不断地讨论与测试,最终解决了出错点的问题。有同样出错的小伙伴可要好好看看到底是哪里疏忽了,小编这里先不说出问题点。问题描述:安装位置:环境变量:解决办法:文件命名叫scrapy.py,明显和scrapy自己的包名冲突了,这里classStackOverFlowSpider(scrapy.Spider)会直接找当前文件(s...
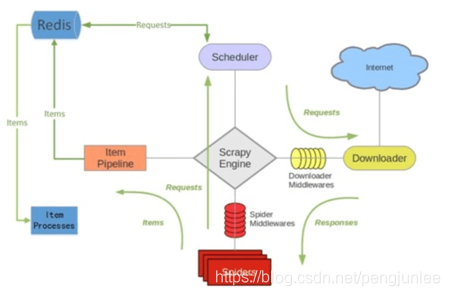 简介scrapy-redis是一个基于redis的scrapy组件,用于快速实现scrapy项目的分布式部署和数据爬取,其运行原理如下图所示。Scrapy-Redis特性分布式爬取你可以启动多个共享同一redis队列的爬虫实例,多个爬虫实例将各自提取到或者已请求的Requests在队列中统一进行登记,使得Scheduler在请求调度时能够对重复Requests进行过滤,即保证已经由某一个爬虫实例请求过的Request将不会再被其他的爬虫实例重复请求。分布式数据处理将scrapy爬...
简介scrapy-redis是一个基于redis的scrapy组件,用于快速实现scrapy项目的分布式部署和数据爬取,其运行原理如下图所示。Scrapy-Redis特性分布式爬取你可以启动多个共享同一redis队列的爬虫实例,多个爬虫实例将各自提取到或者已请求的Requests在队列中统一进行登记,使得Scheduler在请求调度时能够对重复Requests进行过滤,即保证已经由某一个爬虫实例请求过的Request将不会再被其他的爬虫实例重复请求。分布式数据处理将scrapy爬...
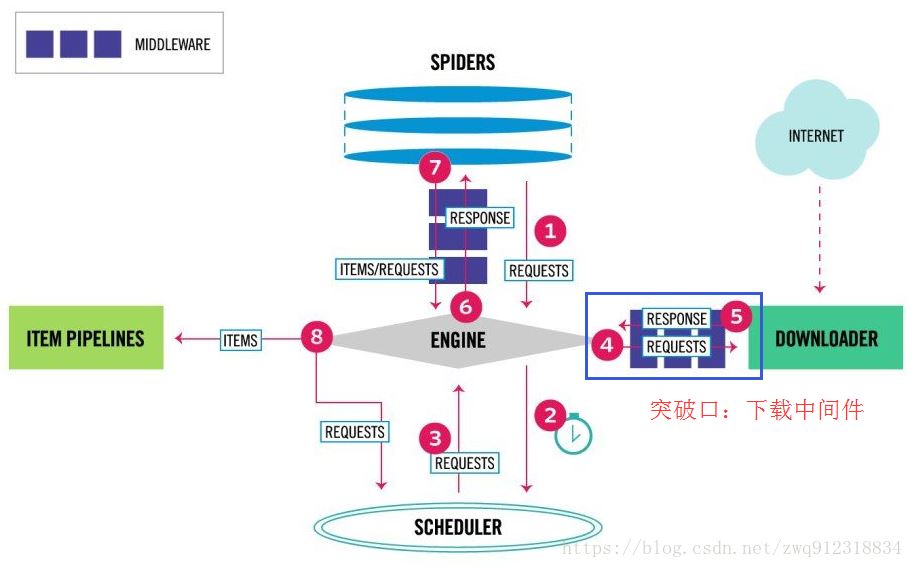 1.背景我们在爬取网页时一般会使用到三个爬虫库:requests,scrapy,selenium。requests一般用于小型爬虫,scrapy用于构建大的爬虫项目,而selenium主要用来应付负责的页面(复杂js渲染的页面,请求非常难构造,或者构造方式经常变化)。在我们面对大型爬虫项目时,肯定会优选scrapy框架来开发,但是在解析复杂JS渲染的页面时,又很麻烦。尽管使用selenium浏览器渲染来抓取这样的页面很方便,这种方式下,我们不需要关心页面...
1.背景我们在爬取网页时一般会使用到三个爬虫库:requests,scrapy,selenium。requests一般用于小型爬虫,scrapy用于构建大的爬虫项目,而selenium主要用来应付负责的页面(复杂js渲染的页面,请求非常难构造,或者构造方式经常变化)。在我们面对大型爬虫项目时,肯定会优选scrapy框架来开发,但是在解析复杂JS渲染的页面时,又很麻烦。尽管使用selenium浏览器渲染来抓取这样的页面很方便,这种方式下,我们不需要关心页面...
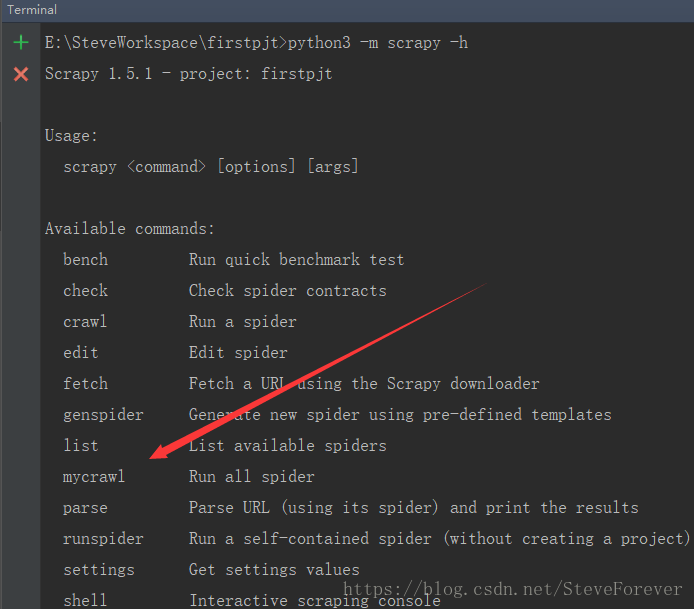 Scrapy批量运行爬虫文件的两种方法:1、使用CrawProcess实现https://doc.scrapy.org/en/latest/topics/practices.html2、修改craw源码+自定义命令的方式实现(1)我们打开scrapy.commands.crawl.py 文件可以看到:defrun(self,args,opts):iflen(args)<1:raiseUsageError()eliflen(args)>1:raiseUsageError("running'scrapycrawl'withmorethanonespiderisnolongersupported")s...
Scrapy批量运行爬虫文件的两种方法:1、使用CrawProcess实现https://doc.scrapy.org/en/latest/topics/practices.html2、修改craw源码+自定义命令的方式实现(1)我们打开scrapy.commands.crawl.py 文件可以看到:defrun(self,args,opts):iflen(args)<1:raiseUsageError()eliflen(args)>1:raiseUsageError("running'scrapycrawl'withmorethanonespiderisnolongersupported")s...
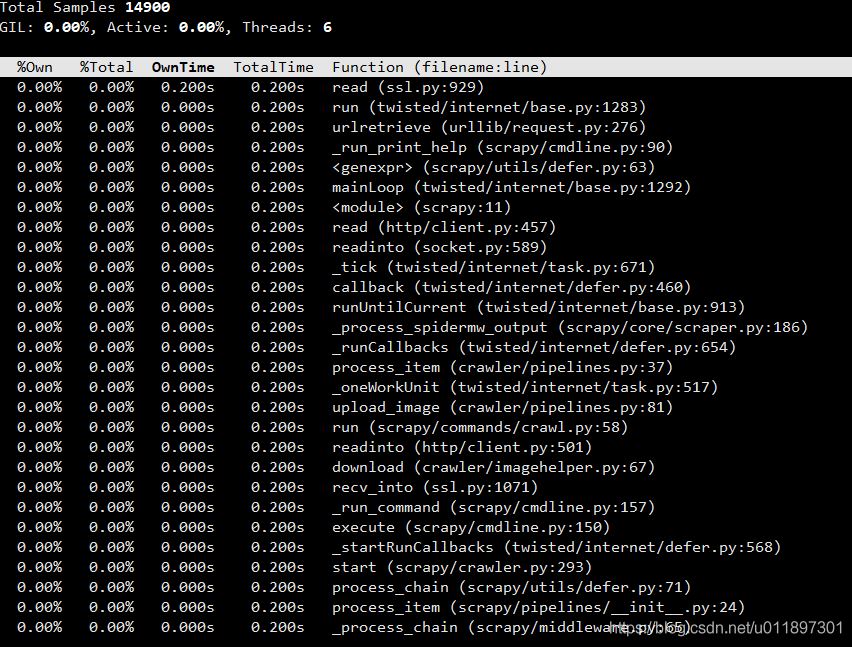 背景在使用scrapy爬取东西的时候,使用crontab定时的启动爬虫,但是发现机器上经常产生很多卡死的scrapy进程,一段时间不管的话,会导致有10几个进程都卡死在那,并且会导致数据产出延迟。问题定位使用py-spy这个非常好用的python性能分析工具来进行排查,py-spy可以查看一个python进程函数调用用时,类似unix下的top命令。所以我们用这个工具看看是什么函数一直在执行。首先安装这个工具pipinstallpy-spy用py-spy看看scrapy哪个...
背景在使用scrapy爬取东西的时候,使用crontab定时的启动爬虫,但是发现机器上经常产生很多卡死的scrapy进程,一段时间不管的话,会导致有10几个进程都卡死在那,并且会导致数据产出延迟。问题定位使用py-spy这个非常好用的python性能分析工具来进行排查,py-spy可以查看一个python进程函数调用用时,类似unix下的top命令。所以我们用这个工具看看是什么函数一直在执行。首先安装这个工具pipinstallpy-spy用py-spy看看scrapy哪个...
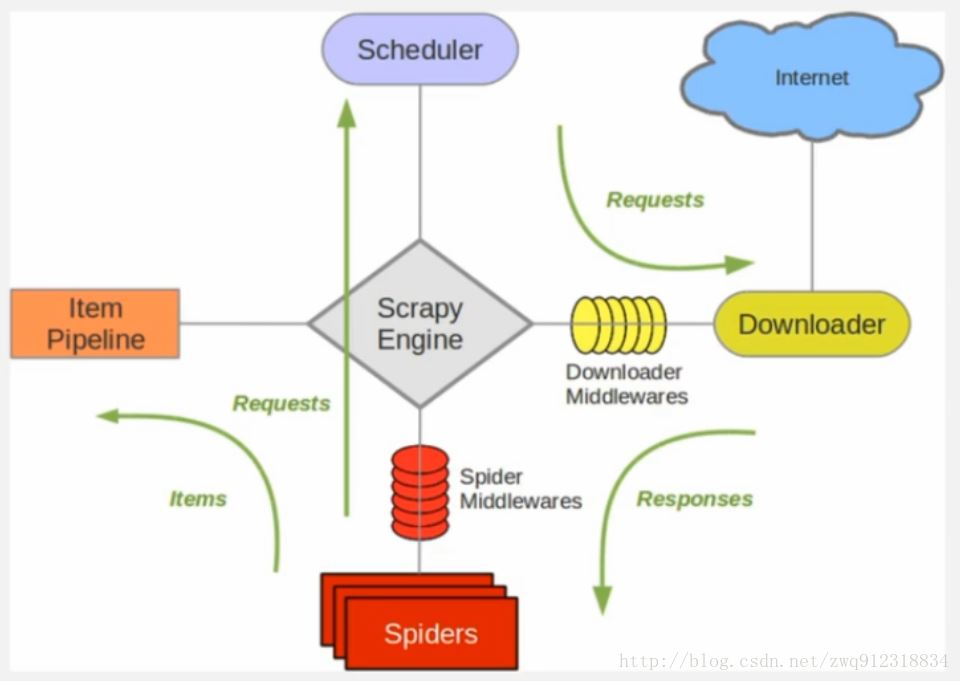 1.背景Scrapy是一个通用的爬虫框架,但是不支持分布式,Scrapy-redis是为了更方便地实现Scrapy分布式爬取,而提供了一些以redis为基础的组件(仅有组件)。 2.环境系统:win7scrapy-redisredis3.0.5python3.6.13.原理3.1.对比一下scrapy和Scrapy-redis的架构图。scrapy架构图:scrapy-redis架构图:多了一个redis组件,主要影响两个地方:第一个是调度器。第二个是数据的处理。3.2.Scrapy-Redis分布...
1.背景Scrapy是一个通用的爬虫框架,但是不支持分布式,Scrapy-redis是为了更方便地实现Scrapy分布式爬取,而提供了一些以redis为基础的组件(仅有组件)。 2.环境系统:win7scrapy-redisredis3.0.5python3.6.13.原理3.1.对比一下scrapy和Scrapy-redis的架构图。scrapy架构图:scrapy-redis架构图:多了一个redis组件,主要影响两个地方:第一个是调度器。第二个是数据的处理。3.2.Scrapy-Redis分布...