
2020
10-10
10-10
Scrapy基于scrapy_redis实现分布式爬虫部署的示例
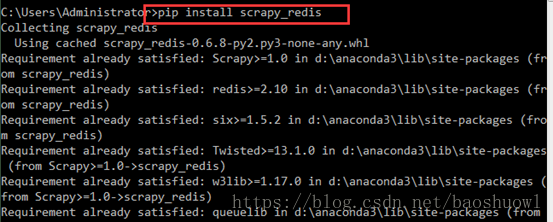 准备工作1.安装scrapy_redis包,打开cmd工具,执行命令pipinstallscrapy_redis2.准备好一个没有BUG,没有报错的爬虫项目3.准备好redis主服务器还有跟程序相关的mysql数据库前提mysql数据库要打开允许远程连接,因为mysql安装后root用户默认只允许本地连接,详情请看此文章部署过程1.修改爬虫项目的settings文件在下载的scrapy_redis包中,有一个scheduler.py文件,里面有一个Scheduler类,是用来调度url,还有一个dupefilter.py文件,里面...
继续阅读 >
准备工作1.安装scrapy_redis包,打开cmd工具,执行命令pipinstallscrapy_redis2.准备好一个没有BUG,没有报错的爬虫项目3.准备好redis主服务器还有跟程序相关的mysql数据库前提mysql数据库要打开允许远程连接,因为mysql安装后root用户默认只允许本地连接,详情请看此文章部署过程1.修改爬虫项目的settings文件在下载的scrapy_redis包中,有一个scheduler.py文件,里面有一个Scheduler类,是用来调度url,还有一个dupefilter.py文件,里面...
继续阅读 >
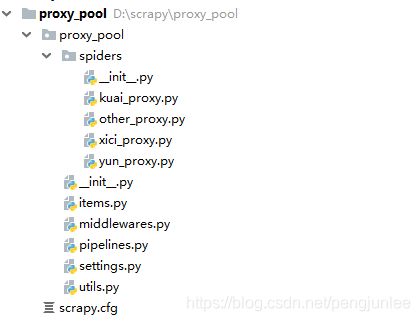 一、为什么要搭建爬虫代理池在众多的网站防爬措施中,有一种是根据ip的访问频率进行限制,即在某一时间段内,当某个ip的访问次数达到一定的阀值时,该ip就会被拉黑、在一段时间内禁止访问。应对的方法有两种:1.降低爬虫的爬取频率,避免IP被限制访问,缺点显而易见:会大大降低爬取的效率。2.搭建一个IP代理池,使用不同的IP轮流进行爬取。二、搭建思路1、从代理网站(如:西刺代理、快代理、云代理、无忧代理)爬取代理IP;2、验...
一、为什么要搭建爬虫代理池在众多的网站防爬措施中,有一种是根据ip的访问频率进行限制,即在某一时间段内,当某个ip的访问次数达到一定的阀值时,该ip就会被拉黑、在一段时间内禁止访问。应对的方法有两种:1.降低爬虫的爬取频率,避免IP被限制访问,缺点显而易见:会大大降低爬取的效率。2.搭建一个IP代理池,使用不同的IP轮流进行爬取。二、搭建思路1、从代理网站(如:西刺代理、快代理、云代理、无忧代理)爬取代理IP;2、验...
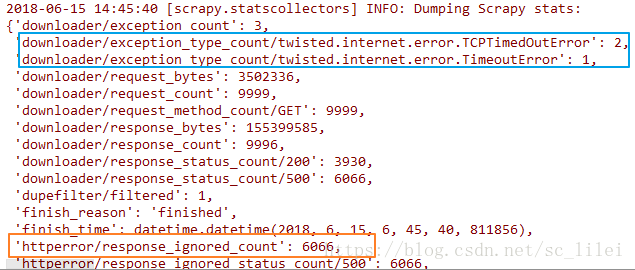 前言 使用scrapy进行大型爬取任务的时候(爬取耗时以天为单位),无论主机网速多好,爬完之后总会发现scrapy日志中“item_scraped_count”不等于预先的种子数量,总有一部分种子爬取失败,失败的类型可能有如下图两种(下图为scrapy爬取结束完成时的日志):scrapy中常见的异常包括但不限于:downloaderror(蓝色区域),httpcode403/500(橙色区域)。不管是哪种异常,我们都可以参考scrapy自带的retry中间件写法...
前言 使用scrapy进行大型爬取任务的时候(爬取耗时以天为单位),无论主机网速多好,爬完之后总会发现scrapy日志中“item_scraped_count”不等于预先的种子数量,总有一部分种子爬取失败,失败的类型可能有如下图两种(下图为scrapy爬取结束完成时的日志):scrapy中常见的异常包括但不限于:downloaderror(蓝色区域),httpcode403/500(橙色区域)。不管是哪种异常,我们都可以参考scrapy自带的retry中间件写法...
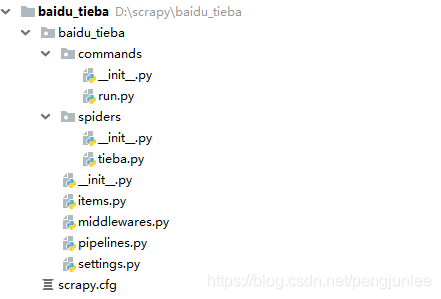 在使用Scrapy爬取数据时,有时会碰到需要根据传递给Spider的参数来决定爬取哪些Url或者爬取哪些页的情况。例如,百度贴吧的放置奇兵吧的地址如下,其中kw参数用来指定贴吧名称、pn参数用来对帖子进行翻页。https://tieba.baidu.com/f?kw=放置奇兵&ie=utf-8&pn=250如果我们希望通过参数传递的方式将贴吧名称和页数等参数传给Spider,来控制我们要爬取哪一个贴吧、爬取哪些页。遇到这种情况,有以下两种方法向Spider传递参数。...
在使用Scrapy爬取数据时,有时会碰到需要根据传递给Spider的参数来决定爬取哪些Url或者爬取哪些页的情况。例如,百度贴吧的放置奇兵吧的地址如下,其中kw参数用来指定贴吧名称、pn参数用来对帖子进行翻页。https://tieba.baidu.com/f?kw=放置奇兵&ie=utf-8&pn=250如果我们希望通过参数传递的方式将贴吧名称和页数等参数传给Spider,来控制我们要爬取哪一个贴吧、爬取哪些页。遇到这种情况,有以下两种方法向Spider传递参数。...
 scrapy框架只能爬取静态网站。如需爬取动态网站,需要结合着selenium进行js的渲染,才能获取到动态加载的数据。如何通过selenium请求url,而不再通过下载器Downloader去请求这个url?方法:在request对象通过中间件的时候,在中间件内部开始使用selenium去请求url,并且会得到url对应的源码,然后再将 源代码通过response对象返回,直接交给process_response()进行处理,再交给引擎。过程中相当于后续中间件的proc...
scrapy框架只能爬取静态网站。如需爬取动态网站,需要结合着selenium进行js的渲染,才能获取到动态加载的数据。如何通过selenium请求url,而不再通过下载器Downloader去请求这个url?方法:在request对象通过中间件的时候,在中间件内部开始使用selenium去请求url,并且会得到url对应的源码,然后再将 源代码通过response对象返回,直接交给process_response()进行处理,再交给引擎。过程中相当于后续中间件的proc...
 1.问题虽然scrapy能够完美且快速的抓取静态页面,但是在现实中,目前绝大多数网站的页面都是动态页面,动态页面中的部分内容是浏览器运行页面中的JavaScript脚本动态生成的,爬取相对困难;比如你信心满满的写好了一个爬虫,写好了目标内容的选择器,一跑起来发现根本找不到这个元素,当时肯定一万个黑人问号于是你在浏览器里打开F12,一顿操作,发现原来这你妹的是ajax加载的,不然就是硬编码在js代码里的,blabla的…然后...
1.问题虽然scrapy能够完美且快速的抓取静态页面,但是在现实中,目前绝大多数网站的页面都是动态页面,动态页面中的部分内容是浏览器运行页面中的JavaScript脚本动态生成的,爬取相对困难;比如你信心满满的写好了一个爬虫,写好了目标内容的选择器,一跑起来发现根本找不到这个元素,当时肯定一万个黑人问号于是你在浏览器里打开F12,一顿操作,发现原来这你妹的是ajax加载的,不然就是硬编码在js代码里的,blabla的…然后...