
2022
09-20
09-20
基于Docker+Selenium Grid的测试技术应用示例代码
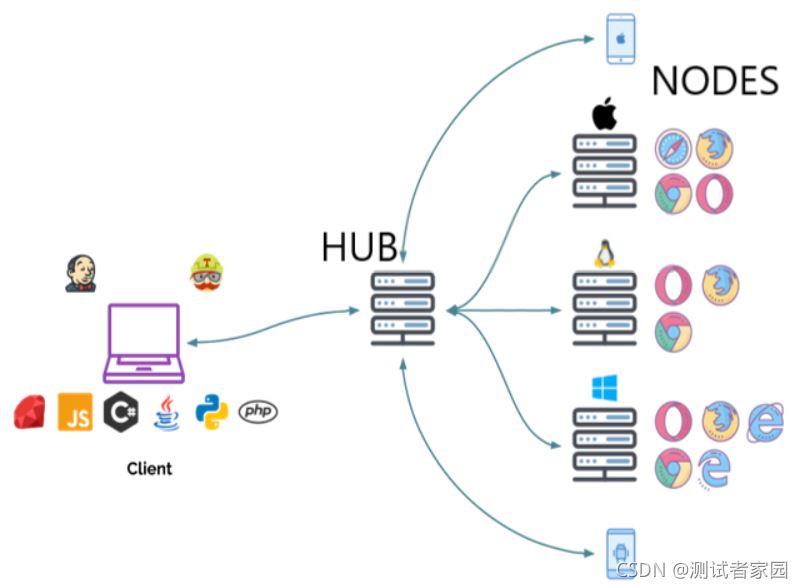 SeleniumGrid介绍尽管在未来将会推出的Selenium4.0版本中对SeleniumGrid的一些新特性进行了说明,但是目前来看官方并没有太多详细文档供大家参考,所以本书中仍结合目前被广泛使用的SeleniumGrid版本进行讲解。正如其官网对SeleniumGrid的描述,它是一个智能代理服务器,允许Selenium测试将命令路由到远程Web浏览器实例。其目的是提供一种在多台计算机上并行运行测试的简便方法。使用SeleniumGrid,一台服务器充当将JSON格...
继续阅读 >
SeleniumGrid介绍尽管在未来将会推出的Selenium4.0版本中对SeleniumGrid的一些新特性进行了说明,但是目前来看官方并没有太多详细文档供大家参考,所以本书中仍结合目前被广泛使用的SeleniumGrid版本进行讲解。正如其官网对SeleniumGrid的描述,它是一个智能代理服务器,允许Selenium测试将命令路由到远程Web浏览器实例。其目的是提供一种在多台计算机上并行运行测试的简便方法。使用SeleniumGrid,一台服务器充当将JSON格...
继续阅读 >
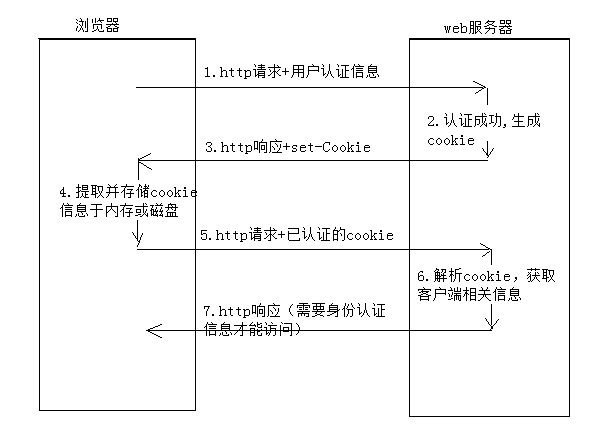 1、Cookie介绍HTTP协议是无状态的协议。一旦数据交换完毕,客户端与服务器端的连接就会关闭,再次交换数据需要建立新的连接,这就意味着服务器无法从连接上跟踪会话。也就是说即使第一次和服务器连接后并且登录成功后,第二次请求服务器依然不能知道当前请求是哪个用户。举个例子:用户A购买了一件商品放入购物车内,当再次购买商品时,服务器已经无法判断该购买行为是属于用户A的会话,还是用户B的会话了。要跟踪该会话,必须引入...
1、Cookie介绍HTTP协议是无状态的协议。一旦数据交换完毕,客户端与服务器端的连接就会关闭,再次交换数据需要建立新的连接,这就意味着服务器无法从连接上跟踪会话。也就是说即使第一次和服务器连接后并且登录成功后,第二次请求服务器依然不能知道当前请求是哪个用户。举个例子:用户A购买了一件商品放入购物车内,当再次购买商品时,服务器已经无法判断该购买行为是属于用户A的会话,还是用户B的会话了。要跟踪该会话,必须引入...
 目录一、为什么要使用等待?二、常用的三种等待方式三、强制等待四、隐式等待五、显示等待六、模块用法汇总一、为什么要使用等待?在自动化测试脚本的运行过程中,webdriver操作浏览器的时候,对于元素的定位是有一定的超时时间,大致在1-3秒如果这个时间内仍然定位不到元素,就会抛出异常,中止脚本执行我们可以通过在脚本中设置等待的方式来避免由于网络延迟或浏览器卡顿导致的偶然失败二、常用的三种等待方式强制等待隐...
目录一、为什么要使用等待?二、常用的三种等待方式三、强制等待四、隐式等待五、显示等待六、模块用法汇总一、为什么要使用等待?在自动化测试脚本的运行过程中,webdriver操作浏览器的时候,对于元素的定位是有一定的超时时间,大致在1-3秒如果这个时间内仍然定位不到元素,就会抛出异常,中止脚本执行我们可以通过在脚本中设置等待的方式来避免由于网络延迟或浏览器卡顿导致的偶然失败二、常用的三种等待方式强制等待隐...
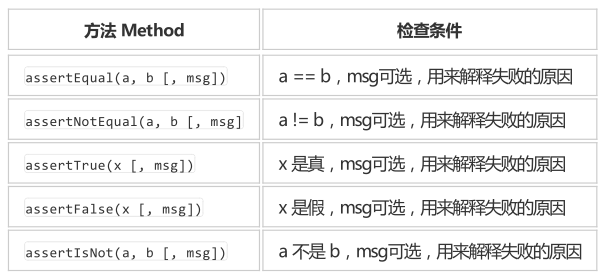 一、安装selenium打开命令控制符输入:pipinstall-Uselenium火狐浏览器安装firebug:www.firebug.com,调试所有网站语言,调试功能SeleniumIDE是嵌入到Firefox浏览器中的一个插件,实现简单的浏览器操作的录制与回放功能,IDE录制的脚本可以可以转换成多种语言,从而帮助我们快速的开发脚本,下载地址:https://addons.mozilla.org/en-US/firefox/addon/selenium-ide/如何使用IDE录制脚本:点击seleniumIDE——点击录制—...
一、安装selenium打开命令控制符输入:pipinstall-Uselenium火狐浏览器安装firebug:www.firebug.com,调试所有网站语言,调试功能SeleniumIDE是嵌入到Firefox浏览器中的一个插件,实现简单的浏览器操作的录制与回放功能,IDE录制的脚本可以可以转换成多种语言,从而帮助我们快速的开发脚本,下载地址:https://addons.mozilla.org/en-US/firefox/addon/selenium-ide/如何使用IDE录制脚本:点击seleniumIDE——点击录制—...
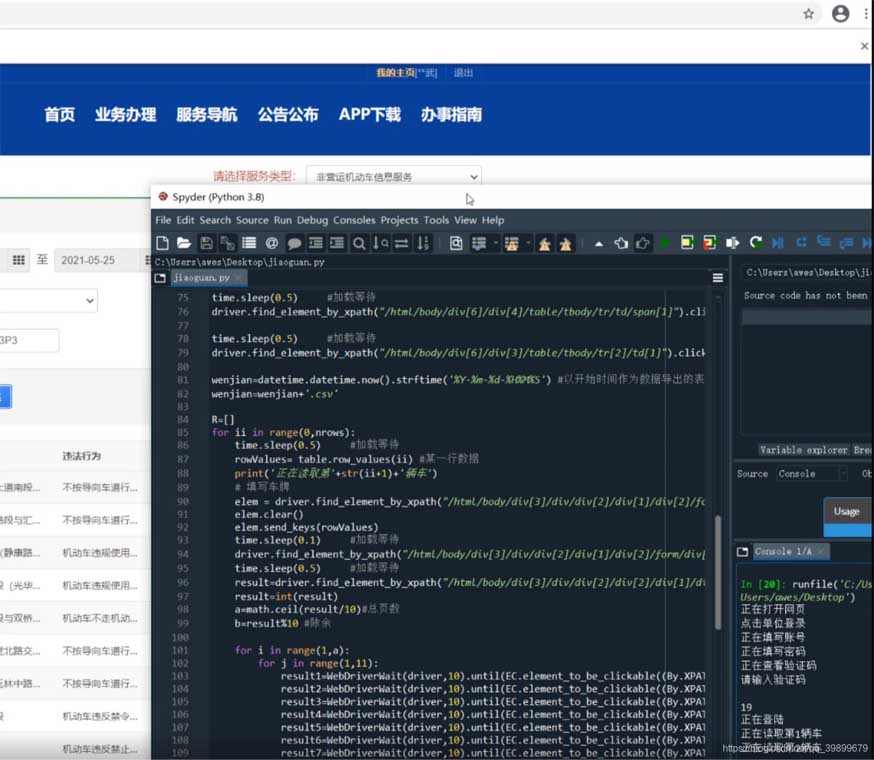 在上一篇文章《Python教程—模拟网页点击爬虫定位系统》讲解怎么通过模拟点击方式爬取车辆定位数据,本次介绍怎么以模拟点击方式进入交管12123爬取车辆违章数据,本文直接讲解过程,使用的命令解释见上一篇文章。本文同《Python教程—模拟网页点击爬虫定位系统》同样为企业中实际的爬虫案例,如果之后想进入车企行业可以做个了解。准备工具:spyder、selenium库、google浏览器及对应版本的chromedriver.exe效果注:分享此案例目的...
在上一篇文章《Python教程—模拟网页点击爬虫定位系统》讲解怎么通过模拟点击方式爬取车辆定位数据,本次介绍怎么以模拟点击方式进入交管12123爬取车辆违章数据,本文直接讲解过程,使用的命令解释见上一篇文章。本文同《Python教程—模拟网页点击爬虫定位系统》同样为企业中实际的爬虫案例,如果之后想进入车企行业可以做个了解。准备工具:spyder、selenium库、google浏览器及对应版本的chromedriver.exe效果注:分享此案例目的...
 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值。但是通过观察我们会发现,通过浏览器进行url请求发送则会加载出对应的动态加载出的数据。那么如果我们想要在scrapy也获取动态加载出的数据,则必须使用selenium创建浏览器对象,然后通过该浏览器对象进行请求发送,获取动态加载的数据值。本文重点给大家介绍sele...
在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值。但是通过观察我们会发现,通过浏览器进行url请求发送则会加载出对应的动态加载出的数据。那么如果我们想要在scrapy也获取动态加载出的数据,则必须使用selenium创建浏览器对象,然后通过该浏览器对象进行请求发送,获取动态加载的数据值。本文重点给大家介绍sele...
 介绍Selenium可以模拟浏览器进行自动化操作,但一些网站需要进行登录才能进行一些操作,比起输入账号密码,cookie是更加方便的。而且fofa首先登录邮箱账号时获得的cookie并不是fofa的cookie,因此我们直接选择利用fofa的cookie进行自动登录。但是selenium需要先打开一个网站才会加载进去cookies,因此我们需要将cookies写在代码中,加载进去扩展get_cookies():获得所有cookie信息。get_cookie(name):返回字典的key为“...
介绍Selenium可以模拟浏览器进行自动化操作,但一些网站需要进行登录才能进行一些操作,比起输入账号密码,cookie是更加方便的。而且fofa首先登录邮箱账号时获得的cookie并不是fofa的cookie,因此我们直接选择利用fofa的cookie进行自动登录。但是selenium需要先打开一个网站才会加载进去cookies,因此我们需要将cookies写在代码中,加载进去扩展get_cookies():获得所有cookie信息。get_cookie(name):返回字典的key为“...
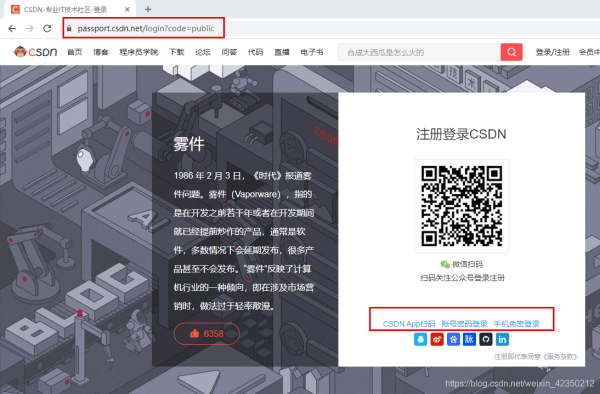 一、页面分析CSDN登录页面如下图二、引入selenium模块及驱动2.1并将安装好的Chromedriver.exe引入到代码中#-*-coding:utf-8-*-fromseleniumimportwebdriverimportosimporttime#引入chromedriver.exechromedriver="C:/Users/lex/AppData/Local/Google/Chrome/Application/chromedriver.exe"os.environ["webdriver.chrome.driver"]=chromedriverbrowser=webdriver.Chrome(chromedriver)2.2浏览器驱动引入将驱动下载...
一、页面分析CSDN登录页面如下图二、引入selenium模块及驱动2.1并将安装好的Chromedriver.exe引入到代码中#-*-coding:utf-8-*-fromseleniumimportwebdriverimportosimporttime#引入chromedriver.exechromedriver="C:/Users/lex/AppData/Local/Google/Chrome/Application/chromedriver.exe"os.environ["webdriver.chrome.driver"]=chromedriverbrowser=webdriver.Chrome(chromedriver)2.2浏览器驱动引入将驱动下载...
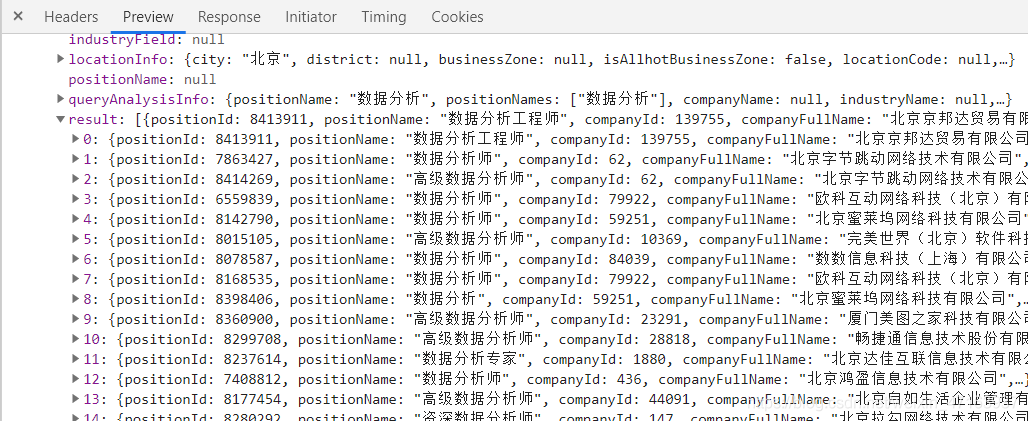 一、前言利用selenium+requests访问页面爬取拉勾网招聘信息二、分析url观察页面可知,页面数据属于动态加载所以现在我们通过抓包工具,获取数据包观察其url和参数url="https://www.lagou.com/jobs/positionAjax.json?px=default&needAddtionalResult=false"参数:city=%E5%8C%97%E4%BA%AC==》城市first=true==》无用pn=1==》页数kd=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90==》商品关键词所以我们要想实现全站爬取,需...
一、前言利用selenium+requests访问页面爬取拉勾网招聘信息二、分析url观察页面可知,页面数据属于动态加载所以现在我们通过抓包工具,获取数据包观察其url和参数url="https://www.lagou.com/jobs/positionAjax.json?px=default&needAddtionalResult=false"参数:city=%E5%8C%97%E4%BA%AC==》城市first=true==》无用pn=1==》页数kd=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90==》商品关键词所以我们要想实现全站爬取,需...
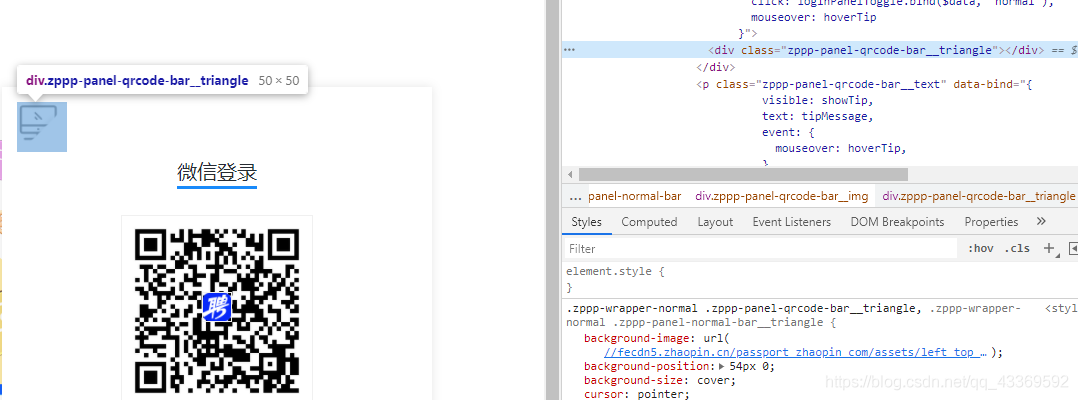 一、主要目的最近在玩Python网络爬虫,然后接触到了selenium这个模块,就捉摸着搞点有意思的,顺便记录一下自己的学习过程。二、前期准备操作系统:windows10浏览器:谷歌浏览器(GoogleChrome)浏览器驱动:chromedriver.exe(我的版本—>89.0.4389.128)程序中我使用的模块importcsvimportosimportreimportjsonimporttimeimportrequestsfromselenium.webdriverimportChromefromselenium.webdriver.re...
一、主要目的最近在玩Python网络爬虫,然后接触到了selenium这个模块,就捉摸着搞点有意思的,顺便记录一下自己的学习过程。二、前期准备操作系统:windows10浏览器:谷歌浏览器(GoogleChrome)浏览器驱动:chromedriver.exe(我的版本—>89.0.4389.128)程序中我使用的模块importcsvimportosimportreimportjsonimporttimeimportrequestsfromselenium.webdriverimportChromefromselenium.webdriver.re...
 前言在CSDN发的第一篇文章,时隔两年,终于实现了爬微博的自由!本文可以解决微博预登录、识别“展开全文”并爬取完整数据、翻页设置等问题。由于刚接触爬虫,有部分术语可能用的不正确,请大家多指正!一、区分动态爬虫和静态爬虫1、静态网页静态网页是纯粹的HTML,没有后台数据库,不含程序,不可交互,体量较少,加载速度快。静态网页的爬取只需四个步骤:发送请求、获取相应内容、解析内容及保存数据。2、动态网页动态网页上的...
前言在CSDN发的第一篇文章,时隔两年,终于实现了爬微博的自由!本文可以解决微博预登录、识别“展开全文”并爬取完整数据、翻页设置等问题。由于刚接触爬虫,有部分术语可能用的不正确,请大家多指正!一、区分动态爬虫和静态爬虫1、静态网页静态网页是纯粹的HTML,没有后台数据库,不含程序,不可交互,体量较少,加载速度快。静态网页的爬取只需四个步骤:发送请求、获取相应内容、解析内容及保存数据。2、动态网页动态网页上的...
 前言前一篇autoit实现文件上传打包成.exe可执行文件后,每次只能传固定的那个图片,我们实际测试时候希望传不同的图片。这样每次调用的时候,在命令行里面加一个文件路径的参数就行。一、命令行参数1.参数化传入的参数,可以通过autoit的命令行参数:myProg.exeparam1“Thisisastringparameter”99在脚本中,可用以下变量获取命令行参数:$CmdLine[0];=3$CmdLine[1];=param1$CmdLine[2];="Thisisastringpara...
前言前一篇autoit实现文件上传打包成.exe可执行文件后,每次只能传固定的那个图片,我们实际测试时候希望传不同的图片。这样每次调用的时候,在命令行里面加一个文件路径的参数就行。一、命令行参数1.参数化传入的参数,可以通过autoit的命令行参数:myProg.exeparam1“Thisisastringparameter”99在脚本中,可用以下变量获取命令行参数:$CmdLine[0];=3$CmdLine[1];=param1$CmdLine[2];="Thisisastringpara...
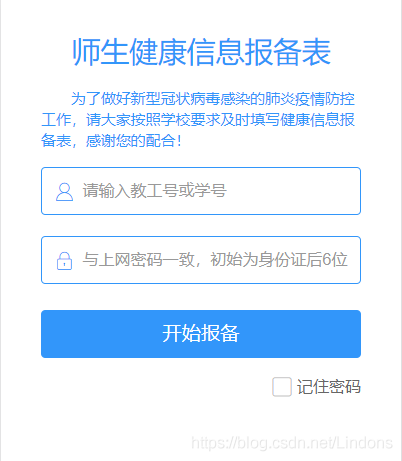 本文以某高校的健康报备系统为例,完成该web端的自动化操作,用到的技术栈如下所述:Docker\Selenium\Python\yagmail\ssh等基本思路:1、本地编写代码并进行测试2、新建docker容器并配置环境3、代码上传到服务器并复制到docker容器内4、解压、调试代码,确认代码没有问题后删除代码6、退出容器,并将容器制作成镜像7、用镜像实例化容器并挂载代码一、本地编写代码并调试先看一下我们需要进行操作的目标web:登录页面:表单...
本文以某高校的健康报备系统为例,完成该web端的自动化操作,用到的技术栈如下所述:Docker\Selenium\Python\yagmail\ssh等基本思路:1、本地编写代码并进行测试2、新建docker容器并配置环境3、代码上传到服务器并复制到docker容器内4、解压、调试代码,确认代码没有问题后删除代码6、退出容器,并将容器制作成镜像7、用镜像实例化容器并挂载代码一、本地编写代码并调试先看一下我们需要进行操作的目标web:登录页面:表单...