
2020
11-19
11-19
如何在scrapy中集成selenium爬取网页的方法
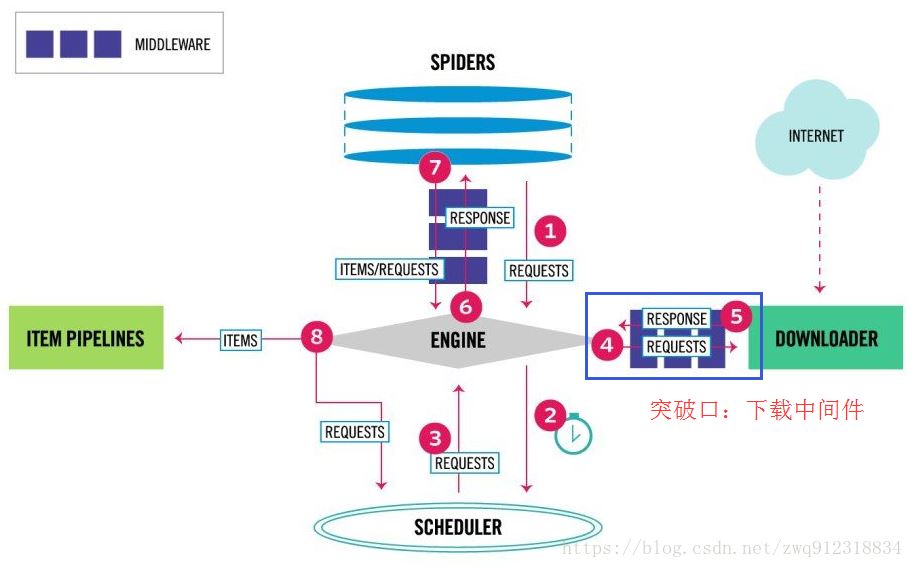 1.背景我们在爬取网页时一般会使用到三个爬虫库:requests,scrapy,selenium。requests一般用于小型爬虫,scrapy用于构建大的爬虫项目,而selenium主要用来应付负责的页面(复杂js渲染的页面,请求非常难构造,或者构造方式经常变化)。在我们面对大型爬虫项目时,肯定会优选scrapy框架来开发,但是在解析复杂JS渲染的页面时,又很麻烦。尽管使用selenium浏览器渲染来抓取这样的页面很方便,这种方式下,我们不需要关心页面...
继续阅读 >
1.背景我们在爬取网页时一般会使用到三个爬虫库:requests,scrapy,selenium。requests一般用于小型爬虫,scrapy用于构建大的爬虫项目,而selenium主要用来应付负责的页面(复杂js渲染的页面,请求非常难构造,或者构造方式经常变化)。在我们面对大型爬虫项目时,肯定会优选scrapy框架来开发,但是在解析复杂JS渲染的页面时,又很麻烦。尽管使用selenium浏览器渲染来抓取这样的页面很方便,这种方式下,我们不需要关心页面...
继续阅读 >