
2022
05-17
05-17
python库sklearn常用操作
目录前言一、MinMaxScaler前言sklearn是python的重要机器学习库,其中封装了大量的机器学习算法,如:分类、回归、降维以及聚类;还包含了监督学习、非监督学习、数据变换三大模块。sklearn拥有完善的文档,使得它具有了上手容易的优势;并它内置了大量的数据集,节省了获取和整理数据集的时间。因而,使其成为了广泛应用的重要的机器学习库。sklearn是一个无论对于机器学习还是深度学习都必不可少的重要的库,里面包含了关于机...
继续阅读 >
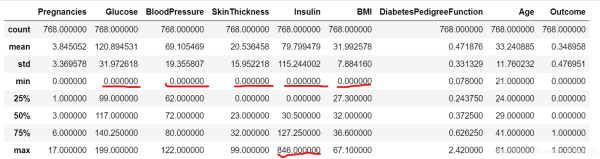 一、数据集描述本数据集内含十个属性列Pergnancies:怀孕次数Glucose:血糖浓度BloodPressure:舒张压(毫米汞柱)SkinThickness:肱三头肌皮肤褶皱厚度(毫米)Insulin:两个小时血清胰岛素(μU/毫升)BMI:身体质量指数,体重除以身高的平方DiabetsPedigreeFunction:疾病血统指数是否和遗传相关,Height:身高(厘米)Age:年龄Outcome:0表示不患病,1表示患病。任务:建立机器学习模型以准确预测数据集中的患者是否患有糖尿病二、...
一、数据集描述本数据集内含十个属性列Pergnancies:怀孕次数Glucose:血糖浓度BloodPressure:舒张压(毫米汞柱)SkinThickness:肱三头肌皮肤褶皱厚度(毫米)Insulin:两个小时血清胰岛素(μU/毫升)BMI:身体质量指数,体重除以身高的平方DiabetsPedigreeFunction:疾病血统指数是否和遗传相关,Height:身高(厘米)Age:年龄Outcome:0表示不患病,1表示患病。任务:建立机器学习模型以准确预测数据集中的患者是否患有糖尿病二、...
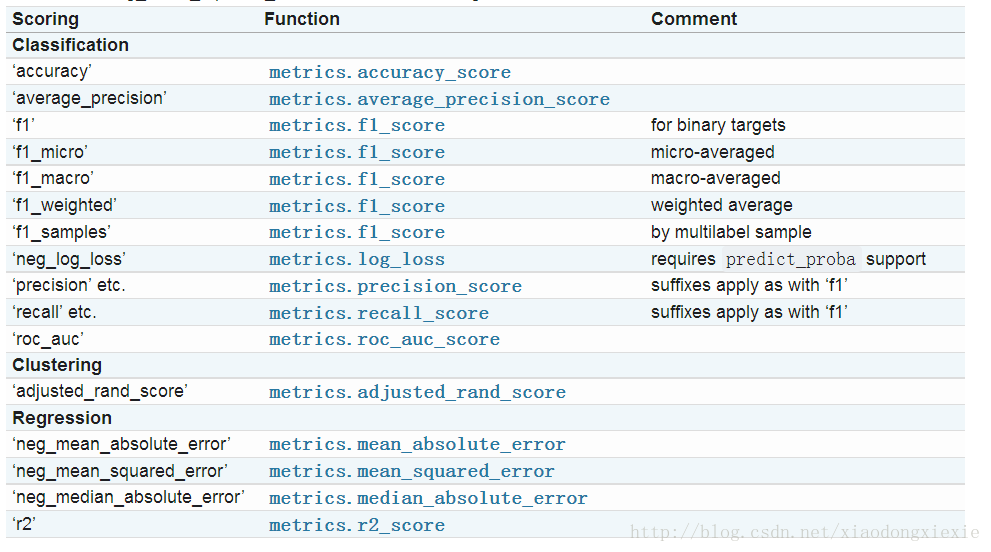 sklearn是利用python进行机器学习中一个非常全面和好用的第三方库,用过的都说好。今天主要记录一下sklearn中关于交叉验证的各种用法,主要是对sklearn官方文档Cross-validation:evaluatingestimatorperformance进行讲解,英文水平好的建议读官方文档,里面的知识点很详细。先导入需要的库及数据集In[1]:importnumpyasnpIn[2]:fromsklearn.model_selectionimporttrain_test_splitIn[3]:fromsklearn.datasetsimpo...
sklearn是利用python进行机器学习中一个非常全面和好用的第三方库,用过的都说好。今天主要记录一下sklearn中关于交叉验证的各种用法,主要是对sklearn官方文档Cross-validation:evaluatingestimatorperformance进行讲解,英文水平好的建议读官方文档,里面的知识点很详细。先导入需要的库及数据集In[1]:importnumpyasnpIn[2]:fromsklearn.model_selectionimporttrain_test_splitIn[3]:fromsklearn.datasetsimpo...
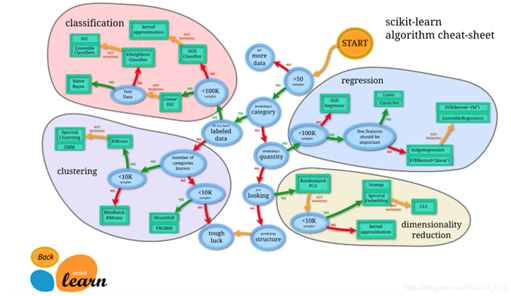 1.Sklearn简介Scikit-learn(sklearn)是机器学习中常用的第三方模块,对常用的机器学习方法进行了封装,包括回归(Regression)、降维(DimensionalityReduction)、分类(Classfication)、聚类(Clustering)等方法。当我们面临机器学习问题时,便可根据下图来选择相应的方法。Sklearn具有以下特点:简单高效的数据挖掘和数据分析工具让每个人能够在复杂环境中重复使用建立NumPy、Scipy、MatPlotLib之上2.Sklearn安装Sklearn安装要...
1.Sklearn简介Scikit-learn(sklearn)是机器学习中常用的第三方模块,对常用的机器学习方法进行了封装,包括回归(Regression)、降维(DimensionalityReduction)、分类(Classfication)、聚类(Clustering)等方法。当我们面临机器学习问题时,便可根据下图来选择相应的方法。Sklearn具有以下特点:简单高效的数据挖掘和数据分析工具让每个人能够在复杂环境中重复使用建立NumPy、Scipy、MatPlotLib之上2.Sklearn安装Sklearn安装要...
 在Python中,出现'nomodulenamedsklean'的原因是,没有正确安装sklean包。可以使用pip包管理器来安装包,pip包管理器会自动安装包所依赖bai的包而无需额外手动安装,因此十分方便。使用pip包管理器安装包的方法如下:在命令行中输入:pip install sklean如果成功安装,会提示“Successfullyinstalledsklean”。其实参考下面的方法1.安装支持部分:在terminal里面直接输入以下命令,这个命令会安装sklearn所需要的依...
在Python中,出现'nomodulenamedsklean'的原因是,没有正确安装sklean包。可以使用pip包管理器来安装包,pip包管理器会自动安装包所依赖bai的包而无需额外手动安装,因此十分方便。使用pip包管理器安装包的方法如下:在命令行中输入:pip install sklean如果成功安装,会提示“Successfullyinstalledsklean”。其实参考下面的方法1.安装支持部分:在terminal里面直接输入以下命令,这个命令会安装sklearn所需要的依...
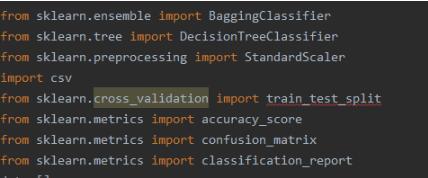 解决方法:在编程过程中,遇到很多错误,提示都是unresolvedreference,在进行先关搜素后,从stackoverflow上的相关问题得到启发,具体步骤如下:1、点击菜单栏上的File->Setting->Build,Executing,Development->Console->PythonConsole2、将AddsourcerootstoPYTHONPATH勾选上3、点击Apply4.ok5.file->清除缓存并重启补充知识:Python3.6机器学习sklearn中导入train_test_split库出错“Unresolvedreference‘train...
解决方法:在编程过程中,遇到很多错误,提示都是unresolvedreference,在进行先关搜素后,从stackoverflow上的相关问题得到启发,具体步骤如下:1、点击菜单栏上的File->Setting->Build,Executing,Development->Console->PythonConsole2、将AddsourcerootstoPYTHONPATH勾选上3、点击Apply4.ok5.file->清除缓存并重启补充知识:Python3.6机器学习sklearn中导入train_test_split库出错“Unresolvedreference‘train...
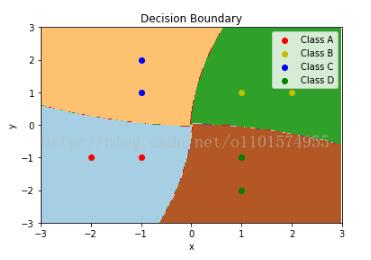 发现个很有用的方法——predict_proba今天在做数据预测的时候用到了,感觉很不错,所以记录分享一下,以后可能会经常用到。我的理解:predict_proba不同于predict,它返回的预测值为,获得所有结果的概率。(有多少个分类结果,每行就有多少个概率,以至于它对每个结果都有一个可能,如0、1就有两个概率)举例:获取数据及预测代码:fromsklearn.linear_modelimportLogisticRegressionimportnumpyasnptrain_X=np.array(np...
发现个很有用的方法——predict_proba今天在做数据预测的时候用到了,感觉很不错,所以记录分享一下,以后可能会经常用到。我的理解:predict_proba不同于predict,它返回的预测值为,获得所有结果的概率。(有多少个分类结果,每行就有多少个概率,以至于它对每个结果都有一个可能,如0、1就有两个概率)举例:获取数据及预测代码:fromsklearn.linear_modelimportLogisticRegressionimportnumpyasnptrain_X=np.array(np...
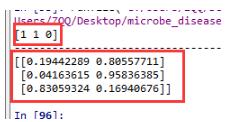 我就废话不多说了,大家还是直接看代码吧~clf=KMeans(n_clusters=5)#创建分类器对象fit_clf=clf.fit(X)#用训练器数据拟合分类器模型clf.predict(X)#也可以给新数据数据对其预测print(clf.cluster_centers_)#输出5个类的聚类中心y_pred=clf.fit_predict(X)#用训练器数据X拟合分类器模型并对训练器数据X进行预测print(y_pred)#输出预测结果补充知识:sklearn中调用某个机器学习模型model.predict(x)和model.predict_proba(x)...
我就废话不多说了,大家还是直接看代码吧~clf=KMeans(n_clusters=5)#创建分类器对象fit_clf=clf.fit(X)#用训练器数据拟合分类器模型clf.predict(X)#也可以给新数据数据对其预测print(clf.cluster_centers_)#输出5个类的聚类中心y_pred=clf.fit_predict(X)#用训练器数据X拟合分类器模型并对训练器数据X进行预测print(y_pred)#输出预测结果补充知识:sklearn中调用某个机器学习模型model.predict(x)和model.predict_proba(x)...
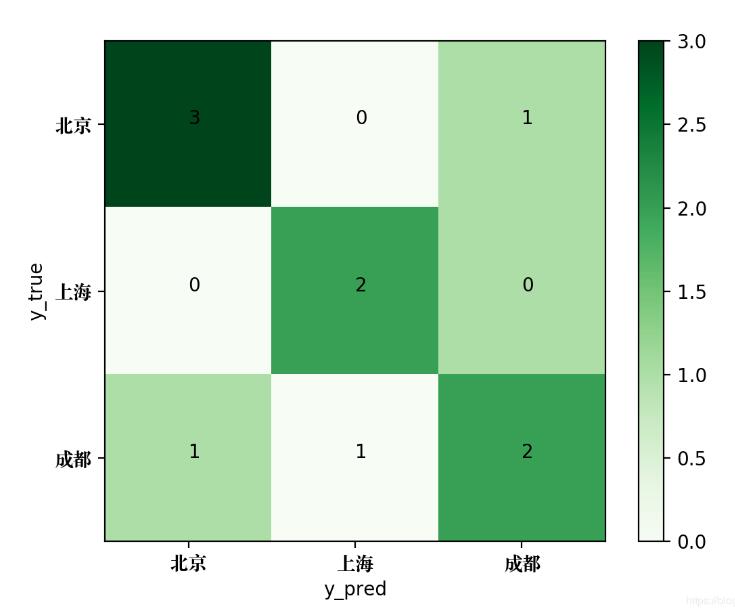 今天晚上,笔者接到客户的一个需要,那就是:对多分类结果的每个类别进行指标评价,也就是需要输出每个类型的精确率(precision),召回率(recall)以及F1值(F1-score)。对于这个需求,我们可以用sklearn来解决,方法并没有难,笔者在此仅做记录,供自己以后以及读者参考。我们模拟的数据如下:y_true=['北京','上海','成都','成都','上海','北京','上海','成都','北京','上海']y_pred=['北京','上海','成都','...
今天晚上,笔者接到客户的一个需要,那就是:对多分类结果的每个类别进行指标评价,也就是需要输出每个类型的精确率(precision),召回率(recall)以及F1值(F1-score)。对于这个需求,我们可以用sklearn来解决,方法并没有难,笔者在此仅做记录,供自己以后以及读者参考。我们模拟的数据如下:y_true=['北京','上海','成都','成都','上海','北京','上海','成都','北京','上海']y_pred=['北京','上海','成都','...
 线性逻辑回归本文用代码实现怎么利用sklearn来进行线性逻辑回归的计算,下面先来看看用到的数据。这是有两行特征的数据,然后第三行是数据的标签。python代码首先导入包和载入数据写一个画图的函数,把这些数据表示出来:然后我们调用这个函数得到下面的图像:接下来开始创建模型并拟合,然后调用sklearn里面的逻辑回归方法,里面的函数可以自动帮算出权值和偏置值,非常简单,接着画出图像。最后我们可以来看看评估值:可以看到,...
线性逻辑回归本文用代码实现怎么利用sklearn来进行线性逻辑回归的计算,下面先来看看用到的数据。这是有两行特征的数据,然后第三行是数据的标签。python代码首先导入包和载入数据写一个画图的函数,把这些数据表示出来:然后我们调用这个函数得到下面的图像:接下来开始创建模型并拟合,然后调用sklearn里面的逻辑回归方法,里面的函数可以自动帮算出权值和偏置值,非常简单,接着画出图像。最后我们可以来看看评估值:可以看到,...
 最近在看《深度学习:基于Keras的Python实践(魏贞原)》这本书,书中8.3创建了一个Scikit-Learn的Pipeline,首先标准化数据集,然后创建和评估基线神经网络模型,代码如下:#数据正态化,改进算法steps=[]steps.append(('standardize',StandardScaler()))steps.append(('mlp',model))pipeline=Pipeline(steps)kfold=KFold(n_splits=10,shuffle=True,random_state=seed)results=cross_val_score(pipeline,x,Y,cv=k...
最近在看《深度学习:基于Keras的Python实践(魏贞原)》这本书,书中8.3创建了一个Scikit-Learn的Pipeline,首先标准化数据集,然后创建和评估基线神经网络模型,代码如下:#数据正态化,改进算法steps=[]steps.append(('standardize',StandardScaler()))steps.append(('mlp',model))pipeline=Pipeline(steps)kfold=KFold(n_splits=10,shuffle=True,random_state=seed)results=cross_val_score(pipeline,x,Y,cv=k...
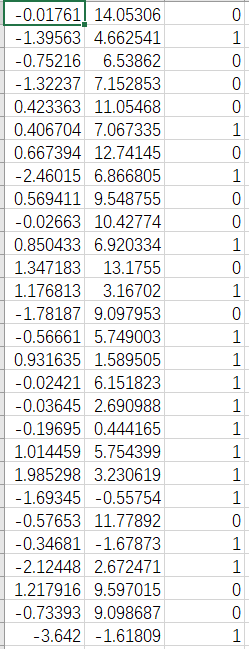
 一、导入excel文件和相关库importpandas;importmatplotlib;frompandas.tools.plottingimportscatter_matrix;data=pandas.read_csv("D:\\面积距离车站.csv",engine='python',encoding='utf-8')显示文件大小data.shapedata二.绘制多个变量两两之间的散点图:scatter_matrix()方法#绘制多个变量两两之间的散点图:scatter_matrix()方法font={'family':'SimHei'}matplotlib.rc('font',**font)scatter_matrix(data...
一、导入excel文件和相关库importpandas;importmatplotlib;frompandas.tools.plottingimportscatter_matrix;data=pandas.read_csv("D:\\面积距离车站.csv",engine='python',encoding='utf-8')显示文件大小data.shapedata二.绘制多个变量两两之间的散点图:scatter_matrix()方法#绘制多个变量两两之间的散点图:scatter_matrix()方法font={'family':'SimHei'}matplotlib.rc('font',**font)scatter_matrix(data...