
2021
08-23
08-23
Python爬虫必备之XPath解析库
目录一、简介二、安装三、节点3.1选取节点3.2选取未知节点3.3节点关系四、XPath实例一、简介XPath是一门在XML文档中查找信息的语言。XPath可用来在XML文档中对元素和属性进行遍历。XPath是W3CXSLT标准的主要元素,并且XQuery和XPointer都构建于XPath表达之上。Xpath解析库介绍:数据解析的过程中使用过正则表达式,但正则表达式想要进准匹配难度较高,一旦正则表达式书写错误,匹配的数据也会出错。网页由三部...
继续阅读 >
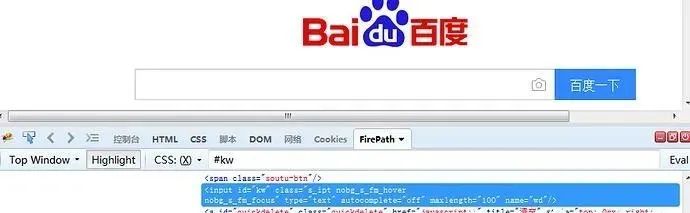 目录一、xpath:基本属性定位二、xpath:其他属性定位三、xpath:标签定位四、xpath:相对路径/绝对路径定位五、xpath:索引六、xpath:逻辑运算七、xpath:模糊匹配一、xpath:基本属性定位上一篇文章讲了通过元素的id、name、class这些属性定位的用户,使用xpath方法结合元素属性也可以很准确的定位元素,如下图 于是可以用以下xpath方法定位二、xpath:其他属性定位在实际工作过程中,往往会遇到一个元素id、name、class属性都没有...
目录一、xpath:基本属性定位二、xpath:其他属性定位三、xpath:标签定位四、xpath:相对路径/绝对路径定位五、xpath:索引六、xpath:逻辑运算七、xpath:模糊匹配一、xpath:基本属性定位上一篇文章讲了通过元素的id、name、class这些属性定位的用户,使用xpath方法结合元素属性也可以很准确的定位元素,如下图 于是可以用以下xpath方法定位二、xpath:其他属性定位在实际工作过程中,往往会遇到一个元素id、name、class属性都没有...
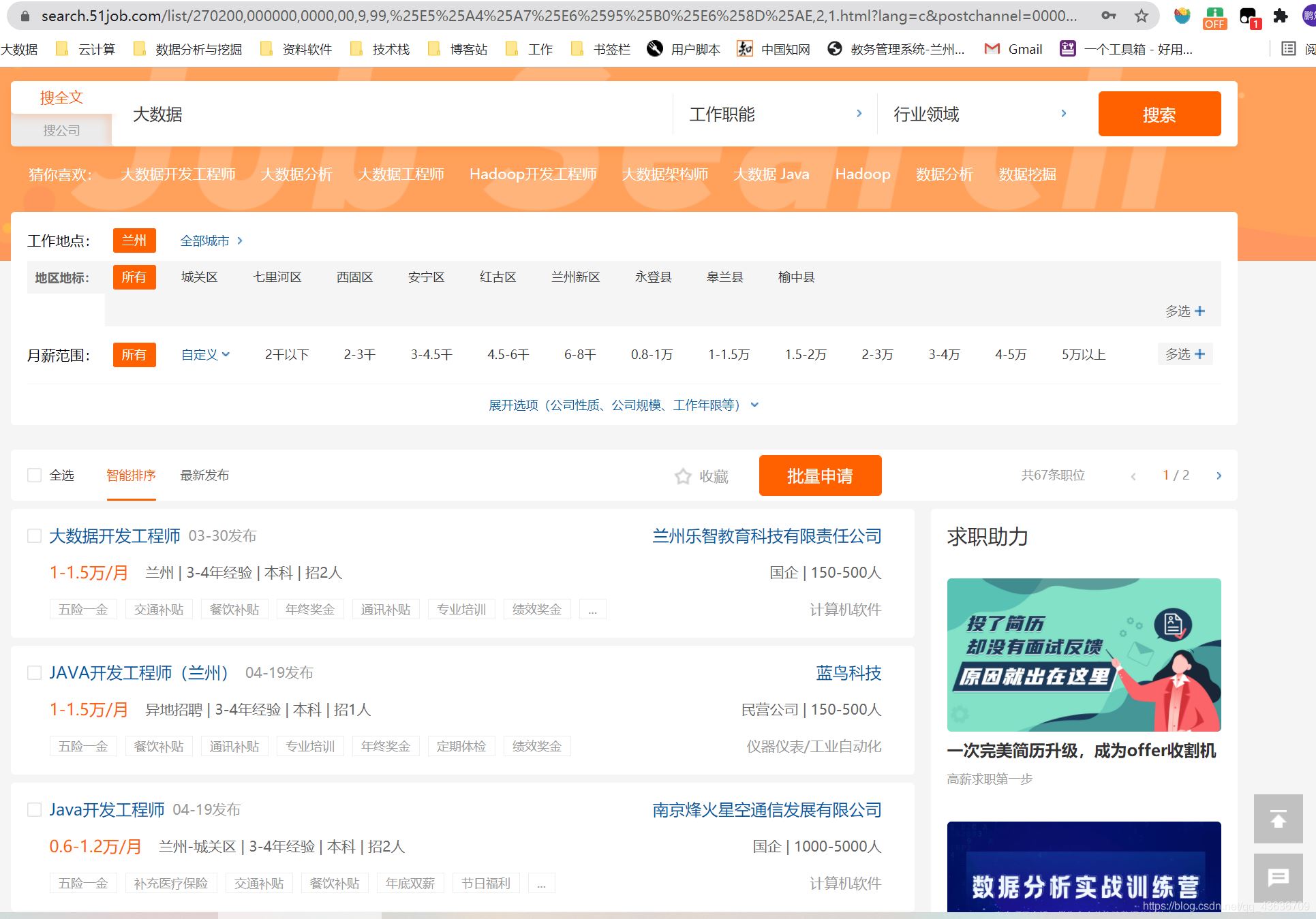 python的requests它是python的一个第三方库,处理URL比urllib这个库要方便的多,并且功能也很丰富。【可以先看4,5表格形式的说明,再看前面的】安装直接用pip安装,anconda是自带这个库的。pipinstallrequests简单使用requests的文档1.简单访问一个url:importrequestsurl='http://www.baidu.com'res=requests.get(url)res.textres.status_code<!DOCTYPEhtml><!--STATUSOK--><html><head><metahttp-equiv=content-typec...
python的requests它是python的一个第三方库,处理URL比urllib这个库要方便的多,并且功能也很丰富。【可以先看4,5表格形式的说明,再看前面的】安装直接用pip安装,anconda是自带这个库的。pipinstallrequests简单使用requests的文档1.简单访问一个url:importrequestsurl='http://www.baidu.com'res=requests.get(url)res.textres.status_code<!DOCTYPEhtml><!--STATUSOK--><html><head><metahttp-equiv=content-typec...
 小伙伴们,这次推文讲的是‘xpath‘,掌握起来不难的哦。而且,熟悉了这套路,别说pubmed,任何你能在浏览器实现的操作,都基本能通过selenium自动化进行。总代码:foriinrange(51,56):driver.implicitly_wait(10)ActionChains(driver).move_to_element(driver.find_element_by_xpath('//*[@id="save-results-panel-trigger"]')).click().perform()Select(driver.find_element_by_xpath('//*[@id="save-action-selection"...
小伙伴们,这次推文讲的是‘xpath‘,掌握起来不难的哦。而且,熟悉了这套路,别说pubmed,任何你能在浏览器实现的操作,都基本能通过selenium自动化进行。总代码:foriinrange(51,56):driver.implicitly_wait(10)ActionChains(driver).move_to_element(driver.find_element_by_xpath('//*[@id="save-results-panel-trigger"]')).click().perform()Select(driver.find_element_by_xpath('//*[@id="save-action-selection"...
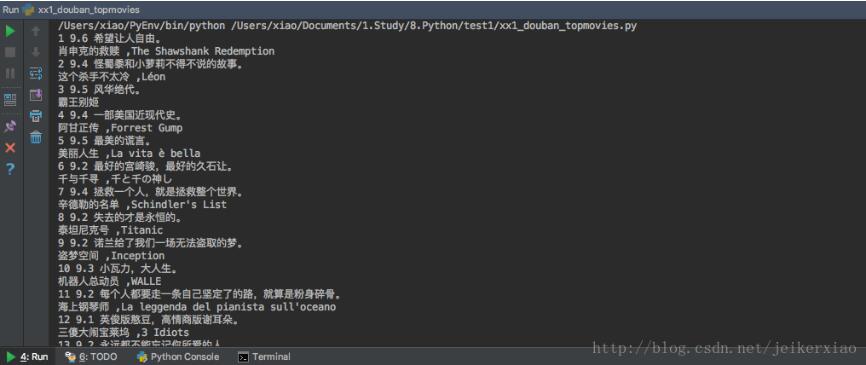 根据一个爬取豆瓣电影排名的小应用,来简单使用etree和request库。etree使用xpath语法。importrequestsimportsslfromlxmlimportetreessl._create_default_https_context=ssl._create_unverified_contextsession=requests.Session()foridinrange(0,251,25):URL='https://movie.douban.com/top250/?start='+str(id)req=session.get(URL)#设置网页编码格式req.encoding='utf8'#将request.content转...
根据一个爬取豆瓣电影排名的小应用,来简单使用etree和request库。etree使用xpath语法。importrequestsimportsslfromlxmlimportetreessl._create_default_https_context=ssl._create_unverified_contextsession=requests.Session()foridinrange(0,251,25):URL='https://movie.douban.com/top250/?start='+str(id)req=session.get(URL)#设置网页编码格式req.encoding='utf8'#将request.content转...
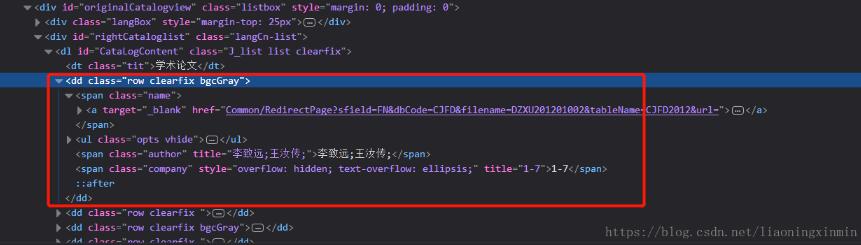 有些时候我在们需要的用正则提取出html中某一个部分的文字内容,如图:获取dd部分的html文档,我们要通过它的一个属性去确定他的位置才可以拿到他这个部分我们可以看到他的这个属性class='rowclearfix',然后用xpath去获取到这部分:name=tree.xpath("//dd[@class='rowclearfix']")fromlxmlimporthtmlimportrequestsurl='http://navi.cnki.net/knavi/JournalDetail/GetArticleList?year=2018&issue=04&pykm=DZXU&pag...
有些时候我在们需要的用正则提取出html中某一个部分的文字内容,如图:获取dd部分的html文档,我们要通过它的一个属性去确定他的位置才可以拿到他这个部分我们可以看到他的这个属性class='rowclearfix',然后用xpath去获取到这部分:name=tree.xpath("//dd[@class='rowclearfix']")fromlxmlimporthtmlimportrequestsurl='http://navi.cnki.net/knavi/JournalDetail/GetArticleList?year=2018&issue=04&pykm=DZXU&pag...