
Himmelblau函数如下:
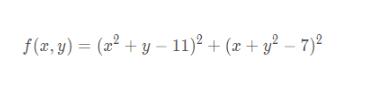
有四个全局最小解,且值都为0,这个函数常用来检验优化算法的表现如何:
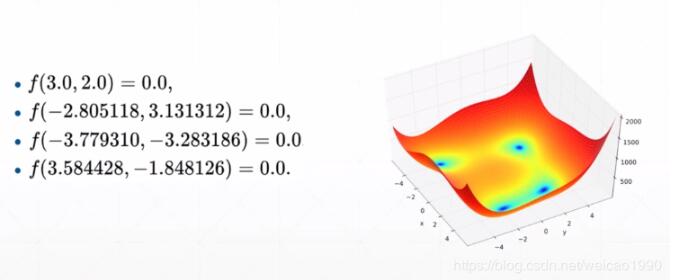
可视化函数图像:
import numpy as np
from matplotlib import pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
def himmelblau(x):
return (x[0] ** 2 + x[1] - 11) ** 2 + (x[0] + x[1] ** 2 - 7) ** 2
x = np.arange(-6, 6, 0.1)
y = np.arange(-6, 6, 0.1)
X, Y = np.meshgrid(x, y)
Z = himmelblau([X, Y])
fig = plt.figure("himmeblau")
ax = fig.gca(projection='3d')
ax.plot_surface(X, Y, Z)
ax.view_init(60, -30)
ax.set_xlabel('x')
ax.set_ylabel('y')
plt.show()
结果:
使用随机梯度下降优化:
import torch
def himmelblau(x):
return (x[0] ** 2 + x[1] - 11) ** 2 + (x[0] + x[1] ** 2 - 7) ** 2
# 初始设置为0,0.
x = torch.tensor([0., 0.], requires_grad=True)
# 优化目标是找到使himmelblau函数值最小的坐标x[0],x[1],
# 也就是x, y
# 这里是定义Adam优化器,指明优化目标是x,学习率是1e-3
optimizer = torch.optim.Adam([x], lr=1e-3)
for step in range(20000):
# 每次计算出当前的函数值
pred = himmelblau(x)
# 当网络参量进行反馈时,梯度是被积累的而不是被替换掉,这里即每次将梯度设置为0
optimizer.zero_grad()
# 生成当前所在点函数值相关的梯度信息,这里即优化目标的梯度信息
pred.backward()
# 使用梯度信息更新优化目标的值,即更新x[0]和x[1]
optimizer.step()
# 每2000次输出一下当前情况
if step % 2000 == 0:
print("step={},x={},f(x)={}".format(step, x.tolist(), pred.item()))
输出结果:
step=0,x=[0.0009999999310821295, 0.0009999999310821295],f(x)=170.0 step=2000,x=[2.3331806659698486, 1.9540692567825317],f(x)=13.730920791625977 step=4000,x=[2.9820079803466797, 2.0270984172821045],f(x)=0.014858869835734367 step=6000,x=[2.999983549118042, 2.0000221729278564],f(x)=1.1074007488787174e-08 step=8000,x=[2.9999938011169434, 2.0000083446502686],f(x)=1.5572823031106964e-09 step=10000,x=[2.999997854232788, 2.000002861022949],f(x)=1.8189894035458565e-10 step=12000,x=[2.9999992847442627, 2.0000009536743164],f(x)=1.6370904631912708e-11 step=14000,x=[2.999999761581421, 2.000000238418579],f(x)=1.8189894035458565e-12 step=16000,x=[3.0, 2.0],f(x)=0.0 step=18000,x=[3.0, 2.0],f(x)=0.0
从上面结果看,找到了一组最优解[3.0, 2.0],此时极小值为0.0。如果修改Tensor变量x的初始化值,可能会找到其它的极小值,也就是说初始化值对于找到最优解很关键。
补充拓展:pytorch 搭建自己的神经网络和各种优化器
还是直接看代码吧!
import torch
import torchvision
import torchvision.transforms as transform
import torch.utils.data as Data
import matplotlib.pyplot as plt
from torch.utils.data import Dataset,DataLoader
import pandas as pd
import numpy as np
from torch.autograd import Variable
# data set
train=pd.read_csv('Thirdtest.csv')
#cut 0 col as label
train_label=train.iloc[:,[0]] #只读取一列
#train_label=train.iloc[:,0:3]
#cut 1~16 col as data
train_data=train.iloc[:,1:]
#change to np
train_label_np=train_label.values
train_data_np=train_data.values
#change to tensor
train_label_ts=torch.from_numpy(train_label_np)
train_data_ts=torch.from_numpy(train_data_np)
train_label_ts=train_label_ts.type(torch.LongTensor)
train_data_ts=train_data_ts.type(torch.FloatTensor)
print(train_label_ts.shape)
print(type(train_label_ts))
train_dataset=Data.TensorDataset(train_data_ts,train_label_ts)
train_loader=DataLoader(dataset=train_dataset,batch_size=64,shuffle=True)
#make a network
import torch.nn.functional as F # 激励函数都在这
class Net(torch.nn.Module): # 继承 torch 的 Module
def __init__(self ):
super(Net, self).__init__() # 继承 __init__ 功能
self.hidden1 = torch.nn.Linear(16, 30)# 隐藏层线性输出
self.out = torch.nn.Linear(30, 3) # 输出层线性输出
def forward(self, x):
# 正向传播输入值, 神经网络分析出输出值
x = F.relu(self.hidden1(x)) # 激励函数(隐藏层的线性值)
x = self.out(x) # 输出值, 但是这个不是预测值, 预测值还需要再另外计算
return x
# net=Net()
# optimizer = torch.optim.SGD(net.parameters(), lr=0.0001,momentum=0.001)
# loss_func = torch.nn.CrossEntropyLoss() # the target label is NOT an one-hotted
# loss_list=[]
# for epoch in range(500):
# for step ,(b_x,b_y) in enumerate (train_loader):
# b_x,b_y=Variable(b_x),Variable(b_y)
# b_y=b_y.squeeze(1)
# output=net(b_x)
# loss=loss_func(output,b_y)
# optimizer.zero_grad()
# loss.backward()
# optimizer.step()
# if epoch%1==0:
# loss_list.append(float(loss))
# print( "Epoch: ", epoch, "Step ", step, "loss: ", float(loss))
# 为每个优化器创建一个 net
net_SGD = Net()
net_Momentum = Net()
net_RMSprop = Net()
net_Adam = Net()
nets = [net_SGD, net_Momentum, net_RMSprop, net_Adam]
#定义优化器
LR=0.0001
opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR,momentum=0.001)
opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.8)
opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.9)
opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))
optimizers = [opt_SGD, opt_Momentum, opt_RMSprop, opt_Adam]
loss_func = torch.nn.CrossEntropyLoss()
losses_his = [[], [], [], []]
for net, opt, l_his in zip(nets, optimizers, losses_his):
for epoch in range(500):
for step, (b_x, b_y) in enumerate(train_loader):
b_x, b_y = Variable(b_x), Variable(b_y)
b_y = b_y.squeeze(1)# 数据必须得是一维非one-hot向量
# 对每个优化器, 优化属于他的神经网络
output = net(b_x) # get output for every net
loss = loss_func(output, b_y) # compute loss for every net
opt.zero_grad() # clear gradients for next train
loss.backward() # backpropagation, compute gradients
opt.step() # apply gradients
if epoch%1==0:
l_his.append(loss.data.numpy()) # loss recoder
print("optimizers: ",opt,"Epoch: ",epoch,"Step ",step,"loss: ",float(loss))
labels = ['SGD', 'Momentum', 'RMSprop', 'Adam']
for i, l_his in enumerate(losses_his):
plt.plot(l_his, label=labels[i])
plt.legend(loc='best')
plt.xlabel('Steps')
plt.ylabel('Loss')
plt.xlim((0,1000))
plt.ylim((0,4))
plt.show()
#
# for epoch in range(5):
# for step ,(b_x,b_y) in enumerate (train_loader):
# b_x,b_y=Variable(b_x),Variable(b_y)
# b_y=b_y.squeeze(1)
# output=net(b_x)
# loss=loss_func(output,b_y)
# loss.backward()
# optimizer.zero_grad()
# optimizer.step()
# print(loss)
以上这篇Pytorch对Himmelblau函数的优化详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持自学编程网。

- 本文固定链接: https://zxbcw.cn/post/181633/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)