
上回书说到了对人脸的检测,这回就开始正式进入人脸识别的阶段。
关于人脸识别,目前有很多经典的算法,当我大学时代,我的老师给我推荐的第一个算法是特征脸法,原理是先将图像灰度化,然后将图像每行首尾相接拉成一个列向量,接下来为了降低运算量要用PCA降维, 最后进分类器分类,可以使用KNN、SVM、神经网络等等,甚至可以用最简单的欧氏距离来度量每个列向量之间的相似度。OpenCV中也提供了相应的EigenFaceRecognizer库来实现该算法,除此之外还有FisherFaceRecognizer、LBPHFaceRecognizer以及最近几年兴起的卷积神经网络等。
卷积神经网络(CNN)的前级包含了卷积和池化操作,可以实现图片的特征提取和降维,最近几年由于计算机算力的提升,很多人都开始转向这个方向,所以我这次打算使用它来试试效果。
老规矩,先配置下编程的环境:
- 系统:windows / linux
- 解释器:python 3.6
- 依赖库:numpy、opencv-python 3、tensorflow、keras、scikit-learn
pip3 install numpy pip3 install opencv-python pip3 install keras pip3 install scikit-learn pip3 install tensorflow
如果手中有一块支持Cuda加速的GPU建议安装GPU版本:
pip3 install tensorflow-gpu
上次文章有位读者评论说:
所以,为了照顾初学者,这里简单介绍下Anaconda的安装方法,Anaconda是一个开源的Python发行版本,其包含了Conda、Python等180多个科学包及其依赖项。因为包含了大量的科学包,Anaconda 的下载文件比较大,所以有python包安装基础的人还是建议通过pip来安装所需的依赖。
首先进入Anaconda下载页(https://www.anaconda.com/download/):
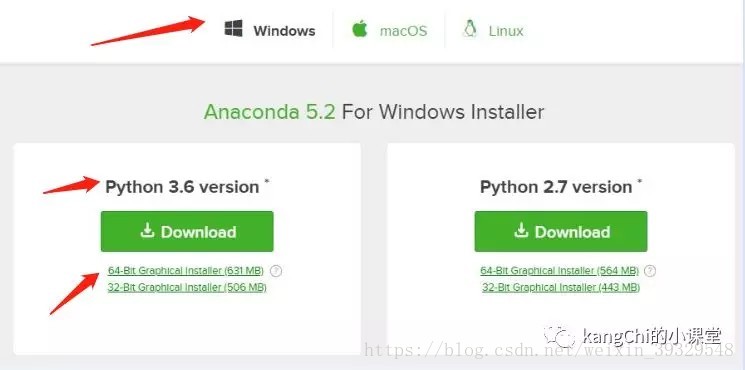
这里根据自己的电脑系统来选择相应的系统选项,至于是64位还是32位要根据自己电脑的内存大小和系统位数来选择,python版本选择3.6。
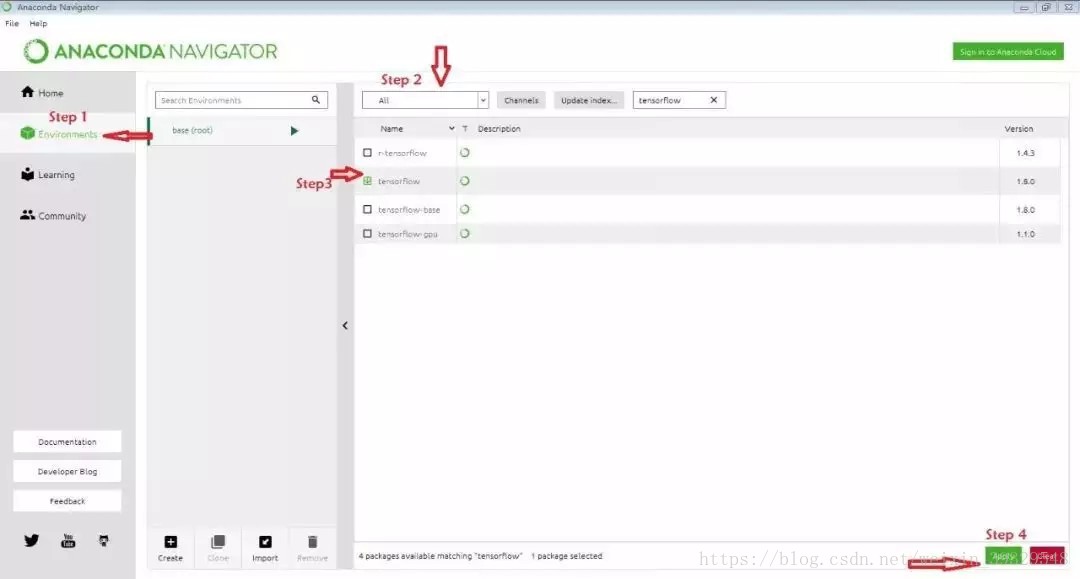
下载完成安装,打开程序,切换左侧菜单到Environment,选择all,输入想要安装的模块并搜索,选中后点击右下角的Apply就开始安装了。
基本思路:
我的设计思路是这样的,先用上节讲到的人脸检测方法来检测出人脸位置,然后根据返回的坐标、尺寸把脸用数组切片的方法截取下来,然后把截取的小图片送进训练好的卷积神经网络模型,得出人脸的分类结果,最后在原图片上打上包围框并且把结果写在包围框的上端:
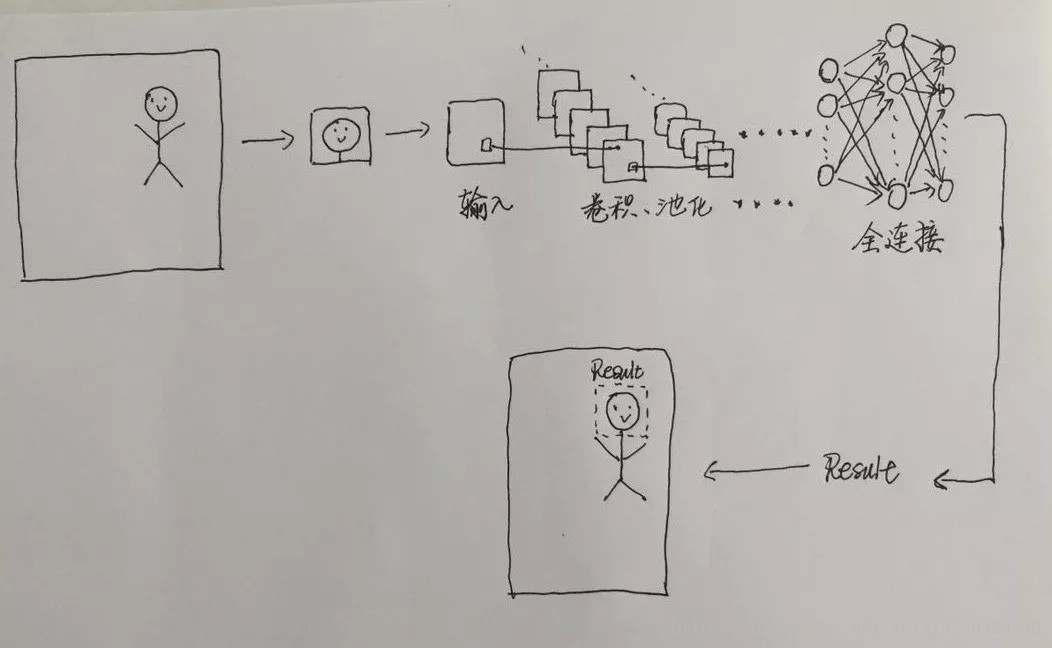
原谅我拙劣的绘画技巧
当然了,实现这一步骤的前提就是要有一个训练好的可以做人脸识别的模型,所以本文的主要内容都会放在训练上面。
深度学习框架的选择:
卷积神经网络是深度学习在图像方面的应用,所以最高效的方法就是选择合适的深度学习框架来实现它,现在市面上有很多深度学习框架可供选择, 比如基于 C++ 的 Caffe 、基于 Python 的TensorFlow、Pytorch、Theano、CNTK 以及前两天一个好友提到的她正在用来做推荐算法的 MXNET 。

这些都是搭建深度学习框架不错的选择,不过搭建的步骤会比较繁琐,会让很多初学者瞬间放弃,还好世界上出现了Keras,它可以使用TensorFlow、Theano、CNTK作为后端运算引擎,提供了高层的,更易于使用的函数,可以让不太了解深度学习原理的人也能快速上手,用通俗的话说就是:“ Keras是为人类而不是天顶星人设计的API ”。

本文所使用后端运算引擎为TensorFlow,简称 TF (掏粪)。

人脸收集:
我的目的是希望在很多人中可以识别出自己的脸,所以对这个系统的要求是:
- 不能把别人识别成我
- 要能在我出现的时候识别出我
于是我需要自己的一些图照片,来教会神经网络,这个就是我,以及一堆其他人的照片来告诉它,这些不是我,或者说这些人分别是谁。
现在需要去采集一些其他人的图片,这些数据集可以自己用相机照、或者写个爬虫脚本去网上爬,不过由于人脸识别早在几十年前就一直有前辈在研究,很多大学和研究机构都采集并公布了一些人脸数据集专门用作图像识别算法的研究和验证用,像耶鲁大学的Yale人脸库,剑桥大学的ORL人脸库以及美国国防部的FERET人脸库等,我在这里用了耶鲁大学的Yale人脸库,里面包含15个人,每人11张照片,主要包括光照条件的变化,表情的变化,接下来我会把自己的几张照片混进去,看看训练过后能不能被神经网络良好的识别。
头像提取:
提取自己照片使用的是上篇文章提到的方法:
获取文件夹下所有图片文件 -> 检测人脸位置 -> 根据人脸位置及尺寸剪裁出人脸 -> 保存。
这是我的目录结构:
代码:
# _*_ coding:utf-8 _*_ import cv2 import os CASE_PATH = "haarcascade_frontalface_default.xml" RAW_IMAGE_DIR = 'me/' DATASET_DIR = 'jm/' face_cascade = cv2.CascadeClassifier(CASE_PATH) def save_feces(img, name,x, y, width, height): image = img[y:y+height, x:x+width] cv2.imwrite(name, image) image_list = os.listdir(RAW_IMAGE_DIR) #列出文件夹下所有的目录与文件 count = 166 for image_path in image_list: image = cv2.imread(RAW_IMAGE_DIR + image_path) gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) faces = face_cascade.detectMultiScale(gray, scaleFactor=1.2, minNeighbors=5, minSize=(5, 5), ) for (x, y, width, height) in faces: save_feces(image, '%ss%d.bmp' % (DATASET_DIR, count), x, y - 30, width, height+30) count += 1
得到了还蛮不错的效果:

尺寸变换:
现在有了所有的图片,可以开始训练了,不过Yale人脸库里面所有照片都是100*100的尺寸,所以将要构建的卷积神经网络的输入就是100*100,而我新生成的图片样本形状都是不规则的,为了使它可以顺利进入卷积层,第一步就要对图片做尺寸变换,当然不能暴力的resize成100*100,否则会引起图片的变形,所以这里采用了一种数字图像处理中常用的手段,就是将较短的一侧涂黑,使它变成和目标图像相同的比例,然后再resize,这样既可以保留原图的人脸信息,又可以防止图像形变:
def resize_without_deformation(image, size = (100, 100)): height, width, _ = image.shape longest_edge = max(height, width) top, bottom, left, right = 0, 0, 0, 0 if height < longest_edge: height_diff = longest_edge - height top = int(height_diff / 2) bottom = height_diff - top elif width < longest_edge: width_diff = longest_edge - width left = int(width_diff / 2) right = width_diff - left image_with_border = cv2.copyMakeBorder(image, top , bottom, left, right, cv2.BORDER_CONSTANT, value = [0, 0, 0]) resized_image = cv2.resize(image_with_border, size) return resized_image
调用了该函数出现了下面的效果:

下面是读取照片的函数,可以传入尺寸,默认尺寸是100*100,返回了两个列表,第一个列表中每一个元素都是一张图片,第二个列表中则对应存储了图片的标签,这里用1、2、3.......来指代,因为我根本不知道这些人的名字是什么:
def read_image(size = None):
data_x, data_y = [], []
for i in range(1,177):
try:
im = cv2.imread('jm/s%s.bmp' % str(i))
#im = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY)
if size is None:
size = (100, 100)
im = resize_without_deformation(im, size)
data_x.append(np.asarray(im, dtype = np.int8))
data_y.append(str(int((i-1)/11.0)))
except IOError as e:
print(e)
except:
print('Unknown Error!')
return data_x, data_y
训练:
接下来就是最重要的一步了,训练卷积神经网络,训练的好坏会直接影响识别的准确度。
引进卷积和池化层,卷积类似于图像处理中的特征提取操作,池化则很类似于降维,常用的有最大池化和平均池化:
from keras.layers import Conv2D, MaxPooling2D
引入全连接层、Dropout、Flatten。
全连接层就是经典的神经网络全连接。
Dropout用来在训练时按一定概率随机丢弃一些神经元,以获得更高的训练速度以及防止过拟合。
Flatten用于卷积层与全连接层之间,把卷积输出的多维数据拍扁成一维数据送进全连接层(类似shape方法):
from keras.layers import Dense, Dropout, Flatten
引入SGD(梯度下降优化器)来使损失函数最小化,常用的优化器还有Adam:
from keras.optimizers import SGD
读入所有图像及标签:
IMAGE_SIZE = 100 raw_images, raw_labels = read_image(size=(IMAGE_SIZE, IMAGE_SIZE)) raw_images, raw_labels = np.asarray(raw_images, dtype = np.float32), np.asarray(raw_labels, dtype = np.int32) #把图像转换为float类型,方便归一化
神经网络需要数值进行计算,需要对字符型类别标签进行编码,最容易想到的就是把他们编码成1、2、3.......这种,但是这样也就出现了强行给它们定义了大小的问题,因为如果一个类别是2,一个是4,他们之间就会有两倍的关系,但是实际上他们之间并没有直接的倍数关系,所以这里使用one-hot编码规则,做到所有标签的平等化。on-hot编码:
from keras.utils import np_utils ont_hot_labels = np_utils.to_categorical(raw_labels)
在所有读入的图像和标签中,需要划分一部分用来训练,一部分用来测试,这里使用了sklearn中的train_test_split方法,不仅可以分割数据,还可以把数据打乱,训练集 :测试集 = 7 : 3 :
from sklearn.model_selection import train_test_split train_input, valid_input, train_output, valid_output =train_test_split(raw_images, ont_hot_labels, test_size = 0.3)
数据归一化,图像数据只需要每个像素除以255就可以:
train_input /= 255.0 valid_input /= 255.0
构建卷积神经网络的每一层:
添加卷积层,32个卷积核,每个卷积核是3 * 3,边缘不补充,卷积步长向右、向下都为1, 后端运算使用 tf , 图片输入尺寸是(100,100, 3),使用relu作为激活函数,也可以用sigmoid函数等,relu收敛速度比较快:
face_recognition_model = keras.Sequential() face_recognition_model.add(Conv2D(32, 3, 3, border_mode='valid', subsample = (1, 1), dim_ordering = 'tf', input_shape = (IMAGE_SIZE, IMAGE_SIZE, 3), activation='relu')) face_recognition_model.add(Conv2D(32, 3, 3,border_mode='valid', subsample = (1, 1), dim_ordering = 'tf', activation = 'relu'))
池化层,过滤器尺寸是2 * 2:
face_recognition_model.add(MaxPooling2D(pool_size=(2, 2)))
Dropout层:
face_recognition_model.add(Dropout(0.2))
face_recognition_model.add(Conv2D(64, 3, 3, border_mode='valid', subsample = (1, 1), dim_ordering = 'tf', activation = 'relu')) face_recognition_model.add(Conv2D(64, 3, 3, border_mode='valid', subsample = (1, 1), dim_ordering = 'tf', activation = 'relu')) face_recognition_model.add(MaxPooling2D(pool_size=(2, 2))) face_recognition_model.add(Dropout(0.2))
Flatten层,处于卷积层与Dense(全连层)之间,将图片的卷积输出压扁成一个一维向量:
face_recognition_model.add(Flatten())
全连接层, 经典的神经网络结构,512个神经元:
face_recognition_model.add(Dense(512, activation = 'relu'))
face_recognition_model.add(Dropout(0.4))
输出层,神经元数是标签种类数,使用sigmoid激活函数,输出最终结果:
face_recognition_model.add(Dense(len(ont_hot_labels[0]), activation = 'sigmoid'))
有点不放心,把神经网络结构打印出来看一下:
face_recognition_model.summary()
看起来没什么问题。
使用SGD作为反向传播的优化器,来使损失函数最小化,学习率(learning_rate)是0.01,学习率衰减因子(decay)用来随着迭代次数不断减小学习率,防止出现震荡。引入冲量(momentum),不仅可以在学习率较小的时候加速学习,又可以在学习率较大的时候减速,使用nesterov:
learning_rate = 0.01 decay = 1e-6 momentum = 0.8 nesterov = True sgd_optimizer = SGD(lr = learning_rate, decay = decay, momentum = momentum, nesterov = nesterov)
编译模型,损失函数使用交叉熵,交叉熵函数随着输出和期望的差距越来越大,输出曲线会越来越陡峭,对权值的惩罚力度也会增大,如果其他的损失函数,如均方差可以可以的,各有优劣:
face_recognition_model.compile(loss = 'categorical_crossentropy', optimizer = sgd_optimizer, metrics = ['accuracy'])
开始训练,训练100次(epochs),每次训练分几个批次,每批(batch_size)20个,shuffle用来打乱样本顺序:
batch_size = 20 #每批训练数据量的大小 epochs = 100 face_recognition_model.fit(train_input, train_output, epochs = epochs, batch_size = batch_size, shuffle = True, validation_data = (valid_input, valid_output))
现在离开座位,找一个西瓜,慢慢吃,一定要慢,因为训练的时间着实太长,配上薯片会更好。
训练完成后在测试集上评估结果并保存模型供以后加载使用:
print(face_recognition_model.evaluate(valid_input, valid_output, verbose=0)) MODEL_PATH = 'face_model.h5' face_recognition_model.save(MODEL_PATH)
识别:
要开始写在识别时正式运行的程序了:
import cv2 import numpy as np import keras from keras.models import load_model
加载级联分类器模型:
CASE_PATH = "haarcascade_frontalface_default.xml" face_cascade = cv2.CascadeClassifier(CASE_PATH)
加载卷积神经网络模型:
face_recognition_model = keras.Sequential() MODEL_PATH = 'face_model.h5' face_recognition_model = load_model(MODEL_PATH)
打开摄像头,获取图片并灰度化:
cap = cv2.VideoCapture(0) ret, image = cap.read() gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
人脸检测:
faces = faceCascade.detectMultiScale(gray, scaleFactor=1.2,
minNeighbors=5, minSize=(30, 30),)
根据检测到的坐标及尺寸裁剪、无形变resize、并送入模型运算,得到结果后在人脸上打上矩形框并在矩形框上方写上识别结果:
for (x, y, width, height) in faces:
img = image[y:y+height, x:x+width]
img = resize_without_deformation(img)
img = img.reshape((1, 100, 100, 3))
img = np.asarray(img, dtype = np.float32)
img /= 255.0
result = face_recognition_model.predict_classes(img)
cv2.rectangle(image, (x, y), (x + width, y + height), (0, 255, 0), 2)
font = cv2.FONT_HERSHEY_SIMPLEX
if result[0] == 15:
cv2.putText(image, 'kangChi', (x, y-2), font, 0.7, (0, 255, 0), 2)
else:
cv2.putText(image, 'No.%d' % result[0], (x, y-2), font, 0.7, (0, 255, 0), 2)
cv2.imshow('', image)
cv2.waitKey(0)
看效果:
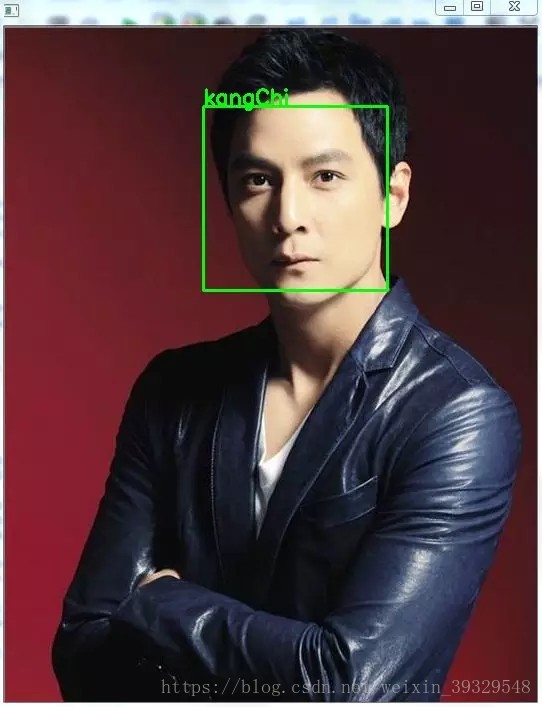
当然了,识别的效果还是取决于训练好的模型的质量,我差不多用了吃2/3个西瓜的时间来训练,还是有一些误识别的情况出现:

总结了下这次的人脸识别系统,感觉人脸检测效果还需要改进,识别准确度也有待提升,之后要多收集各个角度的照片样本和改进网络参数。
到此这篇关于使用卷积神经网络(CNN)做人脸识别的示例代码的文章就介绍到这了,更多相关卷积神经网络CNN 人脸识别内容请搜索自学编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持自学编程网

- 本文固定链接: https://zxbcw.cn/post/183656/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)