
一直记不住在jupyter notebook配置多环境编译器技巧,今总结于此,也希望对其他小伙伴有所帮助,如果有用请点赞!
1.对windows用户,win+R,输入cmd进去进入命令行,激活环境:
2.首先,确定自己是否安装包‘ipykernel',若是没有安装,则进行安装;已安装进行下一步。
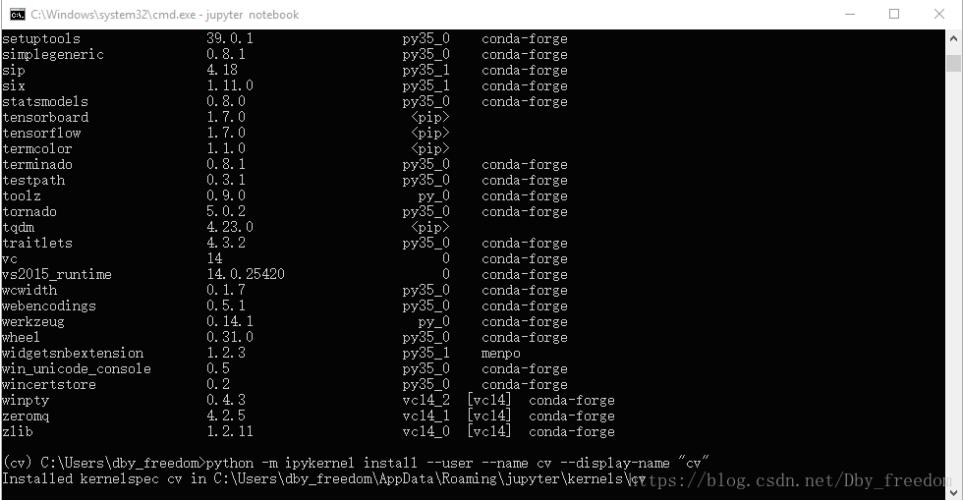
3.然后输入命令:
python -m ipykernel install --user --name deeplearningproject --display-name "deeplearningproject"
注:上述两个 deeplearningproject,前者是自身环境名称,不能变化;后者是在jupyter notebook的显示名称,可修改。
4.至此,完成所有操作,输入jupyter notebook进行验证
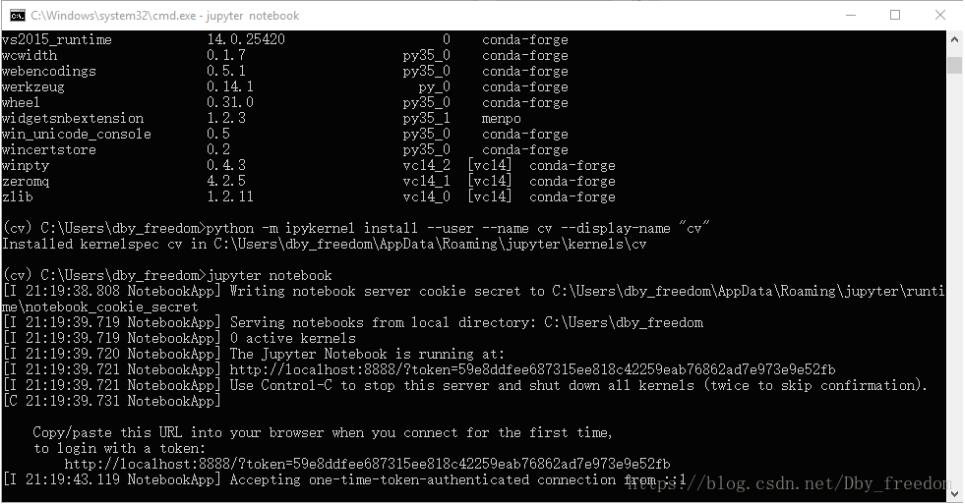
5.大功告成
至此,完成所有操作。
补充知识:Python Jupyter notebook 运行 multiprocessing 跑不了的问题
最近工作中为了解决python支持多核cpu,遇到一个Jupyter notebook跑不了multiprocessing的问题。
网上找了些multiprocessing的例子,Pycharm可以跑,但是在Jupyter notebook上跑了就只有In[*],error log:
AttributeError: Can't get attribute 'task' on <module '__main__' <built-in>>
最后找到一个解决方案:把方法写到临时文件里,再读出来。
from multiprocessing import Pool
from functools import partial
import inspect
def parallal_task(func, iterable, *params):
with open(f'./tmp_func.py', 'w') as file:
file.write(inspect.getsource(func).replace(func.__name__, "task"))
from tmp_func import task
if __name__ == '__main__':
func = partial(task, params)
pool = Pool(processes=8)
res = pool.map(func, iterable)
pool.close()
return res
else:
raise "Not in Jupyter Notebook"
def long_running_task(params, id): # Heavy job here return params, id data_list = range(8) for res in parallal_task(long_running_task, data_list, "a", 1, "b"): print(res)
以上这篇jupyter notebook 多环境conda kernel配置方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持自学编程网。

- 本文固定链接: https://zxbcw.cn/post/184453/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)