
1.作用
- dataset.shuffle作用是将数据进行打乱操作,传入参数为buffer_size,改参数为设置“打乱缓存区大小”,也就是说程序会维持一个buffer_size大小的缓存,每次都会随机在这个缓存区抽取一定数量的数据
- dataset.batch作用是将数据打包成batch_size
- dataset.repeat作用就是将数据重复使用多少epoch
2.各种不同顺序的区别
示例代码(以下面代码作为说明):
# -*- coding: utf-8 -*- import tensorflow as tf import numpy as np dataset = tf.data.Dataset.from_tensor_slices(np.arange(20).reshape((4, 5))) dataset = dataset.shuffle(100) dataset = dataset.batch(3) dataset = dataset.repeat(2) sess = tf.Session() iterator = dataset.make_one_shot_iterator() input_x = iterator.get_next() print(sess.run(input_x)) print(sess.run(input_x)) print(sess.run(input_x)) print(sess.run(input_x))
1.顺序1(训练过程最常用的顺序)
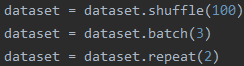
先看结果:
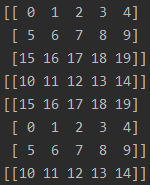
解释:相当于把所有数据先打乱,然后打包成batch输出,整体数据重复2个epoch
特点:1.一个batch中的数据不会重复;2.每个epoch的最后一个batch的尺寸小于等于batch_size
2.顺序2
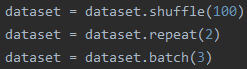
先看结果:

解释:相当于把所有数据先打乱,再把所有数据重复两个epoch,然后将重复两个epoch的数据放在一起,最后打包成batch_size输出
特点:1.因为把数据复制两份,还进行打乱,因此某个batch数据可能会重复,而且出现重复数据的batch只会是两个batch交叉的位置;2.最后一个batch的尺寸小于等于batch_size
3.顺序3

先看结果:

解释:相当于把所有数据先打包成batch,然后把打包成batch的数据重复两遍,最后再将所有batch打乱进行输出
特点:1.打乱的是batch;2.某些batch的尺寸小于等于batch_size,因为是对batch进行打乱,所以这些batch不一定是最后一个
3.其他组合方式
根据上面几种顺序,大家可以自己分析其他顺序的输出结果
到此这篇关于tensorflow dataset.shuffle、dataset.batch、dataset.repeat顺序区别详解的文章就介绍到这了,更多相关tensorflow dataset.shuffle、dataset.batch、dataset.repeat内容请搜索自学编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持自学编程网!

- 本文固定链接: https://zxbcw.cn/post/187944/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)