
MFCC
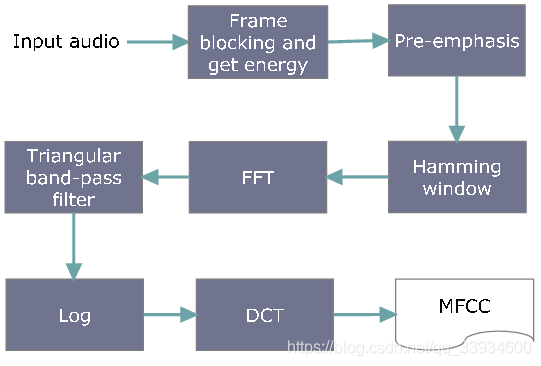
梅尔倒谱系数(Mel-scaleFrequency Cepstral Coefficients,简称MFCC)。
MFCC通常有以下之过程:
- 将一段语音信号分解为多个讯框。
- 将语音信号预强化,通过一个高通滤波器。
- 进行傅立叶变换,将信号变换至频域。
- 将每个讯框获得的频谱通过梅尔滤波器(三角重叠窗口),得到梅尔刻度。
- 在每个梅尔刻度上提取对数能量。
- 对上面获得的结果进行离散傅里叶反变换,变换到倒频谱域。
- MFCC就是这个倒频谱图的幅度(amplitudes)。一般使用12个系数,与讯框能量叠加得13维的系数。
数据集
数据集来自Eating Sound Collection,数据集中包含20种不同食物的咀嚼声音,赛题任务是给这些声音数据建模,准确分类。
类别包括: aloe, ice-cream, ribs, chocolate, cabbage, candied_fruits, soup, jelly, grapes, pizza, gummies, salmon, wings, burger, pickles, carrots, fries, chips, noodles, drinks
训练集的大小: 750
测试集的大小: 250
1 下载和解压数据集
!wget http://tianchi-competition.oss-cn-hangzhou.aliyuncs.com/531887/train_sample.zip !unzip -qq train_sample.zip !\rm train_sample.zip !wget http://tianchi-competition.oss-cn-hangzhou.aliyuncs.com/531887/test_a.zip !unzip -qq test_a.zip !\rm test_a.zip
2 加载库函数
# 基本库 import pandas as pd import numpy as np from sklearn.model_selection import train_test_split #划分数据集 from sklearn.metrics import classification_report #用于显示主要分类指标的文本报告 from sklearn.model_selection import GridSearchCV #自动调参 from sklearn.preprocessing import MinMaxScaler #归一化
加载深度学习框架
# 搭建分类模型所需要的库 from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Conv2D, Flatten, Dense, MaxPool2D, Dropout from tensorflow.keras.utils import to_categorical from sklearn.ensemble import RandomForestClassifier from sklearn.svm import SVC #支持向量分类 !pip install librosa --user #加载音频处理库 # 其他库 import os import librosa #音频处理库 import librosa.display import glob
3 特征提取以及数据集的建立
建立类别标签字典
feature = []
label = []
# 建立类别标签,不同类别对应不同的数字。
label_dict = {'aloe': 0, 'burger': 1, 'cabbage': 2,'candied_fruits':3, 'carrots': 4, 'chips':5,
'chocolate': 6, 'drinks': 7, 'fries': 8, 'grapes': 9, 'gummies': 10, 'ice-cream':11,
'jelly': 12, 'noodles': 13, 'pickles': 14, 'pizza': 15, 'ribs': 16, 'salmon':17,
'soup': 18, 'wings': 19}
label_dict_inv = {v:k for k,v in label_dict.items()}
提取梅尔频谱特征
from tqdm import tqdm
def extract_features(parent_dir, sub_dirs, max_file=10, file_ext="*.wav"):
c = 0
label, feature = [], []
for sub_dir in sub_dirs:
for fn in tqdm(glob.glob(os.path.join(parent_dir, sub_dir, file_ext))[:max_file]): # 遍历数据集的所有文件
# segment_log_specgrams, segment_labels = [], []
#sound_clip,sr = librosa.load(fn)
#print(fn)
label_name = fn.split('/')[-2]
label.extend([label_dict[label_name]])
X, sample_rate = librosa.load(fn,res_type='kaiser_fast')
mels = np.mean(librosa.feature.melspectrogram(y=X,sr=sample_rate).T,axis=0) # 计算梅尔频谱(mel spectrogram),并把它作为特征
feature.extend([mels])
return [feature, label]
# 自己更改目录
parent_dir = './train_sample/'
save_dir = "./"
folds = sub_dirs = np.array(['aloe','burger','cabbage','candied_fruits',
'carrots','chips','chocolate','drinks','fries',
'grapes','gummies','ice-cream','jelly','noodles','pickles',
'pizza','ribs','salmon','soup','wings'])
# 获取特征feature以及类别的label
temp = extract_features(parent_dir,sub_dirs,max_file=100)
temp = np.array(temp)
data = temp.transpose()
获取特征和标签
# 获取特征
X = np.vstack(data[:, 0])
# 获取标签
Y = np.array(data[:, 1])
print('X的特征尺寸是:',X.shape)
print('Y的特征尺寸是:',Y.shape)
X的特征尺寸是: (1000, 128)
Y的特征尺寸是: (1000,)
独热编码
# 在Keras库中:to_categorical就是将类别向量转换为二进制(只有0和1)的矩阵类型表示 Y = to_categorical(Y) print(X.shape) print(Y.shape)
(1000, 128)
(1000, 20)
把数据集划分为训练集和测试集
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, random_state = 1, stratify=Y)
print('训练集的大小',len(X_train))
print('测试集的大小',len(X_test))
训练集的大小 750
测试集的大小 250
X_train = X_train.reshape(-1, 16, 8, 1) X_test = X_test.reshape(-1, 16, 8, 1)
4 建立模型
搭建CNN网络
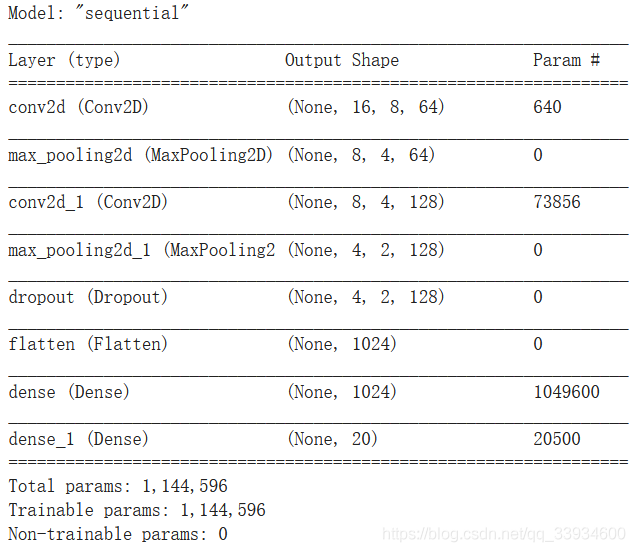
model = Sequential() # 输入的大小 input_dim = (16, 8, 1) model.add(Conv2D(64, (3, 3), padding = "same", activation = "tanh", input_shape = input_dim))# 卷积层 model.add(MaxPool2D(pool_size=(2, 2)))# 最大池化 model.add(Conv2D(128, (3, 3), padding = "same", activation = "tanh")) #卷积层 model.add(MaxPool2D(pool_size=(2, 2))) # 最大池化层 model.add(Dropout(0.1)) model.add(Flatten()) # 展开 model.add(Dense(1024, activation = "tanh")) model.add(Dense(20, activation = "softmax")) # 输出层:20个units输出20个类的概率 # 编译模型,设置损失函数,优化方法以及评价标准 model.compile(optimizer = 'adam', loss = 'categorical_crossentropy', metrics = ['accuracy']) model.summary()
训练模型
# 训练模型 model.fit(X_train, Y_train, epochs = 100, batch_size = 15, validation_data = (X_test, Y_test))
5 预测测试集
def extract_features(test_dir, file_ext="*.wav"):
feature = []
for fn in tqdm(glob.glob(os.path.join(test_dir, file_ext))[:]): # 遍历数据集的所有文件
X, sample_rate = librosa.load(fn,res_type='kaiser_fast')
mels = np.mean(librosa.feature.melspectrogram(y=X,sr=sample_rate).T,axis=0) # 计算梅尔频谱(mel spectrogram),并把它作为特征
feature.extend([mels])
return feature
X_test = extract_features('./test_a/')
X_test = np.vstack(X_test)
predictions = model.predict(X_test.reshape(-1, 16, 8, 1))
preds = np.argmax(predictions, axis = 1)
preds = [label_dict_inv[x] for x in preds]
path = glob.glob('./test_a/*.wav')
result = pd.DataFrame({'name':path, 'label': preds})
result['name'] = result['name'].apply(lambda x: x.split('/')[-1])
result.to_csv('submit.csv',index=None)
!ls ./test_a/*.wav | wc -l
!wc -l submit.csv
6 结果

到此这篇关于基础语音识别-食物语音识别baseline(CNN)的文章就介绍到这了,更多相关语音识别的内容请搜索自学编程网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持自学编程网!

- 本文固定链接: https://zxbcw.cn/post/209816/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)