
Stochastic Depth
论文:Deep Networks with Stochastic Depth
本文的正则化针对于ResNet中的残差结构,类似于dropout的原理,训练时对模块进行随机的删除,从而提升模型的泛化能力。
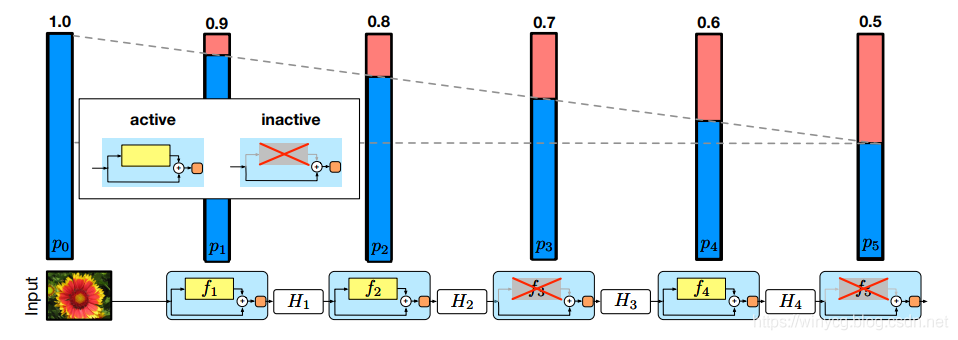
对于上述的ResNet网络,模块越在后面被drop掉的概率越大。
作者直觉上认为前期提取的低阶特征会被用于后面的层。
第一个模块保留的概率为1,之后保留概率随着深度线性递减。
对一个模块的drop函数可以采用如下的方式实现:
def drop_connect(inputs, p, training):
""" Drop connect. """
if not training: return inputs # 测试阶段
batch_size = inputs.shape[0]
keep_prob = 1 - p
random_tensor = keep_prob
random_tensor += torch.rand([batch_size, 1, 1, 1], dtype=inputs.dtype, device=inputs.device)
# 以样本为单位生成模块是否被drop的01向量
binary_tensor = torch.floor(random_tensor)
# 因为越往后越容易被drop,所以没有被drop的值就要通过除keep_prob来放大
output = inputs / keep_prob * binary_tensor
return output
在Pytorch建立的Module类中,具有forward函数
可以在forward函数中进行drop:
def forward(self, x):
x=...
if stride == 1 and in_planes == out_planes:
if drop_connect_rate:
x = drop_connect(x, p=drop_connect_rate, training=self.training)
x = x + inputs # skip connection
return x
主函数:
for idx, block in enumerate(self._blocks):
drop_connect_rate = self._global_params.drop_connect_rate
if drop_connect_rate:
drop_connect_rate *= float(idx) / len(self._blocks)
x = block(x, drop_connect_rate=drop_connect_rate)
补充:pytorch中的L2正则化实现方法
搭建神经网络时需要使用L2正则化等操作来防止过拟合,而pytorch不像TensorFlow能在任意卷积函数中添加L2正则化的超参,那怎么在pytorch中实现L2正则化呢?
方法如下:超级简单!
optimizer = torch.optim.Adam(net.parameters(), lr=0.001, weight_decay=5.0)
torch.optim.Adam()参数中的 weight_decay=5.0 即为L2正则化(只是pytorch换了名字),其数值即为L2正则化的惩罚系数,一般设置为1、5、10(根据需要设置,默认为0,不使用L2正则化)。
注:
pytorch中的优化函数L2正则化默认对所有网络参数进行惩罚,且只能实现L2正则化,如需只惩罚指定网络层参数或采用L1正则化,只能自己定义。。。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持自学编程网。

- 本文固定链接: https://zxbcw.cn/post/213414/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)