
一、环境准备
在开始学习前,需要准备好相应的环境配置。这里我选择了anaconda,创建了一个专门的虚拟环境来学习机器学习。这里关于anaconda的安装等就不赘述了,没有难度。
二、决策树是什么
通俗的说,有督促学习方法就是需要一个标签,即在知道答案的基础上进行模型训练。决策树就是从数据中读取出特定的特征,根据这些特征总结出决策规,然后使用树结构来呈现。
三、快速入门分类树
得益于强大的sklearn库,让我们使用决策树的算法十分简单:
在这里,我们引入红酒数据集,这是一个很小的数据集。
from sklearn import tree from sklearn.datasets import load_wine from sklearn.model_selection import train_test_split wine = load_wine()
然后我们就可以看看数据集长啥样了:
wine.data.shape
(178, 13)
wine.target
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2])
但这么看似乎不是很直观。我们使用pandas转换成表格格式:
import pandas as pd pd.concat([pd.DataFrame(wine.data),pd.DataFrame(wine.target)],axis=1)

可以看到,这个数据集只有178行,14列。数据量还是很小的。最后一列是我们的标签,每个数字对应一个具体的分类。
wine.feature_names ['alcohol', 'malic_acid', 'ash', 'alcalinity_of_ash', 'magnesium', 'total_phenols', 'flavanoids', 'nonflavanoid_phenols', 'proanthocyanins', 'color_intensity', 'hue', 'od280/od315_of_diluted_wines', 'proline']
可以看到,每个列对应一个特征,如0号列对应的就是alcohol,即酒精含量。其他的以此类推。
在看完数据集后,我们直接上手训练模型呗!
x_train,x_test,y_train,y_test = train_test_split(wine.data,wine.target,test_size=0.3) clf = tree.DecisionTreeClassifier(criterion="entropy") clf = clf.fit(x_train,y_train) score = clf.score(x_test,y_test) # 返回预测的准确度accuracy
先分测试集,即第一行代码。然后我们调用函数,使用fit来训练,score来打分。运行这段代码,我们看看得了多少分:

百分之九十的准确率,还是十分高的。
但这么看,似乎不是很直观啊。我们可以把这棵树画出来:
feature_name = ['酒精','苹果酸','灰','灰的碱性','镁','总酚','类黄酮','非黄烷类酚类','花青素','颜色强度','色调','od280/od315稀释葡萄酒','脯氨酸']
import graphviz
# filled 颜色 rounded 圆角
dot_data = tree.export_graphviz(clf
,feature_names=feature_name
,class_names=["琴酒","雪莉","贝尔摩德"]
,filled=True
,rounded=True
)
graph = graphviz.Source(dot_data)
graph
这里我们引入了graphviz包,画出了我们刚才的决策树:
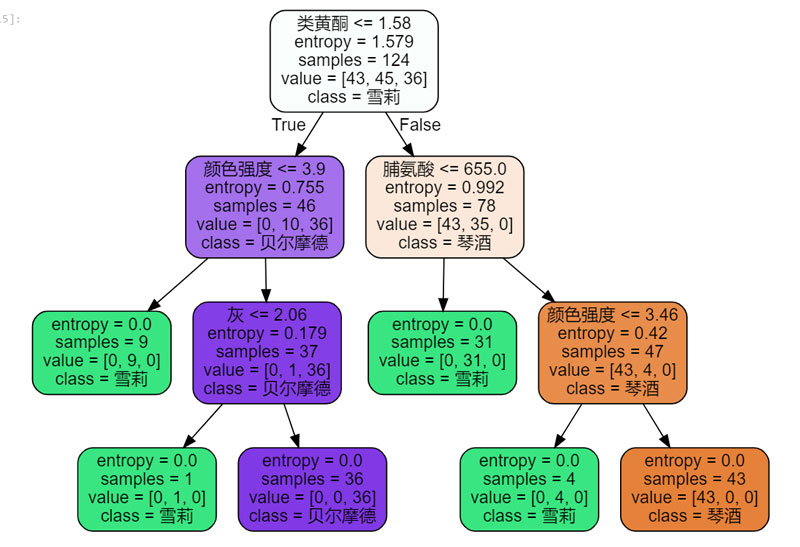
这里的class是随便写的,你也可以写别的。
四、详细分析入门案例
可以看到,我们这棵树中并没有使用所有的特征,可能只使用了四五个的样子。我们可以使用一个函数来看看每个特征的百分比:
clf.feature_importances_
array([0. , 0. , 0.03388406, 0. , 0. ,
0. , 0.42702463, 0. , 0. , 0.24446215,
0. , 0. , 0.29462916])
可以看到,我们只用了4个特征,得出了一颗树。这么看似乎不是很直观,我们用zip函数和对应的特征联一下:
[*zip(feature_name,clf.feature_importances_)]
[('酒精', 0.0),
('苹果酸', 0.0),
('灰', 0.03388405728736582),
('灰的碱性', 0.0),
('镁', 0.0),
('总酚', 0.0),
('类黄酮', 0.42702463433869187),
('非黄烷类酚类', 0.0),
('花青素', 0.0),
('颜色强度', 0.24446214572197708),
('色调', 0.0),
('od280/od315稀释葡萄酒', 0.0),
('脯氨酸', 0.29462916265196526)]
这样我们就会发现,占比最大的就构成了决策树的根节点,然后以此类推。
五、分类树参数解释
5.1、criterion
为了要将表格转化为一棵树,决策树需要找出最佳节点和最佳的分枝方法,对分类树来说,衡量这个“最佳”的指标叫做“不纯度”。通常来说,不纯度越低,决策树对训练集的拟合越好。现在使用的决策树算法在分枝方法上的核心大多是围绕在对某个不纯度相关指标的最优化上。
暂且不去理解所谓不纯度的概念,这个参数我们有两种取值:entropy与gini。那么这两种算法有什么区别呢?
比起基尼系数,信息熵对不纯度更加敏感,对不纯度的惩罚最强。但是在实际使用中,信息熵和基尼系数的效果基本相同。信息熵的计算比基尼系数缓慢一些,因为基尼系数的计算不涉及对数。另外,因为信息熵对不纯度更加敏感,所以信息熵作为指标时,决策树的生长会更加“精细”,因此对于高维数据或者噪音过多的数据,信息熵很容易过拟合,基尼系数在这种情况下效果往往比较好。当模型拟合程度不足的时候,即当模型在训练集和测试集上都表现不太好的时候,使用信息熵。当然,这些不是绝对的。
简单来说,我们在调参时可以两个都试试,默认是gini。因为这两个算法其实并没有绝对说用哪个。
5.2、random_state & splitter
random_state用来设置分枝中的随机模式的参数,默认None,在高维度时随机性会表现更明显,低维度的数据(比如鸢尾花数据集),随机性几乎不会显现。输入任意整数,会一直长出同一棵树,让模型稳定下来。
splitter也是用来控制决策树中的随机选项的,有两种输入值,输入”best",决策树在分枝时虽然随机,但是还是会优先选择更重要的特征进行分枝(重要性可以通过属性feature_importances_查看),输入“random",决策树在分枝时会更加随机,树会因为含有更多的不必要信息而更深更大,并因这些不必要信息而降低对训练集的拟合。这也是防止过拟合的一种方式。
这两个参数可以让树的模型稳定,并且更好的使用模型。
clf = tree.DecisionTreeClassifier(criterion="entropy"
,random_state=0
,splitter="random"
)
clf = clf.fit(x_train, y_train)
score = clf.score(x_test, y_test)
score
比如我们添加了一些参数后,再次运行:
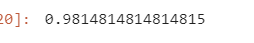
可以发现准确率飞到了98%,这说明我们参数的调整还是很有用的。
5.3、剪枝参数
在不加限制的情况下,一棵决策树会生长到衡量不纯度的指标最优,或者没有更多的特征可用为止。这样的决策树往往会过拟合,这就是说,它会在训练集上表现很好,在测试集上却表现糟糕。我们收集的样本数据不可能和整体的状况完全一致,因此当一棵决策树对训练数据有了过于优秀的解释性,它找出的规则必然包含了训练样本中的噪声,并使它对未知数据的拟合程度不足。
简单的说,我们需要对决策树进行限制,不能让他无限制的增长下去,不然只会让模型过拟合。
max_depth:
限制树的最大深度,超过设定深度的树枝全部剪掉。这是使用的最广泛的剪枝参数,实际使用建议从3开始尝试。
min_samples_leaf & min_samples_split:
min_samples_leaf限定,一个节点在分枝后的每个子节点都必须包含至少min_samples_leaf个训练样本,否则分枝就不会发生,或者,分枝会朝着满足每个子节点都包含min_samples_leaf个样本的方向去发生。
min_samples_split限定,一个节点必须要包含至少min_samples_split个训练样本,这个节点才允许被分枝,否则分枝就不会发生。
这段话看起来很绕口,我们结合代码:
clf = tree.DecisionTreeClassifier(criterion="entropy"
,random_state=30
,splitter="random"
,max_depth=4
#,min_samples_leaf=12
#,min_samples_split=10
,
)
clf = clf.fit(x_train, y_train)
dot_data = tree.export_graphviz(clf
,feature_names= feature_name
,class_names=["琴酒","雪莉","贝尔摩德"]
,filled=True
,rounded=True
)
graph = graphviz.Source(dot_data)
graph
可以自己去跑一下理解一下。
max_features & min_impurity_decrease:
max_features限制分枝时考虑的特征个数,超过限制个数的特征都会被舍弃。和max_depth异曲同工,max_features是用来限制高维度数据的过拟合的剪枝参数,但其方法比较暴力,是直接限制可以使用的特征数量而强行使决策树停下的参数,在不知道决策树中的各个特征的重要性的情况下,强行设定这个参数可能会导致模型学习不足。如果希望通过降维的方式防止过拟合,建议使用PCA,ICA或者特征选择模块中的降维算法。
但我们怎么确定一个参数是最优的呢?我们可以通过画图的方式来查看:
import matplotlib.pyplot as plt
from matplotlib.pyplot import MultipleLocator
test = []
for i in range(50):
clf = tree.DecisionTreeClassifier(max_depth=4
,criterion="entropy"
,random_state=30
,splitter="random"
,min_samples_leaf=i+5
)
clf = clf.fit(x_train, y_train)
score = clf.score(x_test, y_test)
test.append(score)
x_major_locator=MultipleLocator(2)
plt.plot(range(1,51),test,color="green",label="min_samples_leaf")
ax=plt.gca()
ax.xaxis.set_major_locator(x_major_locator)
plt.legend()
plt.show()
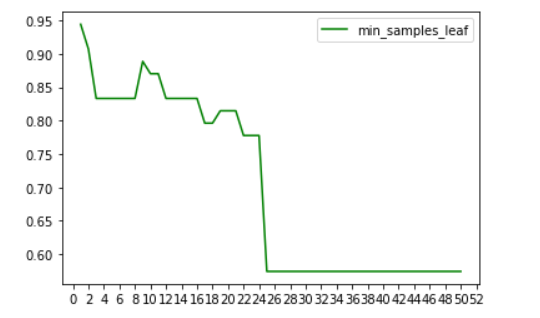
我们就可以清晰的看到了最高点出现在什么地方,进而更好的调参。
5.4、目标权重参数:class_weight & min_weight_fraction_leaf
完成样本标签平衡的参数。样本不平衡是指在一组数据集中,标签的一类天生占有很大的比例。比如说,在银行要判断“一个办了信用卡的人是否会违约”,就是是vs否(1%:99%)的比例。这种分类状况下,即便模型什么也不做,全把结果预测成“否”,正确率也能有99%。因此我们要使用class_weight参数对样本标签进行一定的均衡,给少量的标签更多的权重,让模型更偏向少数类,向捕获少数类的方向建模。该参数默认None,此模式表示自动给与数据集中的所有标签相同的权重。
有了权重之后,样本量就不再是单纯地记录数目,而是受输入的权重影响了,因此这时候剪枝,就需要搭配min_weight_fraction_leaf这个基于权重的剪枝参数来使用。另请注意,基于权重的剪枝参数(例如min_weight_fraction_leaf)将比不知道样本权重的标准(比如min_samples_leaf)更少偏向主导类。如果样本是加权的,则使用基于权重的预修剪标准来更容易优化树结构,这确保叶节点至少包含样本权重的总和的一小部分。
以上就是分析机器学习之决策树Python实现的详细内容,更多关于Python实现决策树的资料请关注自学编程网其它相关文章!

- 本文固定链接: https://zxbcw.cn/post/215098/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)