
一、前言
go的interface写起来更自由, 无需显示的实现, 只要实现了与interfece所包含的所有函数签名的相同的方法即可。让编码更灵活, 易扩展。
如何理解go语言中的interface呢?
1. interface是方法声明的集合
2.接口的方法与实现接口的类型方法格式一致
3.接口中所有方法均被实现
4. interface可以作为一种数据类型,实现了该接口的任何对象都可以给对应的接口类型变量赋值
特别说明两点:
- interface 可以被任意对象实现,一个类型/对象也可以实现多个 interface
- 方法不能重载,如
eat(), eat(s string)不能同时存在
那么作为interface数据类型,他存在的意义在哪呢? 实际上是为了满足一些面向对象的编程思想。我们知道,软件设计的最高目标就是高内聚,低耦合。那么其中有一个设计原则叫开闭原则。什么是开闭原则
二、开闭原则
在面向对象编程领域中,开闭原则规定“软件中的对象(类,模块,函数等等)应该对于扩展是开放的,但是对于修改是封闭的”,这意味着一个实体是允许在不改变它的源代码的前提下变更它的行为。
看重点: 对于扩展是开放的, 对于修改是封闭的.
举个例子: 银行每天要办理不同的业务, 存款, 转账, 取款等. 如果直接是实体来实现如下
package bank
import "fmt"
type Banker struct {
}
func (b *Banker) Save() {
fmt.Println("存钱")
}
func (b *Banker) Transfer() {
fmt.Println("转账")
}
func (b *Banker) Get() {
fmt.Println("取钱")
}
有个人要来存钱取钱转账了
package main
import "aaa/bank"
func main() {
var b = bank.Banker{}
b.Save()
b.Get()
b.Transfer()
}
那么随着业务越来越多, 越来越大. 我又要新增加一些业务, 比如基金, 股票. 然后越来越多,越来越大. 导致Banker这个模块越来越臃肿
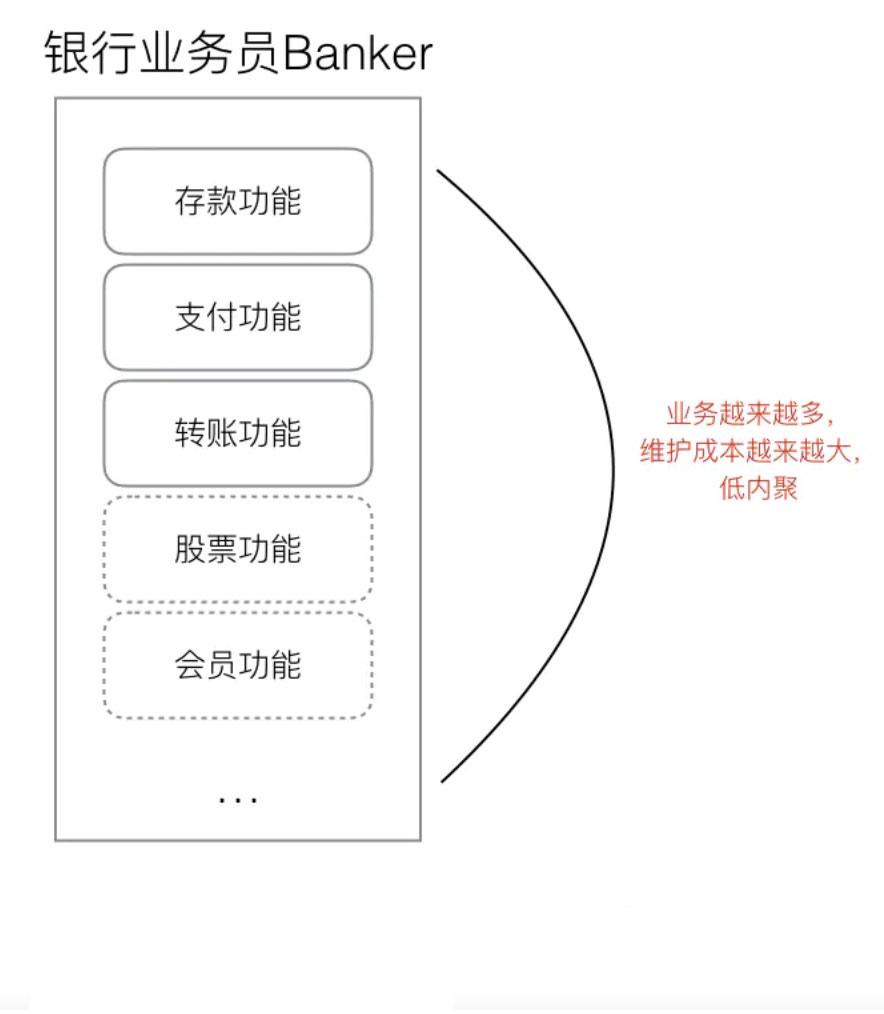
这样的设计会导致,当我们去给Banker添加新的业务的时候,会直接修改原有的Banker代码,那么Banker模块的功能会越来越多,出现问题的几率也就越来越大,假如此时Banker已经有99个业务了,现在我们要添加第100个业务,可能由于一次的不小心,导致之前99个业务也一起崩溃,因为所有的业务都在一个Banker类里,他们的耦合度太高,Banker的职责也不够单一,代码的维护成本随着业务的复杂正比成倍增大。
我们使用开闭原则, 使用interface将banker模块抽象出来. 然后根据这个抽象的模块, 去实现save, get, transfer.....
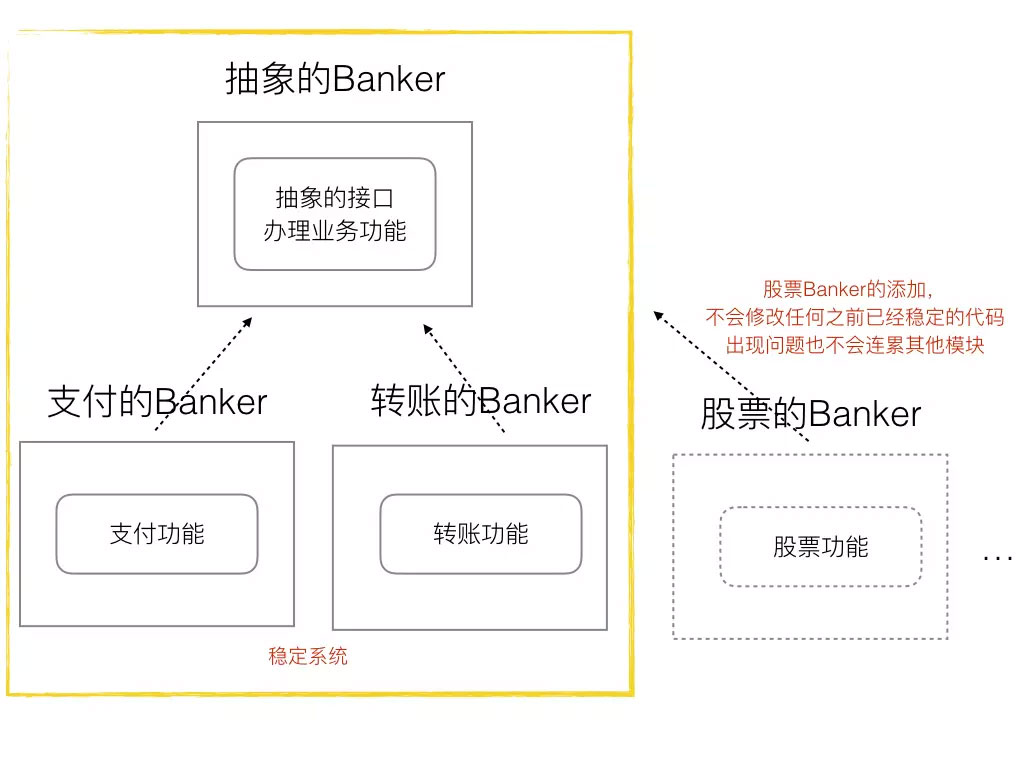
那么依然可以搞定程序的需求。 然后,当我们想要给Banker添加额外功能的时候,之前我们是直接修改Banker的内容,现在我们可以单独定义一个股票Banker(实现股票方法),到这个系统中。 而且股票Banker的实现成功或者失败都不会影响之前的稳定系统,他很单一,而且独立。
所以以上,当我们给一个系统添加一个功能的时候,不是通过修改代码,而是通过增添代码来完成,那么就是开闭原则的核心思想了。所以要想满足上面的要求,是一定需要interface来提供一层抽象的接口的。
golang代码实现如下:
package bank
import "fmt"
// 对银行的业务进行抽象
type Business interface {
doBussiness()
}
// 存钱业务
type SaveBussiness struct {
}
func (b *SaveBussiness) doBussiness() {
fmt.Sprintf("存钱")
}
//取钱业务
type GetBussiness struct {
}
func (g *GetBussiness) doBussiness() {
fmt.Println("取钱")
}
// 转账业务
type TransferBusi struct {
}
func (t *TransferBusi) doBussiness() {
fmt.Sprintf("转账")
}
然后我今天去了银行, 我们封装一个银行, 银行有各种各样的能力.
package main
import (
"aaa/bank"
"fmt"
)
// 这有一个银行, 银行可以办理业务
func Bank(b bank.Business) {
fmt.Println("办理业务: ", b.DoBussiness())
}
func main() {
// 办理具体的业务
Bank(&bank.SaveBussiness{})
Bank(&bank.GetBussiness{})
Bank(&bank.TransferBusi{})
}
这样, 当银行增加业务类型, 比如股票的时候, 只需要扩展业务接口就可以了, 不会对原来的接口进行修改
再看开闭原则定义:开闭原则:一个软件实体如类、模块和函数应该对扩展开放,对修改关闭。简单的说就是在修改需求的时候,应该尽量通过扩展来实现变化,而不是通过修改已有代码来实现变化。
接口的意义:
现在interface已经基本了解,那么接口的意义最终在哪里呢,想必现在你已经有了一个初步的认知,实际上接口的最大的意义就是实现多态的思想,就是我们可以根据interface类型来设计API接口,那么这种API接口的适应能力不仅能适应当下所实现的全部模块,也适应未来实现的模块来进行调用。 调用未来可能就是接口的最大意义所在吧,这也是为什么架构师那么值钱,因为良好的架构师是可以针对interface设计一套框架,在未来许多年却依然适用。
三、依赖倒置原则
3.1、什么是依赖倒置原则
依赖倒置原则(Dependence Inversion Principle)是程序要依赖于抽象接口,不要依赖于具体实现。简单的说就是要求对抽象进行编程,不要对实现进行编程,这样就降低了客户与实现模块间的耦合。
3.2、一个耦合度极高的模块关系设计

张三驾驶奔驰, 张三驾驶宝马, 张三驾驶丰田.
李四驾驶宝马, 李四驾驶奔驰, 李四驾驶丰田
package yldz
import "fmt"
// 奔驰车
type Benz struct {
}
func (b *Benz) run() string{
return fmt.Sprintf("奔驰启动")
}
// 宝马
type BM struct {
}
func (b *BM) run() string{
return fmt.Sprintf("宝马启动")
}
//丰田
type FT struct {
}
func (t *FT) run() string{
return fmt.Sprintf("丰田启动")
}
//====驾车人,张三
type Zhangsan struct {
}
func (t *Zhangsan) DriverBenz(b *Benz) {
fmt.Println("张三驾驶", b.run())
}
func (t *Zhangsan) DriverBM(b *BM) {
fmt.Println("张三驾驶", b.run())
}
func (t *Zhangsan) DriverFT(b *FT) {
fmt.Println("张三驾驶", b.run())
}
// 驾车人----李四.......
package main
import "aaa/yldz"
func main() {
z := yldz.Zhangsan{}
z.DriverBenz(&yldz.Benz{})
z.DriverBM(&yldz.BM{})
z.DriverFT(&yldz.FT{})
}
我们来看上面的代码和图中每个模块之间的依赖关系,实际上并没有用到任何的interface接口层的代码,显然最后我们的两个业务 张三开奔驰, 李四开宝马,程序中也都实现了。但是这种设计的问题就在于,小规模没什么问题,但是一旦程序需要扩展,比如我现在要增加一个凯迪拉克汽车 或者 司机王五, 那么模块和模块的依赖关系将成指数级递增,想蜘蛛网一样越来越难维护和捋顺。
3.3、面向抽象层依赖倒转
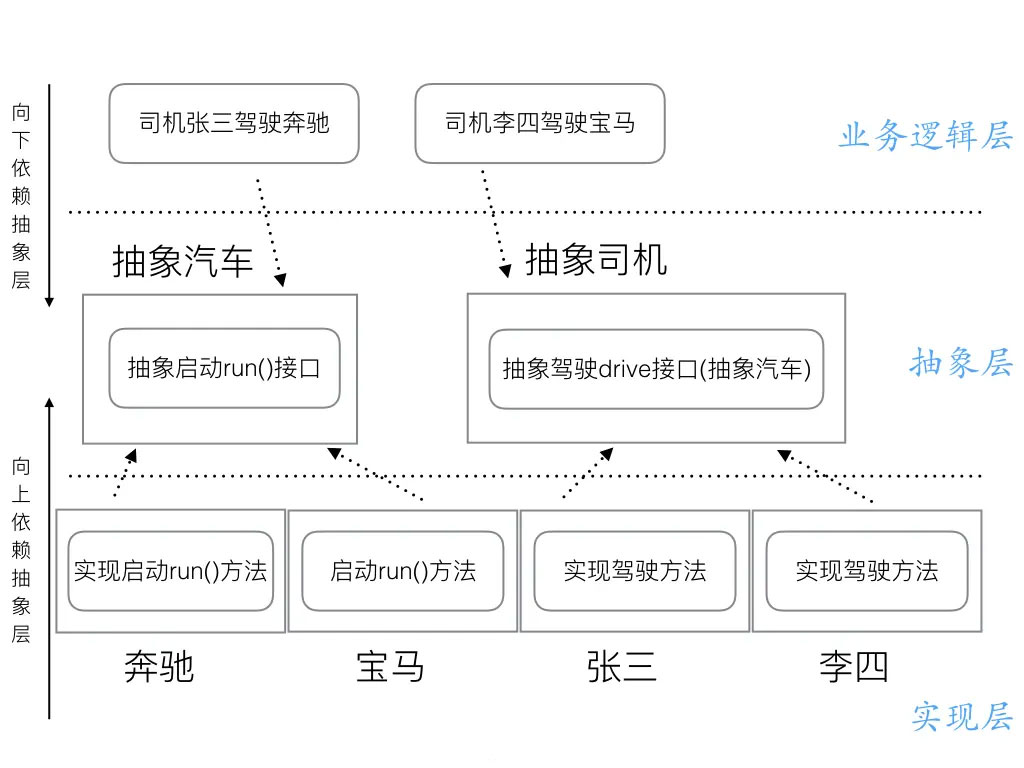
如上图所示,我们在设计一个系统的时候,将模块分为3个层次,抽象层、实现层、业务逻辑层。
- 将抽象层的模块和接口定义出来,这里就需要了
interface接口的设计, - 我们依照抽象层,依次实现每个实现层的模块,在我们写实现层代码的时候,实际上我们只需要参考对应的抽象层实现就好了,实现每个模块,也和其他的实现的模块没有关系,这样也符合了上面介绍的开闭原则。这样实现起来每个模块只依赖对象的接口,而和其他模块没关系,依赖关系单一。系统容易扩展和维护。
- 业务逻辑层也是一样,只需要参考抽象层的接口来实现业务就好了,抽象层暴露出来的接口就是我们业务层可以使用的方法,然后可以通过多态的方向,接口指针指向哪个实现模块,调用了就是具体的实现方法,这样我们业务逻辑层也是依赖抽象成编程。
看看具体的实现
package yldz
import "fmt"
type Car interface {
Run() string
}
type Driver interface {
// 接口变量肚子里有一个指针, 所以接口变量不需要使用指针.
Driver(car Car)
}
// 奔驰车
type Benz struct {
}
func (b *Benz) Run() string{
return fmt.Sprintf("奔驰启动")
}
// 宝马车
type BM struct {
}
func (b *BM) Run() string{
return fmt.Sprintf("宝马启动")
}
// 丰田车
type FT struct {
}
func (t *FT) Run() string{
return fmt.Sprintf("丰田启动")
}
// ====张三
type Zhangsan struct {
}
func (t *Zhangsan) Driver(car Car) {
fmt.Println("驾驶",car.Run())
}
func main() {
benz := yldz.Benz{}
zs := yldz.Zhangsan{}
zs.Driver(&benz)
ft := yldz.FT{}
zs.Driver(&ft)
}
以上就是分析Go语言接口的设计原则的详细内容,更多关于Go 接口的资料请关注自学编程网其它相关文章!

- 本文固定链接: https://zxbcw.cn/post/215737/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)