
面试题1:说一下抽象类和接口有哪些区别?
正经回答:
抽象类和接口的主要区别:
从设计层面来说,抽象类是对类的抽象,是一种模板设计;接口是行为的抽象,是一种行为的规范。
- 一个类可以有多个接口 只能有继承一个父类
- 抽象类可以有构造方法,接口中不能有构造方法。
- 抽象类中可以有普通成员变量,接口中没有普通成员
- 变量接口里边全部方法都必须是abstract的;抽象类的可以有实现了的方法
- 抽象类中的抽象方法的访问类型可以是public,protected;但接口中的抽象方法只能是public类型的,并且默认即为public abstract类型
- 抽象类中可以包含静态方法,接口中不能包含静态方法
- 抽象类和接口中都可以包含静态成员变量,抽象类中的静态成员变量的访问类型可以任意;但接口中定义的变量只能是public static final类型,并且默认即为public static final类型。
Java8中接口中引入默认方法和静态方法,以此来减少抽象类和接口之间的差异。
接口和抽象类各有优缺点,在接口和抽象类的选择上,必须遵守这样一个原则:
行为模型应该总是通过接口而不是抽象类定义,所以通常是优先选用接口,尽量少用抽象类。
选择抽象类的时候通常是如下情况:需要定义子类的行为,又要为子类提供通用的功能。
深入追问:
追问1:说一说你对抽象类的理解吧,他到底是干啥用的
我们常说面向对象的核心思想是:先抽象,后具体。抽象类是含有抽象方法的类,不能被实例化,抽象类常用作当做模板类使用。
接口更多的是在系统架构设计方法发挥作用,主要用于定义模块之间的通信契约。
而抽象类在代码实现方面发挥作用,可以实现代码的重用,例如,模板方法设计模式是抽象类的一个典型应用,假设某个项目的所有Servlet类都要用相同的方式进行权限判断、记录访问日志和处理异常,那么就可以定义一个抽象的基类,让所有的Servlet都继承这个抽象基类,在抽象基类的service方法中完成权限判断、记录访问日志和处理异常的代码,在各个子类中只是完成各自的业务逻辑代码。父类方法中间的某段代码不确定,再留给子类干,就用模板方法设计模式。
追问2:用抽象类实现一个接口,和普通类实现接口会有什么不同么?
一般来说我们使用普通类来实现接口,这个普通类就必须实现接口中所有的方法,这样的结果就是普通类中就需要实现多余的方法,造成代码冗余。但是如果我们使用的是抽象类来实现接口,那么就可以只实现接口中的部分方法,并且当其他类继承这个抽象类时,仍然可以实现接口中有但抽象类并未实现的方法。
如以下代码,抽象类只是实现了接口A中的方法a,方法b,但是当类C继承抽象类B时,可以直接实现接口A中的c方法,有一点需要注意的是,类C中的方法a,方法b都是调用的父类B的方法a,方法b,不是直接实现接口的方法a和b。
/**
*接口
*/
interface A{
public void aaa();
public void bbb();
public void ccc();
}
/**
*抽象类
*/
abstract class B implements A{
public void aaa(){}
public void bbb(){}
}
/**
* 实现类
*/
public class C extends B{
public void aaa(){}
public void bbb(){}
public void ccc(){}
}
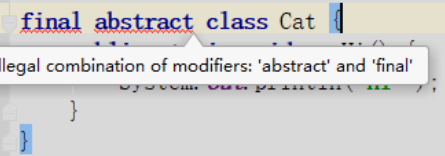
追问3:抽象类能使用 final 修饰吗?
不能,定义抽象类就是让其他类继承的,如果定义为 final 该类就不能被继承,这样彼此就会产生矛盾,所以 final 不能修饰抽象类。
面试题2:final 在 Java 中有什么作用?
正经回答:
用于修饰类、方法和属性;
1、修饰类
当用final修饰类的时,表明该类不能被其他类所继承。需要注意的是:final类中所有的成员方法都会隐式的定义为final方法。
2、修饰方法
使用final方法的原因主要是把方法锁定,以防止继承类对其进行更改或重写。
若父类中final方法的访问权限为private,将导致子类中不能直接继承该方法,因此,此时可以在子类中定义相同方法名的函数,此时不会与重写final的矛盾,而是在子类中重新地定义了新方法。
class A{
private final void getName(){
System.out.println("getName - A");
}
}
public class B extends A{
public void getName(){
System.out.println("getName - B");
}
public void main(String[]args){
this.getName(); // 日志输出:getName - B
}
}
3、修饰变量
当final修饰一个基本数据类型时,表示该基本数据类型的值一旦在初始化后便不能发生变化;如果final修饰一个引用类型时,则在对其初始化之后便不能再让其指向其他对象了,但该引用所指向的对象的内容是可以发生变化的。本质上是一回事,因为引用的值是一个地址,final要求值,即地址的值不发生变化。
final修饰一个成员变量(属性),必须要显示初始化。这里有两种初始化方式,一种是在变量声明的时候初始化;第二种方法是在声明变量的时候不赋初值,但是要在这个变量所在的类的所有的构造函数中对这个变量赋初值。
当函数的参数类型声明为final时,说明该参数是只读型的。即你可以读取使用该参数,但是无法改变该参数的值。
深入追问:
追问1:能分别说一下final、finally、finalize的区别么?
- final可以修饰类、变量、方法,修饰类表示该类不能被继承、修饰方法表示该方法不能被重写、修饰变量表示该变量是一个常量不能被重新赋值。
- finally一般作用在try-catch代码块中,在处理异常的时候,通常我们将一定要执行的代码方法finally代码块中,表示不管是否出现异常,该代码块都会执行,一般用来存放一些关闭资源的代码。当然,
还有多种情况走不了finally~ - finalize是一个方法,属于Object类的一个方法,而Object类是所有类的父类,该方法一般由垃圾回收器来调用,当我们调用System.gc() 方法的时候,由垃圾回收器调用finalize(),回收垃圾,一个对象是否可回收的最后判断。
面试题3:你对Java序列化了解么?
正经回答:
序列化过程:
是指把一个Java对象变成二进制内容,实质上就是一个byte[]数组。
因为序列化后可以把byte[]保存到文件中,或者把byte[]通过网络传输到远程(IO),这样,就相当于把Java对象存储到文件或者通过网络传输出去了。
反序列化过程:
把一个二进制内容(也就是byte[]数组)变回Java对象。有了反序列化,保存到文件中的byte[]数组又可以“变回”Java对象,或者从网络上读取byte[]并把它“变回”Java对象。
以下是一些使用序列化的示例:
以面向对象的方式将数据存储到磁盘上的文件,例如,Redis存储Student对象的列表。
将程序的状态保存在磁盘上,例如,保存游戏状态。
通过网络以表单对象形式发送数据,例如,在聊天应用程序中以对象形式发送消息。
一个Java对象要能序列化,必须实现一个特殊的java.io.Serializable接口,它的定义如下:
public interface Serializable {
}
Serializable接口没有定义任何方法,它是一个空接口。我们把这样的空接口称为“标记接口”(Marker Interface),实现了标记接口的类仅仅是给自身贴了个“标记”,并没有增加任何方法。
深入追问:
追问1:Java序列化是如何工作的?
当且仅当对象的类实现java.io.Serializable接口时,该对象才有资格进行序列化。可序列化 是一个标记接口(不包含任何方法),该接口告诉Java虚拟机(JVM)该类的对象已准备好写入持久性存储或通过网络进行读取。
默认情况下,JVM负责编写和读取可序列化对象的过程。序列化/反序列化功能通过对象流类的以下两种方法公开:
ObjectOutputStream。writeObject(Object):将可序列化的对象写入输出流。如果要序列化的某些对象未实现Serializable接口,则此方法将引发NotSerializableException。
ObjectInputStream。readObject():从输入流读取,构造并返回一个对象。如果找不到序列化对象的类,则此方法将引发ClassNotFoundException。
如果序列化使用的类有问题,则这两种方法都将引发InvalidClassException,如果发生I / O错误,则将引发IOException。无论NotSerializableException和InvalidClassException是子类IOException异常。
让我们来看一个简单的例子。以下代码将String对象序列化为名为“ data.ser”的文件。字符串对象是可序列化的,因为String类实现了Serializable 接口:
String filePath = "data.ser";
String message = "Java Serialization is Cool";
try (
FileOutputStream fos = new FileOutputStream(filePath);
ObjectOutputStream outputStream = new ObjectOutputStream(fos);
) {
outputStream.writeObject(message);
} catch (IOException ex) {
System.err.println(ex);
}
以下代码反序列化文件“ data.ser”中的String对象:
String filePath = "data.ser";
try (
FileInputStream fis = new FileInputStream(filePath);
ObjectInputStream inputStream = new ObjectInputStream(fis);
) {
String message = (String) inputStream.readObject();
System.out.println("Message: " + message);
} catch (ClassNotFoundException ex) {
System.err.println("Class not found: " + ex);
} catch (IOException ex) {
System.err.println("IO error: " + ex);
}
请注意,readObject()返回一个Object类型的对象,因此您需要将其强制转换为可序列化的类,在这种情况下为String类。
让我们看一个涉及使用自定义类的更复杂的示例。
给定以下学生班:
import java.io.*;
import java.util.*;
/**
* Student.java
* @author chenhh
*/
public class Student extends Person implements Serializable {
public static final long serialVersionUID = 1234L;
private long studentId;
private String name;
private transient int age;
public Student(long studentId, String name, int age) {
super();
this.studentId = studentId;
this.name = name;
this.age = age;
System.out.println("Constructor");
}
public String toString() {
return String.format("%d - %s - %d", studentId, name, age);
}
}
如上面代码,你会发现两点:
long serialVersionUID类型的常量。
成员变量age被标记为transient。 下面两个问题让我们搞明白它们。
追问2:什么是serialVersionUID常数
serialVersionUID是一个常数,用于唯一标识可序列化类的版本。从输入流构造对象时,JVM在反序列化过程中检查此常数。如果正在读取的对象的serialVersionUID与类中指定的序列号不同,则JVM抛出InvalidClassException。这是为了确保正在构造的对象与具有相同serialVersionUID的类兼容。
请注意,serialVersionUID是可选的。这意味着如果您不显式声明Java编译器,它将生成一个。
那么,为什么要显式声明serialVersionUID呢?
原因是:自动生成的serialVersionUID是基于类的元素(成员变量,方法,构造函数等)计算的。如果这些元素之一发生更改,serialVersionUID也将更改。想象一下这种情况:
- 您编写了一个程序,将Student类的某些对象存储到文件中。Student类没有显式声明的serialVersionUID。
- 有时,您更新了Student类(例如,添加了一个新的私有方法),现在自动生成的serialVersionUID也被更改了。
- 您的程序无法反序列化先前编写的Student对象,因为那里的serialVersionUID不同。JVM抛出InvalidClassException。
这就是为什么建议为可序列化类显式添加serialVersionUID的原因。
追问3、那你知道什么是瞬时变量么?
在上面的Student类中,您看到成员变量age被标记为transient,对吗?JVM 在序列化过程中跳过瞬态变量。这意味着在序列化对象时不会存储age变量的值。
因此,如果成员变量不需要序列化,则可以将其标记为瞬态。
以下代码将Student对象序列化为名为“ students.ser”的文件:
String filePath = "students.ser";
Student student = new Student(123, "John", 22);
try (
FileOutputStream fos = new FileOutputStream(filePath);
ObjectOutputStream outputStream = new ObjectOutputStream(fos);
) {
outputStream.writeObject(student);
} catch (IOException ex) {
System.err.println(ex);
}
请注意,在序列化对象之前,变量age的值为22。
下面的代码从文件中反序列化Student对象:
String filePath = "students.ser";
try (
FileInputStream fis = new FileInputStream(filePath);
ObjectInputStream inputStream = new ObjectInputStream(fis);
) {
Student student = (Student) inputStream.readObject();
System.out.println(student);
} catch (ClassNotFoundException ex) {
System.err.println("Class not found: " + ex);
} catch (IOException ex) {
System.err.println("IO error: " + ex);
}
此代码将输出以下输出:
1个 123 - John - 0
总结
本篇文章就到这里了,希望能给你带来帮助,也希望您能够多多关注自学编程网的更多内容!

- 本文固定链接: https://zxbcw.cn/post/217326/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)