
2021
10-29
10-29
python scrapy简单模拟登录的代码分析
1、requests模块。直接携带cookies请求页面。找到url,发送post请求存储cookie。2、selenium(浏览器自动处理cookie)。找到相应的input标签,输入文本,点击登录。3、scrapy直接带cookies。找到url,发送post请求存储cookie。#-*-coding:utf-8-*-importscrapyimportreclassGithubLoginSpider(scrapy.Spider):name='github_login'allowed_domains=['github.com']start_urls=['https://github.com/login']...
继续阅读 >
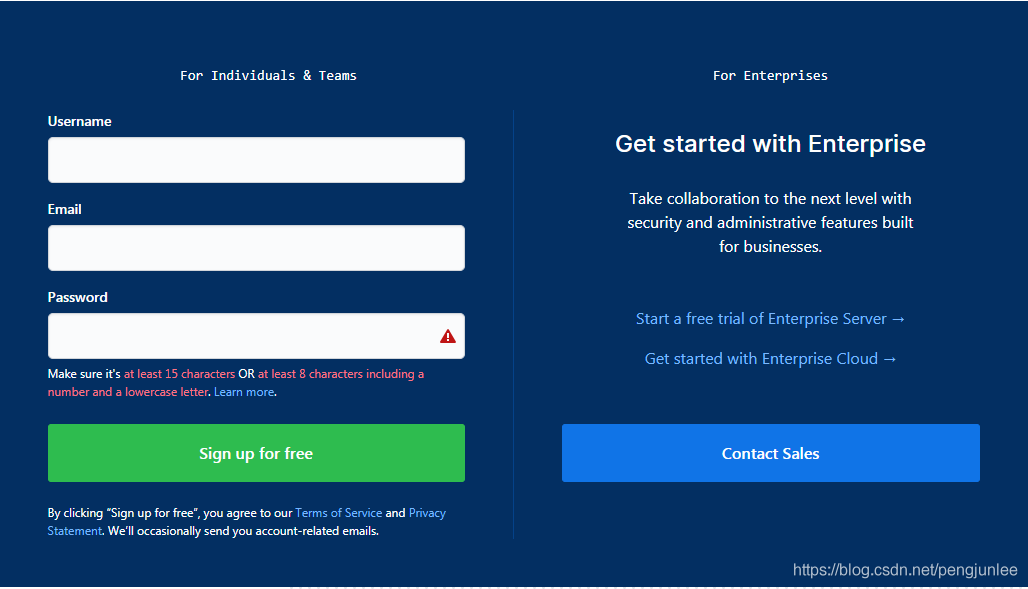 为什么要模拟登录有些网站是需要登录之后才能访问的,即便是同一个网站,在用户登录前后页面所展示的内容也可能会大不相同,例如,未登录时访问Github首页将会是以下的注册页面:然而,登录后访问Github首页将包含如下页面内容:如果我们要爬取的是一些需要登录之后才能访问的页面数据就需要模拟登录了。通常我们都是利用的Cookies来实现模拟登录,在Scrapy中,模拟登陆网站一般有如下两种实现方式: ...
为什么要模拟登录有些网站是需要登录之后才能访问的,即便是同一个网站,在用户登录前后页面所展示的内容也可能会大不相同,例如,未登录时访问Github首页将会是以下的注册页面:然而,登录后访问Github首页将包含如下页面内容:如果我们要爬取的是一些需要登录之后才能访问的页面数据就需要模拟登录了。通常我们都是利用的Cookies来实现模拟登录,在Scrapy中,模拟登陆网站一般有如下两种实现方式: ...
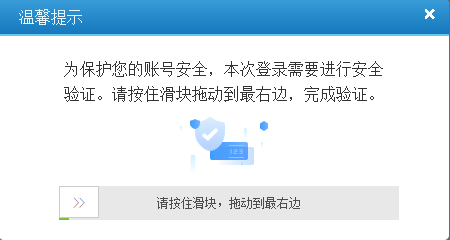 最近接触了一些selenium模块的相关知识,觉得还挺有意思的,于是决定亲自尝试写一些爬虫程序来强化selenium模块(一定要多尝试、多动手、多总结)。本文主要使用python爬虫来模拟登录铁路12306官网。这儿得吐槽一句,铁路12306网站的反爬机制做的还是比较好。话不多说,下面跟小墨一起来学习如何通过爬虫来实现铁路12306的登录。一、验证码破解当我们输入账号和密码后,在点击登录按钮之前,还需要对验证码进行操作。对验证码的识...
最近接触了一些selenium模块的相关知识,觉得还挺有意思的,于是决定亲自尝试写一些爬虫程序来强化selenium模块(一定要多尝试、多动手、多总结)。本文主要使用python爬虫来模拟登录铁路12306官网。这儿得吐槽一句,铁路12306网站的反爬机制做的还是比较好。话不多说,下面跟小墨一起来学习如何通过爬虫来实现铁路12306的登录。一、验证码破解当我们输入账号和密码后,在点击登录按钮之前,还需要对验证码进行操作。对验证码的识...
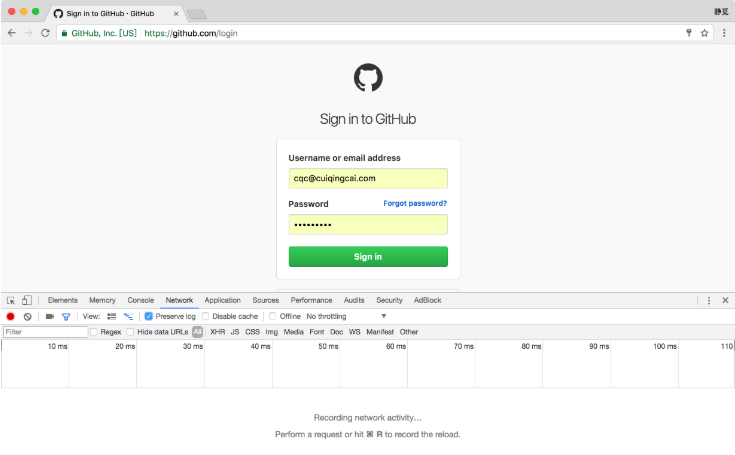 我们先以一个最简单的实例来了解模拟登录后页面的抓取过程,其原理在于模拟登录后Cookies的维护。1.本节目标本节将讲解以GitHub为例来实现模拟登录的过程,同时爬取登录后才可以访问的页面信息,如好友动态、个人信息等内容。我们应该都听说过GitHub,如果在我们在Github上关注了某些人,在登录之后就会看到他们最近的动态信息,比如他们最近收藏了哪个Repository,创建了哪个组织,推送了哪些代码。但是退出登录之后,我...
我们先以一个最简单的实例来了解模拟登录后页面的抓取过程,其原理在于模拟登录后Cookies的维护。1.本节目标本节将讲解以GitHub为例来实现模拟登录的过程,同时爬取登录后才可以访问的页面信息,如好友动态、个人信息等内容。我们应该都听说过GitHub,如果在我们在Github上关注了某些人,在登录之后就会看到他们最近的动态信息,比如他们最近收藏了哪个Repository,创建了哪个组织,推送了哪些代码。但是退出登录之后,我...