
2021
05-20
05-20
python如何读取.mtx文件
mtx文件是按照稀疏矩阵格式存储的矩阵数据,可以按照以下步骤读取:1、安装scanpy包pipinstallscanpy2、文件读取importscanpyasscadata=sc.read(filename)data=adata.X第一行read之后返回的是annData,第二行通过.X操作得到的是矩阵数据3、转换为稠密矩阵data=data.todense()直接得到的矩阵是稀疏形式的,通过todense函数可转换为稠密矩阵补充:python读取各种文件方式Json:use_time=[]withopen(address,'r')asf:...
继续阅读 >
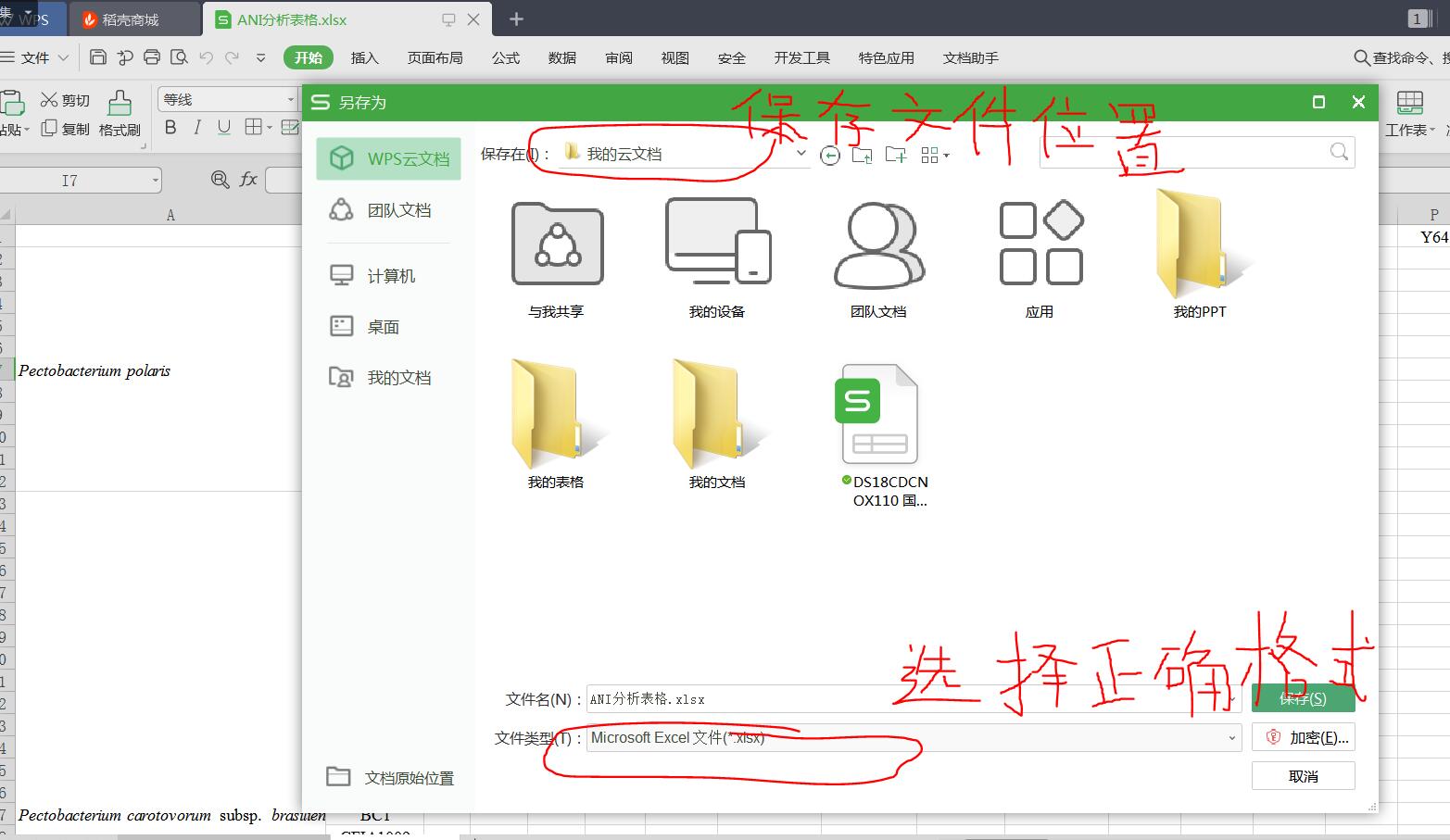 使用pandas读取xml文件报错“Unsupportedformat,orcorruptfile:ExpectedBOFrecord;foundb'<?xmlve'”解决办法:转换文件格式,使用excel打开xml文件选择:文件—>另存为---->弹框保存以后,再次用pandas读取对应格式的文件读取即可补充:在jupyter中读取CSV文件时出现‘utf-8'codeccan'tdecodebyte0xd5inposition0:invalidcontinuationbyte解决方法导入importpandasaspd使用pd.read_csv()读csv文...
使用pandas读取xml文件报错“Unsupportedformat,orcorruptfile:ExpectedBOFrecord;foundb'<?xmlve'”解决办法:转换文件格式,使用excel打开xml文件选择:文件—>另存为---->弹框保存以后,再次用pandas读取对应格式的文件读取即可补充:在jupyter中读取CSV文件时出现‘utf-8'codeccan'tdecodebyte0xd5inposition0:invalidcontinuationbyte解决方法导入importpandasaspd使用pd.read_csv()读csv文...
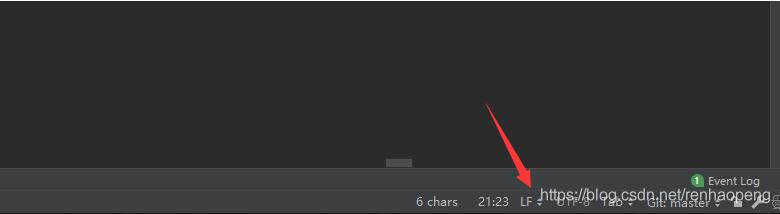 先要明白Fscanf的工作原理Fscanf在遇到\n才结束遇到\r时就会把\r替换成0这就有个问题,要注意自己的文本换行符是什么,在Windows下就是\r\n,在Linux,Mac下就是\n,也就是说这里有个坑,代码在Linux和Mac下读取数据文件是正常的,在Windows下就会遇到各种行末尾有个0,网上办法用什么替换啊,用什么自定义Scan函数啊,太麻烦了,直接使用自带IDE将打开的数据文件集换行符改成LF(Linux,Mac换行符)就行了如下图Idea文件右下角LF点...
先要明白Fscanf的工作原理Fscanf在遇到\n才结束遇到\r时就会把\r替换成0这就有个问题,要注意自己的文本换行符是什么,在Windows下就是\r\n,在Linux,Mac下就是\n,也就是说这里有个坑,代码在Linux和Mac下读取数据文件是正常的,在Windows下就会遇到各种行末尾有个0,网上办法用什么替换啊,用什么自定义Scan函数啊,太麻烦了,直接使用自带IDE将打开的数据文件集换行符改成LF(Linux,Mac换行符)就行了如下图Idea文件右下角LF点...
 本文实例为大家分享了node.js通过url读取文件的具体代码,供大家参考,具体内容如下在浏览器地址栏中输入127.0.0.1:3000和127.0.0.1:3000/node时,读取node.html文件,输入127.0.0.1:3000/banner时读取banner.json文件准备工作首先我们在www的文件目录下新建两个文件,一个是node.htnl,一个是banner.json,并在文件中添加一点内容1、新建01.js文件并导入模块letfs=require("fs");letpath=require("path");lethttp=requir...
本文实例为大家分享了node.js通过url读取文件的具体代码,供大家参考,具体内容如下在浏览器地址栏中输入127.0.0.1:3000和127.0.0.1:3000/node时,读取node.html文件,输入127.0.0.1:3000/banner时读取banner.json文件准备工作首先我们在www的文件目录下新建两个文件,一个是node.htnl,一个是banner.json,并在文件中添加一点内容1、新建01.js文件并导入模块letfs=require("fs");letpath=require("path");lethttp=requir...