
2021
07-22
07-22
Pytorch dataloader在加载最后一个batch时卡死的解决
问题:自己写了个dataloader,为了部署方便,用OpenCV的接口进行数据读取,而没有用PIL,代码大致如下:def__getitem__(self,idx):sample=self.samples[idx]img=cv2.imread(sample[0])img=cv2.resize(img,tuple(self.input_size))img=cv2.cvtColor(img,cv2.COLOR_BGR2RGB)#ifnotself.valandrandom.randint(1,10)<3:#img=self.img_aug(img)...
继续阅读 >
 Pytorch测试神经网络时出现“RuntimeError:Error(s)inloadingstate_dictforNet”解决方法:load_state_dict(torch.load('net.pth')在前,增加model=nn.DataParallel(model)就可以了。比如net=NET()net.cuda()net=nn.DataParallel(net)net.load_state_dict(torch.load('net.pth')补充:解决RuntimeError:Error(s)inloadingstate_dictforXXXX在运行代码时遇到了这个错误,显示错误对应代码中的state_dict,找到对...
Pytorch测试神经网络时出现“RuntimeError:Error(s)inloadingstate_dictforNet”解决方法:load_state_dict(torch.load('net.pth')在前,增加model=nn.DataParallel(model)就可以了。比如net=NET()net.cuda()net=nn.DataParallel(net)net.load_state_dict(torch.load('net.pth')补充:解决RuntimeError:Error(s)inloadingstate_dictforXXXX在运行代码时遇到了这个错误,显示错误对应代码中的state_dict,找到对...
 使用pytorch时所遇到的问题总结1、ubuntuvscode切换虚拟环境在ubuntu系统上,配置工作区文件夹所使用的虚拟环境。之前笔者误以为只需要在vscode内置的终端上将虚拟环境切换过来即可,后来发现得通过配置vscode的解释器(interpreter)具体方法如下:选中需要配置的文件夹,然后点击vscode左下角的写有“Python***”的位置(或者使用快捷键“ctrl+shift+p”)--》选择文件夹--》从解释器列表中选择要用的解释器。完成设置后,会在...
使用pytorch时所遇到的问题总结1、ubuntuvscode切换虚拟环境在ubuntu系统上,配置工作区文件夹所使用的虚拟环境。之前笔者误以为只需要在vscode内置的终端上将虚拟环境切换过来即可,后来发现得通过配置vscode的解释器(interpreter)具体方法如下:选中需要配置的文件夹,然后点击vscode左下角的写有“Python***”的位置(或者使用快捷键“ctrl+shift+p”)--》选择文件夹--》从解释器列表中选择要用的解释器。完成设置后,会在...
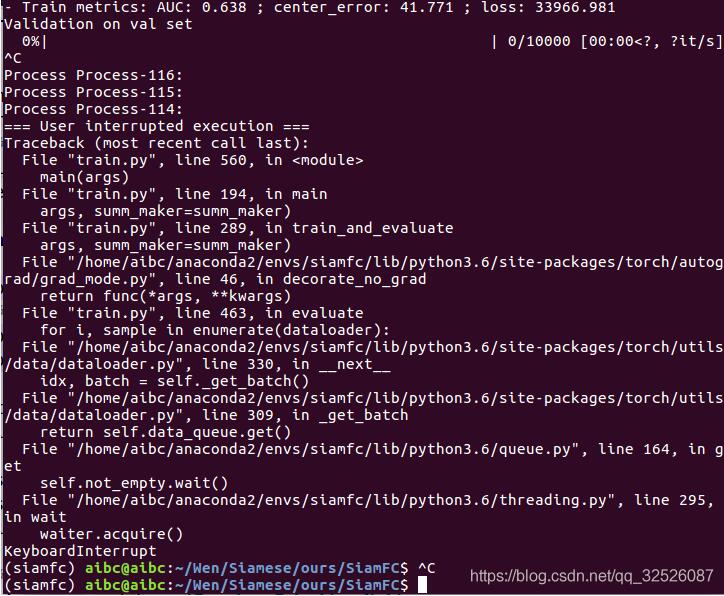 1.问题描述2.解决方案(1)Dataloader里面不用cv2.imread进行读取图片,用cv2.imread还会带来一系列的不方便,比如不能结合torchvision进行数据增强,所以最好用PIL里面的Image.open来读图片。(并不适用本例)(2)将DataLoader里面的参变量num_workers设置为0,但会导致数据的读取很慢,拖慢整个模型的训练。(并不适用本例)(3)如果用了cv2.imread,不想改代码的,那就加两条语句,来关闭Opencv的多线程:cv2.setNumThreads...
1.问题描述2.解决方案(1)Dataloader里面不用cv2.imread进行读取图片,用cv2.imread还会带来一系列的不方便,比如不能结合torchvision进行数据增强,所以最好用PIL里面的Image.open来读图片。(并不适用本例)(2)将DataLoader里面的参变量num_workers设置为0,但会导致数据的读取很慢,拖慢整个模型的训练。(并不适用本例)(3)如果用了cv2.imread,不想改代码的,那就加两条语句,来关闭Opencv的多线程:cv2.setNumThreads...
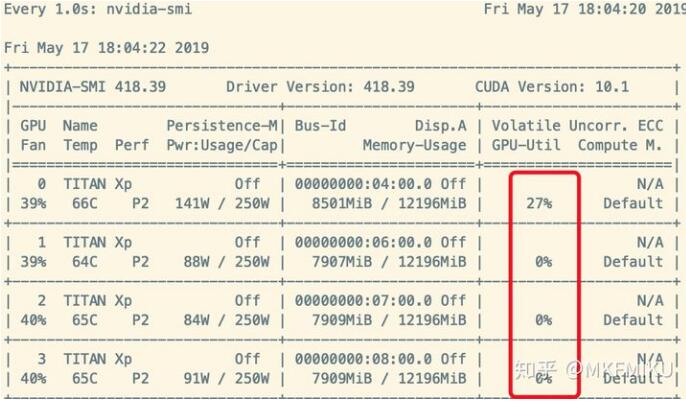 在利用DL解决图像问题时,影响训练效率最大的有时候是GPU,有时候也可能是CPU和你的磁盘。很多设计不当的任务,在训练神经网络的时候,大部分时间都是在从磁盘中读取数据,而不是做Backpropagation。这种症状的体现是使用Nividia-smi查看GPU使用率时,Memory-Usage占用率很高,但是GPU-Util时常为0%,如下图所示:如何解决这种问题呢?在Nvidia提出的分布式框架Apex里面,我们在源码里面找到了一个简单的解决方案:...
在利用DL解决图像问题时,影响训练效率最大的有时候是GPU,有时候也可能是CPU和你的磁盘。很多设计不当的任务,在训练神经网络的时候,大部分时间都是在从磁盘中读取数据,而不是做Backpropagation。这种症状的体现是使用Nividia-smi查看GPU使用率时,Memory-Usage占用率很高,但是GPU-Util时常为0%,如下图所示:如何解决这种问题呢?在Nvidia提出的分布式框架Apex里面,我们在源码里面找到了一个简单的解决方案:...
 1.训练集&验证集&测试集训练集:训练数据验证集:验证不同算法(比如利用网格搜索对超参数进行调整等),检验哪种更有效测试集:正确评估分类器的性能正常流程:验证集会记录每个时间戳的参数,在加载test数据前会加载那个最好的参数,再来评估。比方说训练完6000个epoch后,发现在第3520个epoch的validation表现最好,测试时会加载第3520个epoch的参数。importtorchimporttorch.nnasnnimporttorch.nn.functionalasFimpo...
1.训练集&验证集&测试集训练集:训练数据验证集:验证不同算法(比如利用网格搜索对超参数进行调整等),检验哪种更有效测试集:正确评估分类器的性能正常流程:验证集会记录每个时间戳的参数,在加载test数据前会加载那个最好的参数,再来评估。比方说训练完6000个epoch后,发现在第3520个epoch的validation表现最好,测试时会加载第3520个epoch的参数。importtorchimporttorch.nnasnnimporttorch.nn.functionalasFimpo...
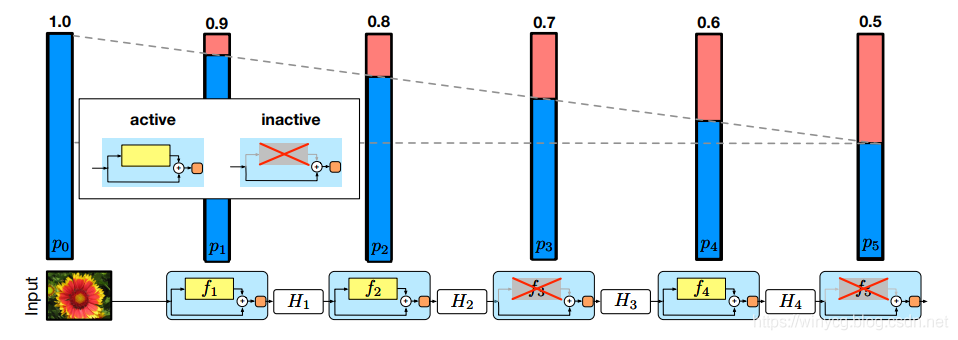 StochasticDepth论文:DeepNetworkswithStochasticDepth本文的正则化针对于ResNet中的残差结构,类似于dropout的原理,训练时对模块进行随机的删除,从而提升模型的泛化能力。对于上述的ResNet网络,模块越在后面被drop掉的概率越大。作者直觉上认为前期提取的低阶特征会被用于后面的层。第一个模块保留的概率为1,之后保留概率随着深度线性递减。对一个模块的drop函数可以采用如下的方式实现:defdrop_connect(inputs,p,t...
StochasticDepth论文:DeepNetworkswithStochasticDepth本文的正则化针对于ResNet中的残差结构,类似于dropout的原理,训练时对模块进行随机的删除,从而提升模型的泛化能力。对于上述的ResNet网络,模块越在后面被drop掉的概率越大。作者直觉上认为前期提取的低阶特征会被用于后面的层。第一个模块保留的概率为1,之后保留概率随着深度线性递减。对一个模块的drop函数可以采用如下的方式实现:defdrop_connect(inputs,p,t...
 了解知道Dropout原理如果要提高神经网络的表达或分类能力,最直接的方法就是采用更深的网络和更多的神经元,复杂的网络也意味着更加容易过拟合。于是就有了Dropout,大部分实验表明其具有一定的防止过拟合的能力。用代码实现DropoutDropout的numpy实现PyTorch中实现dropoutimporttorch.nn.functionalasFimporttorch.nn.initasinitimporttorchfromtorch.autogradimportVariableimportmatplotlib.pyplotaspltimport...
了解知道Dropout原理如果要提高神经网络的表达或分类能力,最直接的方法就是采用更深的网络和更多的神经元,复杂的网络也意味着更加容易过拟合。于是就有了Dropout,大部分实验表明其具有一定的防止过拟合的能力。用代码实现DropoutDropout的numpy实现PyTorch中实现dropoutimporttorch.nn.functionalasFimporttorch.nn.initasinitimporttorchfromtorch.autogradimportVariableimportmatplotlib.pyplotaspltimport...
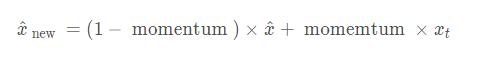 1.注意momentum的定义Pytorch中的BN层的动量平滑和常见的动量法计算方式是相反的,默认的momentum=0.1BN层里的表达式为:其中γ和β是可以学习的参数。在Pytorch中,BN层的类的参数有:CLASStorch.nn.BatchNorm2d(num_features,eps=1e-05,momentum=0.1,affine=True,track_running_stats=True)每个参数具体含义参见文档,需要注意的是,affine定义了BN层的参数γ和β是否是可学习的(不可学习默认是常数1和0).2.注意BN层中含...
1.注意momentum的定义Pytorch中的BN层的动量平滑和常见的动量法计算方式是相反的,默认的momentum=0.1BN层里的表达式为:其中γ和β是可以学习的参数。在Pytorch中,BN层的类的参数有:CLASStorch.nn.BatchNorm2d(num_features,eps=1e-05,momentum=0.1,affine=True,track_running_stats=True)每个参数具体含义参见文档,需要注意的是,affine定义了BN层的参数γ和β是否是可学习的(不可学习默认是常数1和0).2.注意BN层中含...
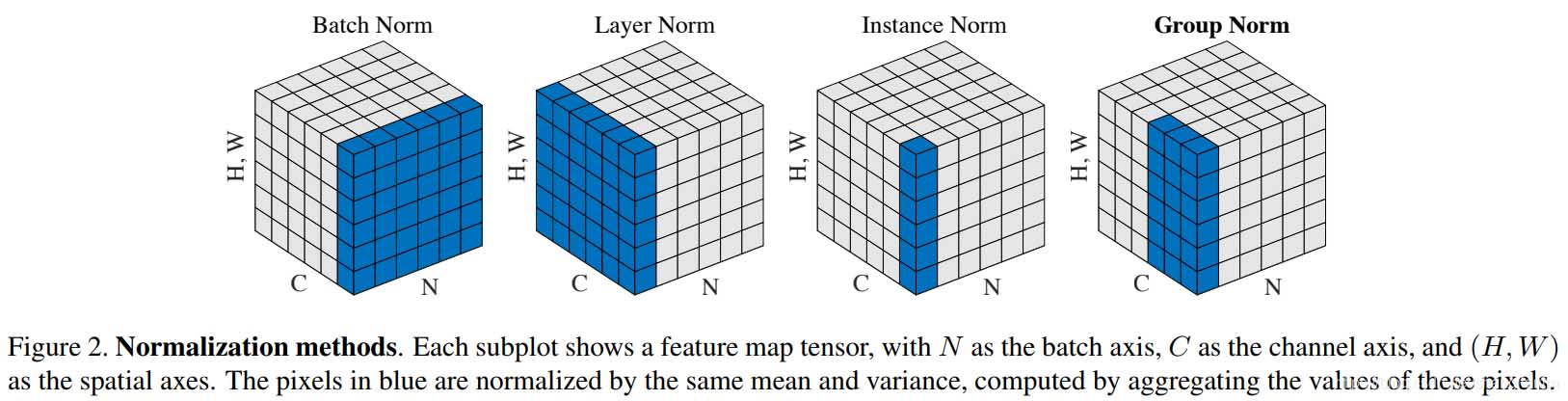 主要就是了解一下pytorch中的使用layernorm这种归一化之后的数据变化,以及数据使用relu,prelu,leakyrelu之后的变化。importtorchimporttorch.nnasnnimporttorch.nn.functionalasFclassmodel(nn.Module):def__init__(self):super(model,self).__init__()self.LN=nn.LayerNorm(10,eps=0,elementwise_affine=True)self.PRelu=nn.PReLU(init=0.25)self.Relu=nn.ReLU()self.L...
主要就是了解一下pytorch中的使用layernorm这种归一化之后的数据变化,以及数据使用relu,prelu,leakyrelu之后的变化。importtorchimporttorch.nnasnnimporttorch.nn.functionalasFclassmodel(nn.Module):def__init__(self):super(model,self).__init__()self.LN=nn.LayerNorm(10,eps=0,elementwise_affine=True)self.PRelu=nn.PReLU(init=0.25)self.Relu=nn.ReLU()self.L...
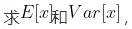 说明LayerNorm中不会像BatchNorm那样跟踪统计全局的均值方差,因此train()和eval()对LayerNorm没有影响。LayerNorm参数torch.nn.LayerNorm(normalized_shape:Union[int,List[int],torch.Size],eps:float=1e-05,elementwise_affine:bool=True)normalized_shape如果传入整数,比如4,则被看做只有一个整数的list,此时LayerNorm会对输入的最后一维进行归一化,这个int值需要和输入的最后一维一样大...
说明LayerNorm中不会像BatchNorm那样跟踪统计全局的均值方差,因此train()和eval()对LayerNorm没有影响。LayerNorm参数torch.nn.LayerNorm(normalized_shape:Union[int,List[int],torch.Size],eps:float=1e-05,elementwise_affine:bool=True)normalized_shape如果传入整数,比如4,则被看做只有一个整数的list,此时LayerNorm会对输入的最后一维进行归一化,这个int值需要和输入的最后一维一样大...