
2021
11-09
11-09
scrapy+flask+html打造搜索引擎的示例代码
 目录1.预备知识2.抓取CSDN数据接口2.1查看CSDN搜索引擎主页2.2测试CSDN搜索引擎的功能2.3查看更多相关文章的信息2.4抓取ajax异步请求数据2.5分析url地址3.使用scrapy爬取CSDN数据接口3.1start_requests3.2使用parse函数提取数据3.3保存成CSV文件3.4运行结果4.效果展示4.1flask后端展示4.2效果展示1.预备知识python语言,scrapy爬虫基础,json模块,flask后端2.抓取CSDN数据接口使用谷歌抓包工具抓取CSDN搜索引擎的接口2.1...
继续阅读 >
目录1.预备知识2.抓取CSDN数据接口2.1查看CSDN搜索引擎主页2.2测试CSDN搜索引擎的功能2.3查看更多相关文章的信息2.4抓取ajax异步请求数据2.5分析url地址3.使用scrapy爬取CSDN数据接口3.1start_requests3.2使用parse函数提取数据3.3保存成CSV文件3.4运行结果4.效果展示4.1flask后端展示4.2效果展示1.预备知识python语言,scrapy爬虫基础,json模块,flask后端2.抓取CSDN数据接口使用谷歌抓包工具抓取CSDN搜索引擎的接口2.1...
继续阅读 >
 scrapy框架概述:Scrapy,Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。创建项目由于pycharm不能直接创建scrapy项目,必须通过命令行创建,所以相关操作在pycharm的终端进行:1、安装scrapy模块:pipinstall-ihttps://pypi.tuna.tsinghua.edu.cn/simplescrapy2、创建一个scrapy项目:scrapystartprojecttest_scra...
scrapy框架概述:Scrapy,Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。创建项目由于pycharm不能直接创建scrapy项目,必须通过命令行创建,所以相关操作在pycharm的终端进行:1、安装scrapy模块:pipinstall-ihttps://pypi.tuna.tsinghua.edu.cn/simplescrapy2、创建一个scrapy项目:scrapystartprojecttest_scra...
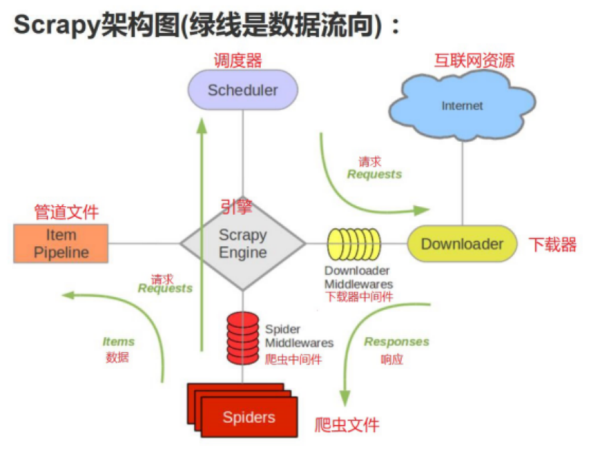 scrapy框架结构思考scrapy为什么是框架而不是库?scrapy是如何工作的?项目结构在开始爬取之前,必须创建一个新的Scrapy项目。进入您打算存储代码的目录中,运行下列命令:注意:创建项目时,会在当前目录下新建爬虫项目的目录。这些文件分别是:scrapy.cfg:项目的配置文件quotes/:该项目的python模块。之后您将在此加入代码quotes/items.py:项目中的item文件quotes/middlewares.py:爬虫中间件、下载...
scrapy框架结构思考scrapy为什么是框架而不是库?scrapy是如何工作的?项目结构在开始爬取之前,必须创建一个新的Scrapy项目。进入您打算存储代码的目录中,运行下列命令:注意:创建项目时,会在当前目录下新建爬虫项目的目录。这些文件分别是:scrapy.cfg:项目的配置文件quotes/:该项目的python模块。之后您将在此加入代码quotes/items.py:项目中的item文件quotes/middlewares.py:爬虫中间件、下载...
 使用Scrapy爬取豆瓣某影星的所有个人图片以莫妮卡·贝鲁奇为例1.首先我们在命令行进入到我们要创建的目录,输入scrapystartprojectbanciyuan创建scrapy项目创建的项目结构如下2.为了方便使用pycharm执行scrapy项目,新建main.pyfromscrapyimportcmdlinecmdline.execute("scrapycrawlbanciyuan".split())再editconfiguration然后进行如下设置,设置后之后就能通过运行main.py运行scrapy项目了3.分析该HTML页面,创建对应s...
使用Scrapy爬取豆瓣某影星的所有个人图片以莫妮卡·贝鲁奇为例1.首先我们在命令行进入到我们要创建的目录,输入scrapystartprojectbanciyuan创建scrapy项目创建的项目结构如下2.为了方便使用pycharm执行scrapy项目,新建main.pyfromscrapyimportcmdlinecmdline.execute("scrapycrawlbanciyuan".split())再editconfiguration然后进行如下设置,设置后之后就能通过运行main.py运行scrapy项目了3.分析该HTML页面,创建对应s...
 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值。但是通过观察我们会发现,通过浏览器进行url请求发送则会加载出对应的动态加载出的数据。那么如果我们想要在scrapy也获取动态加载出的数据,则必须使用selenium创建浏览器对象,然后通过该浏览器对象进行请求发送,获取动态加载的数据值。本文重点给大家介绍sele...
在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值。但是通过观察我们会发现,通过浏览器进行url请求发送则会加载出对应的动态加载出的数据。那么如果我们想要在scrapy也获取动态加载出的数据,则必须使用selenium创建浏览器对象,然后通过该浏览器对象进行请求发送,获取动态加载的数据值。本文重点给大家介绍sele...
 一般创建了scrapy文件夹后,可能需要写多个爬虫,如果想让它们同时运行而不是顺次运行的话,得怎么做?a、在spiders目录的同级目录下创建一个commands目录,并在该目录中创建一个crawlall.py,将scrapy源代码里的commands文件夹里的crawl.py源码复制过来,只修改run()方法即可!importosfromscrapy.commandsimportScrapyCommandfromscrapy.utils.confimportarglist_to_dictfromscrapy.utils.pythonimportwithout_none_va...
一般创建了scrapy文件夹后,可能需要写多个爬虫,如果想让它们同时运行而不是顺次运行的话,得怎么做?a、在spiders目录的同级目录下创建一个commands目录,并在该目录中创建一个crawlall.py,将scrapy源代码里的commands文件夹里的crawl.py源码复制过来,只修改run()方法即可!importosfromscrapy.commandsimportScrapyCommandfromscrapy.utils.confimportarglist_to_dictfromscrapy.utils.pythonimportwithout_none_va...
 简单实现ip代理,为了不卖广告,请自行准备一个ip代理的平台例如我用的这个平台,每次提取10个ip从上面可以看到数据格式是文本,换行是\r\n,访问链接之后大概就是长这样的,scrapy里面的ip需要加上前缀http://例如:http://117.95.41.21:34854OK,那现在已经准备好了ip了,先给你们屡一下思路。ip池和计数器放在setting文件第一次请求的时候要填满ip池,所以在爬虫文件的start_requests函数下手更换ip的地方是middlewares的下载器中间...
简单实现ip代理,为了不卖广告,请自行准备一个ip代理的平台例如我用的这个平台,每次提取10个ip从上面可以看到数据格式是文本,换行是\r\n,访问链接之后大概就是长这样的,scrapy里面的ip需要加上前缀http://例如:http://117.95.41.21:34854OK,那现在已经准备好了ip了,先给你们屡一下思路。ip池和计数器放在setting文件第一次请求的时候要填满ip池,所以在爬虫文件的start_requests函数下手更换ip的地方是middlewares的下载器中间...
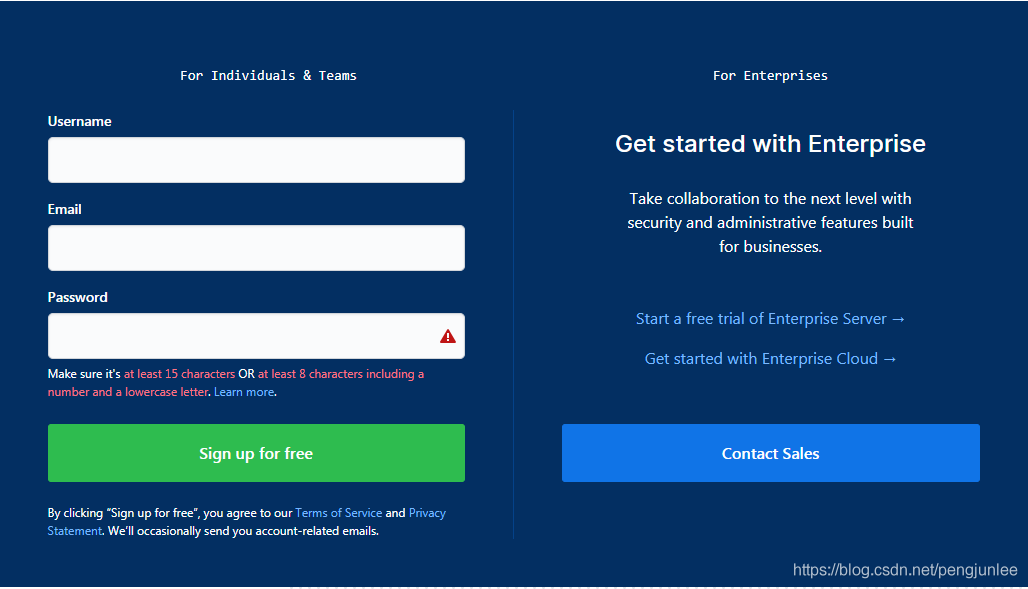 为什么要模拟登录有些网站是需要登录之后才能访问的,即便是同一个网站,在用户登录前后页面所展示的内容也可能会大不相同,例如,未登录时访问Github首页将会是以下的注册页面:然而,登录后访问Github首页将包含如下页面内容:如果我们要爬取的是一些需要登录之后才能访问的页面数据就需要模拟登录了。通常我们都是利用的Cookies来实现模拟登录,在Scrapy中,模拟登陆网站一般有如下两种实现方式: ...
为什么要模拟登录有些网站是需要登录之后才能访问的,即便是同一个网站,在用户登录前后页面所展示的内容也可能会大不相同,例如,未登录时访问Github首页将会是以下的注册页面:然而,登录后访问Github首页将包含如下页面内容:如果我们要爬取的是一些需要登录之后才能访问的页面数据就需要模拟登录了。通常我们都是利用的Cookies来实现模拟登录,在Scrapy中,模拟登陆网站一般有如下两种实现方式: ...
 此货很干,跟上脚步!!!Cookiecookie是什么东西?小饼干?能吃吗?简单来说就是你第一次用账号密码访问服务器服务器在你本机硬盘上设置一个身份识别的会员卡(cookie)下次再去访问的时候只要亮一下你的卡片(cookie)服务器就会知道是你来了,因为你的账号密码等信息已经刻在了会员卡上需求分析爬虫要访问一些私人的数据就需要用cookie进行伪装想要得到cookie就得先登录,爬虫可以通过表单请求将账号密码提交上去但是在火狐的F12...
此货很干,跟上脚步!!!Cookiecookie是什么东西?小饼干?能吃吗?简单来说就是你第一次用账号密码访问服务器服务器在你本机硬盘上设置一个身份识别的会员卡(cookie)下次再去访问的时候只要亮一下你的卡片(cookie)服务器就会知道是你来了,因为你的账号密码等信息已经刻在了会员卡上需求分析爬虫要访问一些私人的数据就需要用cookie进行伪装想要得到cookie就得先登录,爬虫可以通过表单请求将账号密码提交上去但是在火狐的F12...
 下载代码Cookie池(这里主要是微博登录,也可以自己配置置其他的站点网址)下载代码GitHub:https://github.com/Python3WebSpider/CookiesPool下载安装过后注意看网页下面的相关基础配置和操作!!!!!!!!!!!!!自己的设置主要有下面几步:1、配置其他设置2、设置使用的浏览器3、设置模拟登陆源码cookies.py的修改(以下两处不修改可能会产生bug): 4、获取cookie随机获取Cookies: http://localhost:5000/wei...
下载代码Cookie池(这里主要是微博登录,也可以自己配置置其他的站点网址)下载代码GitHub:https://github.com/Python3WebSpider/CookiesPool下载安装过后注意看网页下面的相关基础配置和操作!!!!!!!!!!!!!自己的设置主要有下面几步:1、配置其他设置2、设置使用的浏览器3、设置模拟登陆源码cookies.py的修改(以下两处不修改可能会产生bug): 4、获取cookie随机获取Cookies: http://localhost:5000/wei...